Tìm hiểu bài toán Automatic Speech Recognition (ASR)

Đây là bài cuối cùng trong chuỗi 5 bài về Audio Deep Learning. Trong bài này, chúng ta sẽ tìm hiểu về bài toán Automatic Speech Recognition (ASR) hay Speech-to-Text: kiến trúc, cách thức làm việc, …
Có lẽ chúng ta không còn quá xa lạ với một số ứng dụng như Siri, Alexa, Google Home, Cortana, … Chúng đều là các ứng dụng dựa trên bài toán ASR.
1. Speech to Text
Như chúng ta đều biết, tiếng nói của con người là một thứ tồn tại hàng ngày xung quanh chúng ta. Trong một số trường hợp, chúng ta cần phải chuyển đổi những giọng nói đó thành văn bản (transcribe) đề có thể xử lý tốt hơn. Ví dụ: ghi chép nội dụng trong một cuộc họp, tổng đài hỗ trợ tự động, …
Tương tự như bài toán Audio Classification, đối với bài toán Speech-to-Text cũng yêu cầu dữ liệu huấn luyện gồm 2 phần:
- Input Features (X): các đoạn audio thu âm giọng nói của người.
- Target Labels (Y): các đoạn văn bản tương ứng với các đoạn audio X.

ASR model sẽ nhận vào X và đưa ra dự đoán Y.
2. Data Preprocessing
Các bước tiền xử lý dữ liệu của bài toán này cũng tương tự như bài trước.
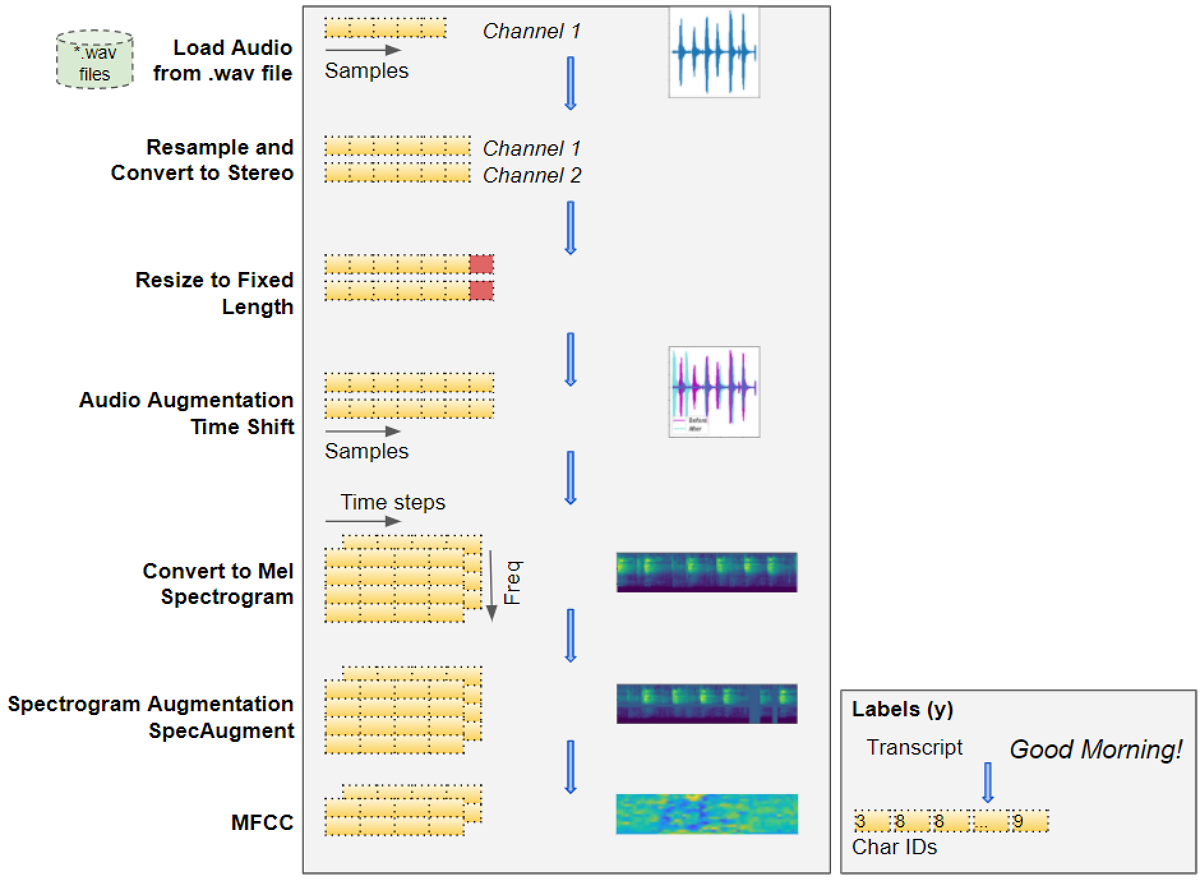
2.1 Load Audio Files
- Input Data là các file audio thu âm giọng nói của người dưới dạng .mp3, .wav, …
- Sử dụng một trong các thư viện Librosa, Torchaudio, … để đọc vào các Input Data, chuyển chúng thành các mảng Numpy 1D. Mỗi giá trị trong mảng này chính là giá trị của biên độ tại các thời điểm lấy mẫu. Kích thước của mảng phụ thuộc vào giá trị của Tần số lấy mẫu (Sampling Rate). Ví dụ: nếu Sampling Rate = 44100Hz, thì cứ mỗi giây sẽ có 44100 giá trị của biên độ được lấy. Nếu file Audio dài 2s thì mảng Numpy của nó sẽ có kích thước là 88200.
