Audio Data Preparation - Một số kỹ thuật nâng cao
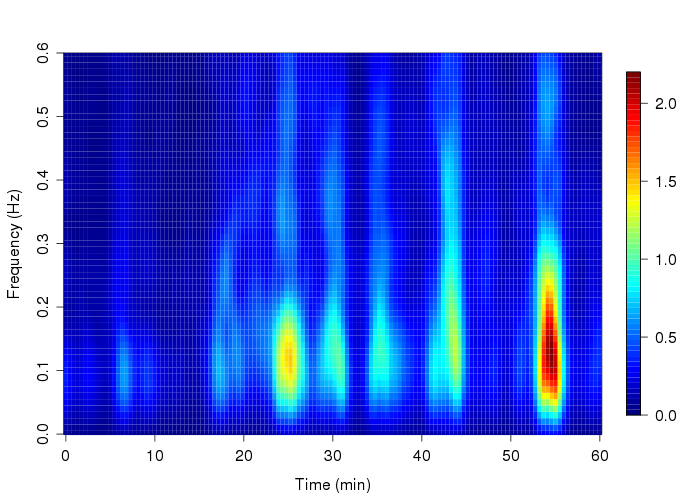
Đây là bài thứ 3 trong chuỗi 5 bài về Audio Deep Learning. Trong bài này, chúng ta sẽ tiến thêm một bước sâu hơn là tìm cách nâng cao chất lượng của Mel Spectrogram thông qua tinh chỉnh các Hyper-parameters của nó. Đồng thời, chúng ta cũng sẽ tìm hiểu một số kỹ thuật làm giàu dữ liệu Audio. Cả 2 vấn đề này đều quan trọng, góp phần nâng cao hiệu quả của các Deep Learning model.
1. Spectrograms Optimization with Hyper-parameter tuning
Ở bài trước, chúng ta đã tìm hiểu về Mel Spectrogram và cách tạo ra nó sử dụng thư viện libsora. Thực chất, để tạo ra được Mel Spectrogram, chúng ta cần phải chỉ ra một số tham số cho nó. Nếu không được cung cấp, các giá trị mặc định sẽ được sử dụng. Để tạo ra được Mel Spectrogram thực sự tốt cho Deep Learning model, chúng ta cần điều chỉnh các tham số này tùy theo từng loại dữ liệu.
Trước hết, chúng ta cần hiểu một số khái niệm sau:
1.1 Discrete Fourier Transform (DFT) và Fast Fourier Transform (FFT)
DFT và FFT là 2 cách để tính toán FFT. Sử dụng DFT thường mất nhiều thời gian hơn nên trong thực tế, FFT được sử dụng nhiều hơn. Về bản chất, FFT là một biến đổi khác của DFT.
Sử dụng FFT tuy nhanh nhưng nó lại chỉ đưa ra một cách khái quát về tất cả các thành phần tần số có trong toàn bộ chuỗi thời gian của Audio. Nó không chỉ ra được cách mà các thành phần tần số thay đổi như thế nào theo thời gian.
1.2 Short-time Fourier Transform (STFT)
Để có được thông tin về sự biến đổi của các thành phần tần số qua thời gian, chúng ta phải sử dụng thuật toán Short-time Fourier Transform (STFT). STFT là một biến thể của Fourier Transform mà ở đó, các Audio Signal được chia nhỏ thành các phần bằng nhau, sử dụng Sliding Time window và Sliding Frequency window. Sau đó, áp dụng FFT trên mỗi phần đó rồi kết hợp các kết quả lại với nhau thành một kết quả cuối cùng. Cách làm này cho phép STFT có khả năng lấy được thông tin về sự thay đổi của các thành phần tần số theo thời gian.
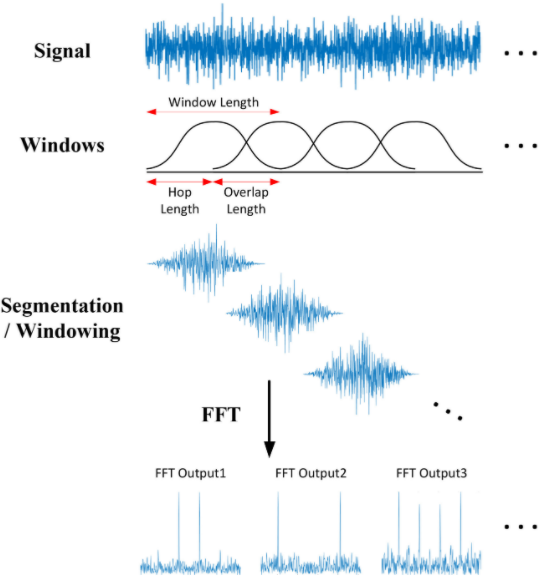
Ví dụ, ta có một Audio Signal có độ dài 1 phút chứa các tần số từ 0Hz đến 10000Hz (theo Mel Scale). Thuật toán STFT để tạo ra Mel Spectrogram sẽ làm như sau:
- Chọn kích thước của Time-Window là 3s, ta có 20 Time-Sections.
