Audio Classification
Speech Recognition
Speech To Text
Tìm hiểu bài toán Automatic Speech Recognition (ASR)
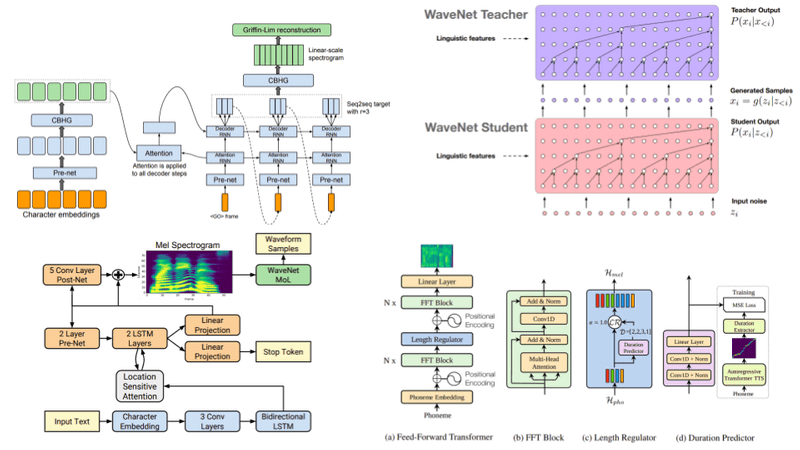
Đây là bài cuối cùng trong chuỗi 6 bài về Audio Deep Learning. Trong bài này, chúng ta sẽ tổng hợp lại các kiến trúc mô hình DL để giải quyết bài toán Speech Synthesis.
read more