2.2 Normalization = Convert to uniform dimensions: sample rate, channels, and duration
- Các Input Data có thể rất khác nhau về độ dài thời gian, số kênh (Mono hoặc Stereo), Sampling Rate, … Điều này dẫn đến kích thước của mảng Numpy cũng sẽ rất khác nhau.
- Bởi vì các DL model đều yêu cầu Input Features có cùng kích thước nên chúng ta phải chuân hóa, sao cho tất cả các Input Data có cùng giá trị của mỗi đại lượng kể trên.
- Nếu chất lượng Input Data quá tệ, có thể xem xét áp dụng một số thuật toán Denoise để loại bớt nhiễu.
2.3 Mel Spectrogram
Mảng Numpy của các file Audio (gọi là Raw Audio) được chuyển sang Mel Spectrogram. Mel Spectrogram chứa đầy đủ thông tin của Audio trong cả miền thời gian và không gian và thể hiện chúng dưới dạng ảnh phổ.
2.4 Data Augmentation
Chúng ta có thể áp dụng một số kỹ thuật Augmentation để làm phong phú thêm dữ liệu huấn luyện model. Có 2 thời điểm thích hợp mà ta có thể sử dụng các kỹ thuật này:
- Thời điểm dữ liệu ở dạng Raw Audio: Một số kỹ thuật là Time Shift, Pitch Shift, Time Stretch.
- Thời điểm dữ liệu ở dạng Mel Spectrogram: Một số kỹ thuật là: Time Mask, Frequency Mask.
2.5 MFCC
MFCC là một dạng “nén” của Mel Spectrogram, được chứng mình rằng phù hợp hơn Mel Spectrogram đối với dữ liệu là giọng nói của người.
2.6 Prepare Target Label
Để chuẩn bị nhãn cho model, chúng ta cần xây dựng một từ điển (Vocabulary) các ký tự trong các Target Labels Y, sau đó chuyển mỗi ký tự đó sang ID tương ứng của chúng trong từ điển.
3. Kiến trúc
Có một vài kiến trúc DL model khác nhau cho ASR, trong đó có 2 kiến trúc phổ biến là:
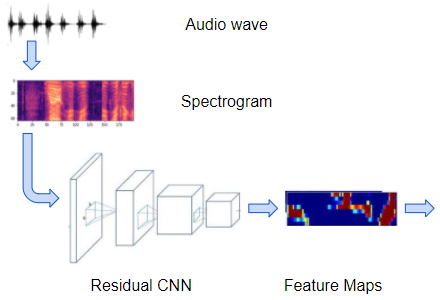
3.1 CRNN-CTC Tương tự như bài toán OCR, kiến trúc này cũng bao gồm một mạng CNN để trích xuất đặc trưng (feature maps) từ MFCC, mạng RCNN để xử lý các Feature Maps dạng chuỗi, và cuối cùng là CTC Loss để decode ra các ký tự cụ thể. Baidu’s Deep Speech là một model nổi bật sử dụng kiến trúc này.
Cách thức hoạt động của nó như sau:
-
Mạng CNN (thường là ResNet) xử lý các MFCC Images và Output ra Feature Maps của mỗi Image đó.
-
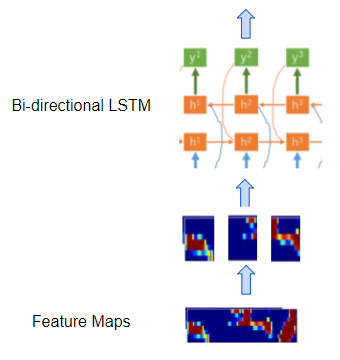
Tiếp theo, mạng RNN (thường là Bidirectional LSTM) xử lý các Feature Maps như là một chuỗi các TimeSteps/Frames liên tiếp, mỗi TimeStep này tương ứng với một/nhiều ký tự ở chuỗi đầu ra mong muốn.