- Chia khoảng tần số thành 10 bands: 0-1000Hz, 1000-2000Hz, …, 9000-10000Hz.
Kết quả ta thu được một màng 2D Numpy có kích thước (10,20), ở đó:
- Mỗi cột đại diện cho STFT của một Time-Section.
- Mỗi hàng đại diện cho giá trị của biên độ trong một Band.
Mỗi hàng/cột ở đây tương ứng với mỗi hàng/cột của Mel Spectrogram.
Thử in ra Type và Shape của Mel Spectrogram:
#Spectrogram is a 2D numpy array
print(type(mel_sgram), mel_sgram.shape)
# <class 'numpy.ndarray'> (128, 194)
Ta thấy Mel Spectrogram là một Numpy Array có kích thước (128, 194).
1.3 Mel Spectrogram Hyperparameters
Dưới đây là danh sách các Hyperparameters của Mel Spectrogram được sử dụng trong thư viện librosa (các thư viện khác cũng có các hyperparameters tương tự):
-
Frequency Bands:
- fmin: tần số nhỏ nhất
- fmax: tần số lớn nhất
- n_mels: số lượng Frequency Bands, hay chiều cao của Mel Spectrogram.
-
Time Sections
- n_fft: kích thước Time-Window, hay chiều dài mỗi Time-Section.
- hop_length: Có thể hiểu nó tương tự như Stride trong CNN, tức là số bước trượt/nhảy tính theo đơn vị Hop của Time-Window (xem hình minh họa bên trên)
Các tham số này có thể điều chỉnh được và chúng ta nên điều chỉnh nó tùy theo từng bộ dữ liệu để có kết quả tốt nhất.
2. Mel Frequency Cepstral Coeficients (MFCC)
MFCC là một dạng thể hiện khác của Audio Data, được biến đổi từ Mel Spectrogram. Cụ thể MFCC nén các Frequency Bands từ Mel Spectrogram tương ứng với các mức tần số thông thường của giọng nói con người. Chính vì thê mà Mel Spectrogram phù hợp với đa số các loại Audio, còn MFFC thì phù hợp hơn với âm thanh phát ra từ miệng chúng ta.
import sklearn
import librosa
import librosa.display
# Load the audio file
AUDIO_FILE = './7061-6-0-0.wav'
samples, sample_rate = librosa.load(AUDIO_FILE, sr=None)
mfcc = librosa.feature.mfcc(samples, sr=sample_rate)
# Center MFCC coefficient dimensions to the mean and unit variance
mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
librosa.display.specshow(mfcc, sr=sample_rate, x_axis='time')
print (f'MFCC is of type {type(mfcc)} with shape {mfcc.shape}')
# MFCC is of type <class 'numpy.ndarray'> with shape (20, 194)
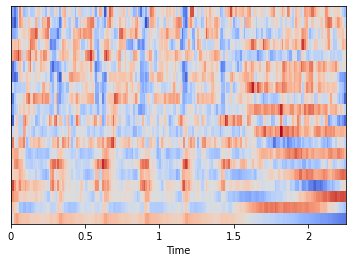
Ta thấy, Mel Spectrogram có kích thước (128,194), còn MFFC có kích thước (20, 194).
3. Audio Data Augmentation
Chúng ta đã không còn xa lạ với khái niệm Data Augmentaion và lợi ích của nó trong các bài toán CV, NLP. Đối với Auio, chúng ta cũng làm tương tự. Có thể áp dụng Augmentaion đối với Raw Audio hoặc Mel Spectrogram.
3.1 Spectrogram Augmentation
Các phép biến đổi của Image khong thể áp dụng trực tiếp vào cho Mel Spectrogram được vì nó sẽ biến đổi hoàn toàn Sound Signal, tạo ra các Sound Signal mới hoàn toàn. Thay vào đó, chúng ta sẽ sử dụng phương pháp SpecAugment với 2 kỹ thuật chính:
- Frequency Masks: Ngẫu nhiên Mask một khoảng liên tục của Frequency ngang theo trục X.
- Time Masks: Ngẫu nhiên Mask một khoảng liên tục của Time dọc theo trục Y.
