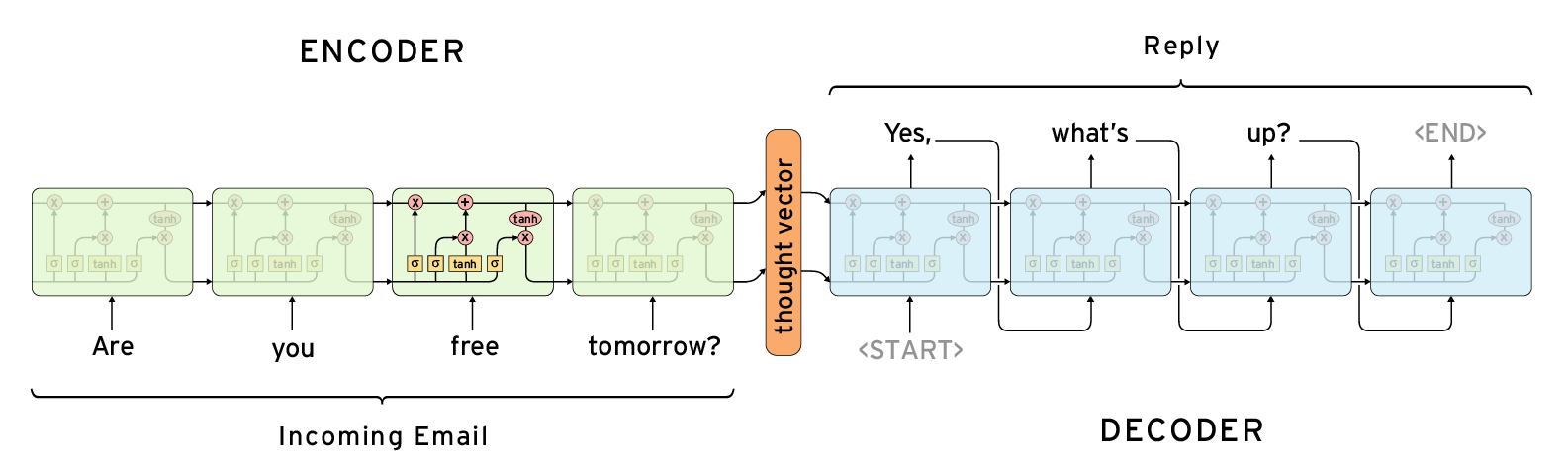
R n n
L s t m
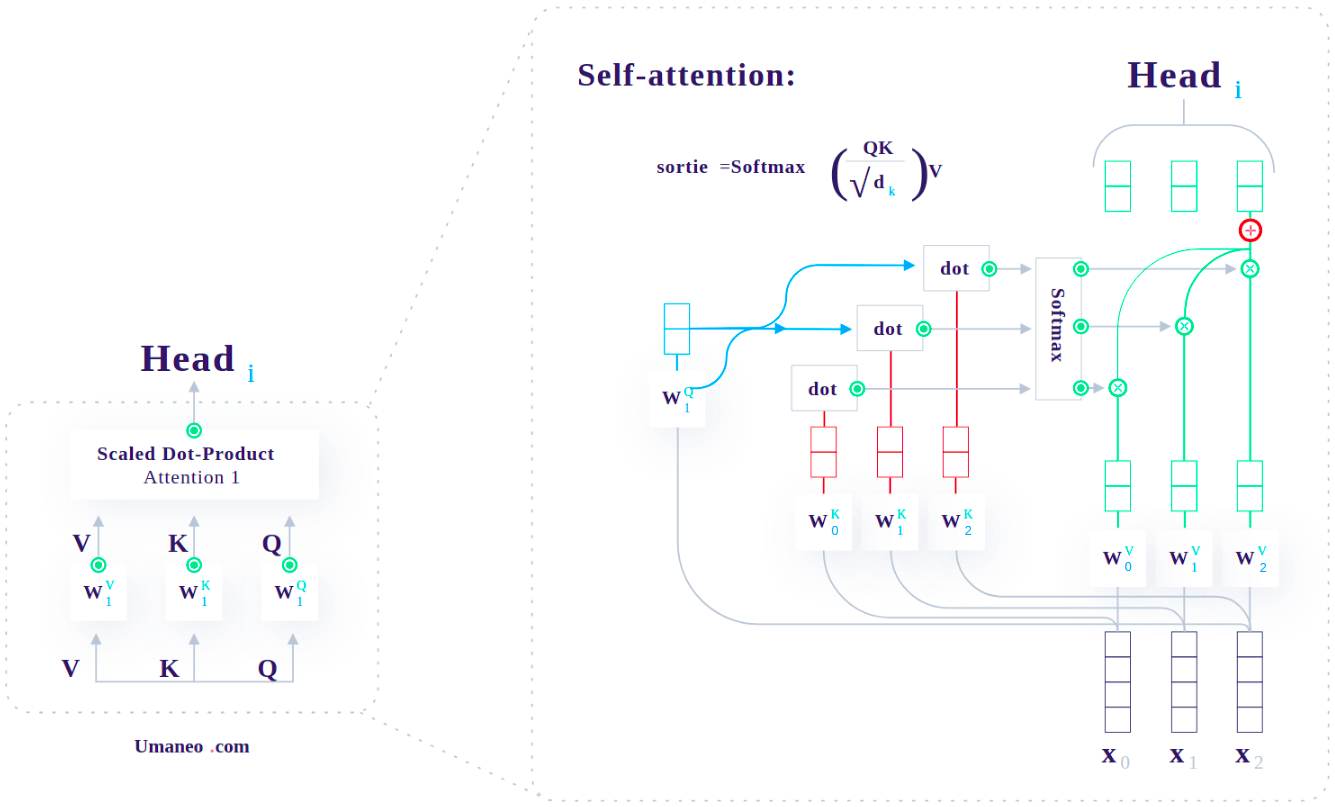
Attention
Transformer
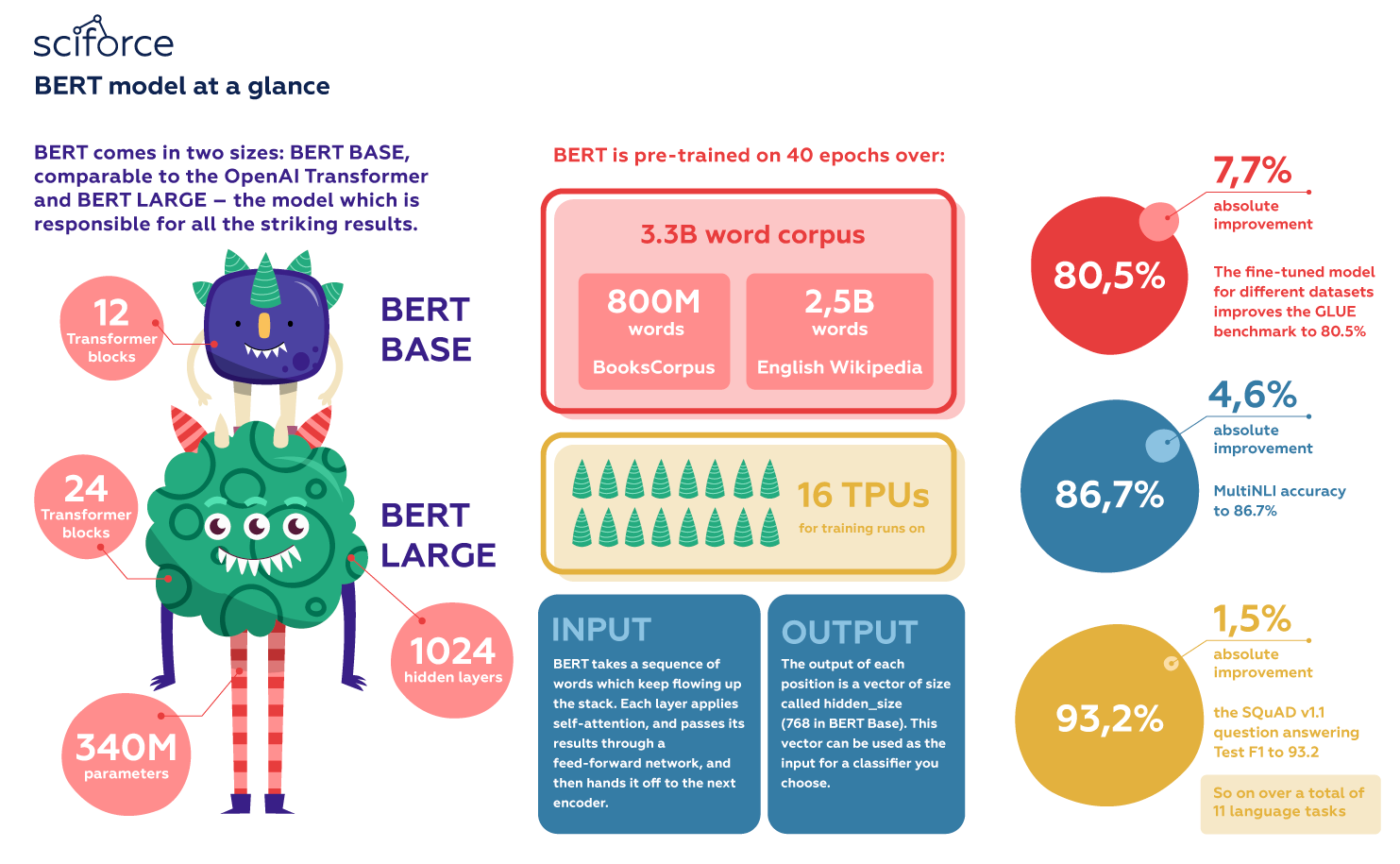
B e r t
BERT - Bidirectional Encoder Representations from Transformers
Cuối năm 2018, các nhà nghiên cứu tại Google AI Language đã công bố một mô hình với tên gọi BERT trong bài báo BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
read more