-
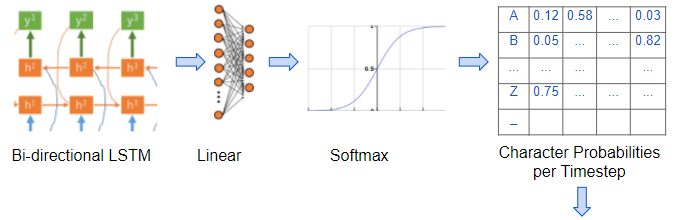
Một Linear Layer kết hợp với Softmax, sử dụng Output từ LSTM để sinh ra xác suất của mỗi ký tự, tương ứng với mỗi TimeStep.
-
Ngoài ra, cũng có thể có một vài Linear Layers khác nằm giữa CNN và RNN để chuyển đổi kích thước giữa 2 mạng cho phù hợp với nhau.
-
CTC Loss: Xem lại bài này
3.2 RNN Kiến trúc này chỉ sử dụng mạng RNN SeqSeq, sử dụng Input là các slices được chia ra từ MFCC. Google’s Listen Attend Spell (LAS) là một model nột bật sử dụng kiến trúc này.
4. Metrics - Word Error Rate (WER)
Sau khi dựng được kiến trúc và huấn luyện model, bước tiếp theo cần làm là đánh giá model đó xem nó hoạt động hiệu quả như thế nào. Mỗi dạng bài toán đều có các Metrics để đánh giá model khác nhau. Đối với bài toán ASR, Word Error Rate (WER) thường được sử dụng. Về bản chất, WER dựa vào việc so sánh kết quả dự đoán của model và nhãn thực tế theo từng ký tự (Character by Character) hoặc từ (Word by Word).
Sự khác nhau giữa kết quả dự đoán và nhãn thực tế có thể là các ký tự/từ có trong nhãn nhưng khồn có trong dự đoán (gọi là Deletion), hoặc ký tự/từ có trong dự đoán nhưng không có trong nhãn (gọi là Insertion), hoặc ký tự/từ có trong dự đoán/nhãn nhưng trong nhãn/dự đoán, nó bị biến đổi thành ký tự/từ khác mà vẫn giữ nguyên ý nghĩa (gọi là Substitution).

Công thức tính WER khá đơn giản, nó là tỉ lệ giữa số lượng các ký tự/từ khác nhau (cả 3 loại) và tổng số ký tự/từ.
Ví dụ, trong hình bên trên thì:
$WER = \frac{Detetion + Insertion + Substitution}{\sum{Characters/Words}} = \frac{1 + 1 + 1}{6} = 0.5$
5. Beam Search
Trong cách làm việc của CTC Decoder, mặc dù không nói rõ nhưng chúng ta đều ngầm hiểu rằng ký tự với xác sủất cao nhất sẽ được chọn. Cách này được gọi bằng cái tên Greedy Search.
Một sự thay thế khác là Beam Seach, mà trong một số trường hợp mang lại kết quả tốt hơn so với Greedy Search, đặc biệt là trong các bài toán NLP. Nếu có thể thì bạn hãy thử nó trong các dự án của mình.
6. Mở rộng
Nói chung, sau khi đánh giá model, WER đã thỏa mãn yêu cầu (> giá trị ngưỡng, 0.8 chẳng hạn) thì bài toán ASR coi như đã được giải quyết xong. ASR mặc dù đã sinh ra văn bản từ giọng nói nhưng nó không hiểu gì về ngữ nghĩa của văn bản đó cả. Kết quả của ASR thường được sử dụng làm Input cho các bài toán khác trong lĩnh vực NLP: sinh văn bản mới, phân loại văn bản, tự động trả lời, …
7. Kết luận
Như vậy là chúng ta đã kết thúc bài thứ 5 tại đây. Qua bài này, chúng ta đã hiểu được phần nào rõ hơn về bài toán ASR, từ kiến trúc cho đến cách làm việc
Trong bài tiếp theo, chúng ta sẽ chuyển sang một chủ đề mới, đó là bài toán Recommender System. Mời các bạn đón đọc.
8. Tham khảo
[1] Ketan Doshi, “Audio Deep Learning Made Simple: Automatic Speech Recognition (ASR), How it Works”, Available online: https://towardsdatascience.com/audio-deep-learning-made-simple-automatic-speech-recognition-asr-how-it-works-716cfce4c706 (Accessed on 05 Jun 2021).
[2] Scott Duda, “Urban Environmental Audio Classification Using Mel Spectrograms”, Available online: https://scottmduda.medium.com/urban-environmental-audio-classification-using-mel-spectrograms-706ee6f8dcc1 (Accessed on 05 Jun 2021).