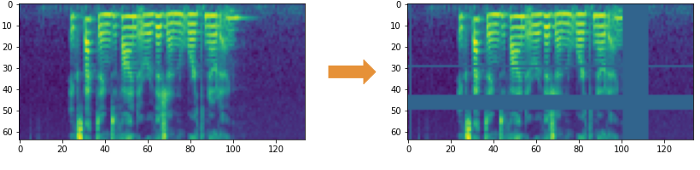
3.2 Raw Audio Augmentation
Một số kỹ thuật:
-
Time Shift: dịch chuyển Audio sang trái/phải một đoạn ngẫu nhiên
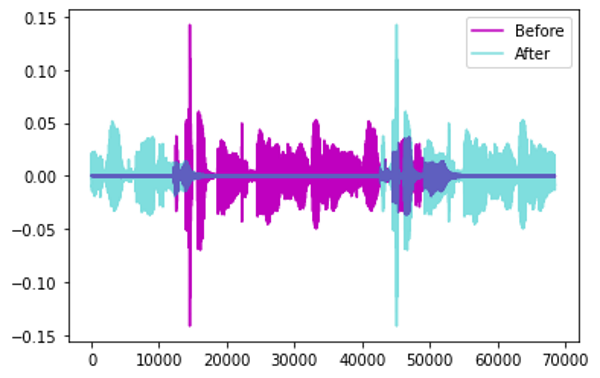
-
Pitch Shift: Thay đổi ngẫu nhiên các tần số thành phần của Audio
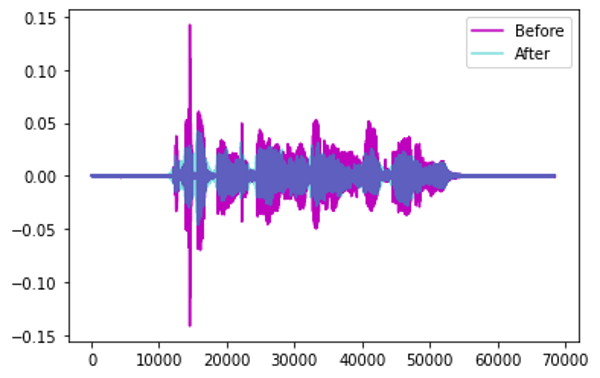
-
Time Stretch: Tăng/giảm tốc độ của âm thanh một cách ngẫu nhiên.
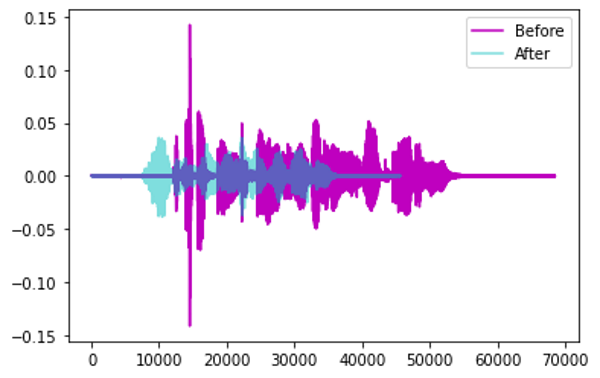
-
Add Noise: Thêm nhiễu ngẫu nhiên vào Audio
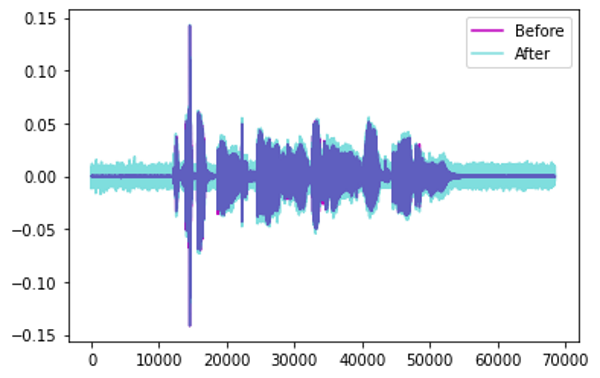
4. Kết luận
Bài thứ ba trong chuỗi các bài viết về Audio Deep Learning này, chúng ta biết thêm về một số Hyperparameters của Mel Spectrogram cần tune để thu được kết quả tốt nhất. Chúng ta cũng biết MFFC là gì và khi nào thì sử dụng nó. Cuối cùng, chúng ta biết các phương pháp, kỹ thuật để tăng cường dữ liệu Audio, giúp Deep Learning models có thể học được tốt hơn.
Source code bài này mình để ở đây.
Ở bài tiếp theo, chúng ta sẽ áp dụng những kỹ thuật đã tìm hiểu ngày hôm nay vào bài toán Audio Classification. Mời các bạn đón đọc.
5. Tham khảo
[1] Ketan Doshi, “Audio Deep Learning Made Simple (Part 3): Data Preparation and Augmentation”, Available online: https://towardsdatascience.com/audio-deep-learning-made-simple-part-3-data-preparation-and-augmentation-24c6e1f6b52 (Accessed on 30 May 2021).
[2] Wikipedia, “Discrete Fourier transform”, Available online: https://en.wikipedia.org/wiki/Discrete_Fourier_transform_cepstrum (Accessed on 30 May 2021).
[3] Wikipedia, “Fast Fourier transform”, Available online: https://en.wikipedia.org/wiki/Fast_Fourier_transform (Accessed on 30 May 2021).
[4] Wikipedia, “Short-time Fourier transform”, Available online: https://en.wikipedia.org/wiki/Short-time_Fourier_transform (Accessed on 30 May 2021).
[5] Springer, “MFCC Features”, Available online: https://link.springer.com/content/pdf/bbm%3A978-3-319-49220-9%2F1.pdf (Accessed on 30 May 2021).