BERT - Bidirectional Encoder Representations from Transformers
Cuối năm 2018, các nhà nghiên cứu tại Google AI Language đã công bố một mô hình với tên gọi BERT trong bài báo BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Kế thừa kiến trúc của Transformers đã từng công bố trước đó, BERT đạt được hiệu quả rất cao so với các mô hình khác trong các tác vụ của NLP. Từ đó, có rất nhiều phiên bản của BERT ra đời, tập trung giải quyết các bài toán NLP trong từng lĩnh vực, ngôn ngữ cụ thể. Có thể nói Transformers và BERT đã mở ra một kỷ nguyên mới cho lĩnh vực AI nói chung và NLP nói riêng.
Kỹ thuật chính mà BERT sử dụng là sử dụng chỉ phần Encoder Stack của Transformers và áp dụng phương pháp huấn luyện 2 chiều (bidirectional training). Trước đó thì các Language Model thường chỉ huấn luyện 1 chiều (nondirectional training), từ trái qua phải hoặc từ phải qua trái. Các tác giả của bài báo đã chỉ ra rằng, bằng việc sử dụng bidirection training có thể thu được nhiều thông tin về ngữ nghĩa của mỗi từ trong Input Sequence hơn so với nondirectional training.
Trong bài này, chúng ta sẽ cùng tìm hiểu về nó.
1. Tại sao lại cần BERT?
Cũng như trong Computer Vision (*CV) trong những thách thức lớn nhất trong NLP là thiếu dữ liệu đào tạo. Nhìn chung, có rất nhiều dữ liệu văn bản có sẵn, nhưng nếu chúng ta muốn giải quyết các bài toán đặc thù của mình thì chúng ta phải tự tạo các bộ dữ liệu dành riêng cho bài toán đó. Việc đó quả thực mất rất nhiều thời gian. Để giúp thu hẹp khoảng cách về dữ liệu này, các nhà nghiên cứu đã phát triển các kỹ thuật khác nhau để đào tạo các mô hình biểu diễn ngôn ngữ có mục đích chung bằng cách sử dụng vô số văn bản trên các website (Pre-trained model). Sau đó, các mô hình Pre-trained này có thể được tinh chỉnh trên các tập dữ liệu nhỏ hơn dành riêng cho nhiệm vụ cụ thể. Cách tiếp cận này cải thiện độ chính xác lớn rất nhiều so với việc huấn luyện model từ đầu trên các bộ dữ liệu nhỏ. Kỹ thuật này được gọi bằng cái tên Transfer Learning giống như trong CV. BERT là một bổ sung gần đây cho kỹ thuật này trong việc tạo ra các Pre-trained model của NLP. Các Pre-trained BERT model có thể dễ dàng tải về miễn phí, sau đó được sử dụng hoặc là để trích xuất Features từ dữ liệu văn bản như đề cập trong bài báo ELMO, hoặc Fine-tune trên tập dữ liệu riêng của một nhiệm vụ cụ thể.
2. Ý tưởng của BERT
Hãy nói về Language Modeling. Nhiệm vụ của nó là “tìm từ tiếp theo trong câu”. Ví dụ, trong câu sau:
The woman went to the store and bought a ...
Language Modeling có thể hoàn thành việc này bằng cách đưa ra một dự đoán rằng, 80% từ còn thiếu là “bag” và 20% là “water”. Cách làm việc của Language Modeling là nhìn vào Input Sequence từ trái qua phải hoặc từ phải qua trái, gọi là Unidirection, hoặc là từ cả 2 phía, gọi là Bidirection. Các cách tiếp cận này khá hiệu quả đối với bài toán dự đoán từ tiếp theo, như ví dụ trên.
Đến với BERT, nó cũng có thể được coi là một Language Modeling, nhưng cách làm việc của nó có một vài điểm khác với trước đó:
- BERT dựa trên kiến trúc của Transformers, tức là cũng tiếp cận Input Sequence theo cả 2 hướng, nhưng tại cùng một thời điểm (trước đó là lần lượt từ trái qua phải rồi từ phải qua trái, hoặc ngược lại). Cách này có thể gọi là Nondirection. Hơn nữa, việc sử dụng kiến trúc của Tranformers làm cho BERT có thể hiểu ngữ nghĩa của cả câu tốt hơn (xem lại bài viết về Transformers) so với kiến trúc LSTM/GRU.
- Thay vì dự đoán từ tiếp theo, BERT sử dụng một kỹ thuật mới, gọi là Mask LM (MLM). Ý tưởng là “mask” ngẫu nhiên một số từ trong câu và sau đó cố gắng dự đoán chúng.
Để tạo ra Word Embedding, chúng ta có thể sử dụng một trong 2 phương pháp: Context-Free hoặc Context-Based.
- Trong Context-Based - lại được chia thành 3 cách: Unidirection, Bidirection và Nondirection.
- Context-Free- kiểu như Word2Vec hay Glove, sinh ra các Word Embedding dựa hoàn toàn vào từ điển từ (Vocabulary Dictionary).
Ví dụ:
- Từ bank trong câu bank account sẽ có Word Embedding giống hệt với từ bank trong câu bank of the river nếu sử dụng Context-Free.
- Trong câu I accessed the bank account, nếu sử dụng Unidirection thì Word Embedding của từ bank sẽ được sinh ra dựa trên các từ I accessed the. Còn nếu sử dụng Bidirection/Nondirection thì sẽ dựa trên các từ I accessed the … account.
3. Cách làm việc của BERT
Kiến trúc của BERT kế thừa kiến trúc của Transformers. Kiến trúc đầy đủ của Transformers bao gồm 2 thành phần:
- Encoder Stack - nhận Input Sequence và sinh ra Context Vector đại diện cho Input Sequence đó.
- Decoder Stack - sinh ra Output Sequence dựa vào Context Vector.
Bởi vì nhiệm vụ của BERT là sinh ra Vector đại diện (Sequence Embedding hay Context Vector) của câu nên nó chỉ cần phần Encoder Stack.
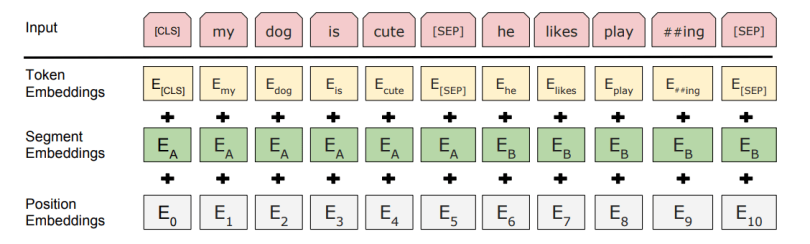
Cũng giống như Transformers, BERT cũng yêu cầu Positional Encoding thêm vào Input Sequence. Ngoài ra, nó còn yêu cầu thêm một số thành phần khác:
- Token Embedding: Một CLS Token được thêm vào tại vị trí đầu tiên của Input Sequence, và SEP Token được thêm vào cuối mỗi câu trong Input Sequence.
- Segment Embedding: Một ký hiệu chỉ ra từ nào thuộc về câu nào nếu trong Input Sequence có nhiều câu.
- Positional Encoding: Chỉ ra vị trí của từ trong Input Sequence.
Để huấn luyện BERT model, chúng ta sử dụng 2 chiến lược như sau:
3.1 Masked LM (MLS)
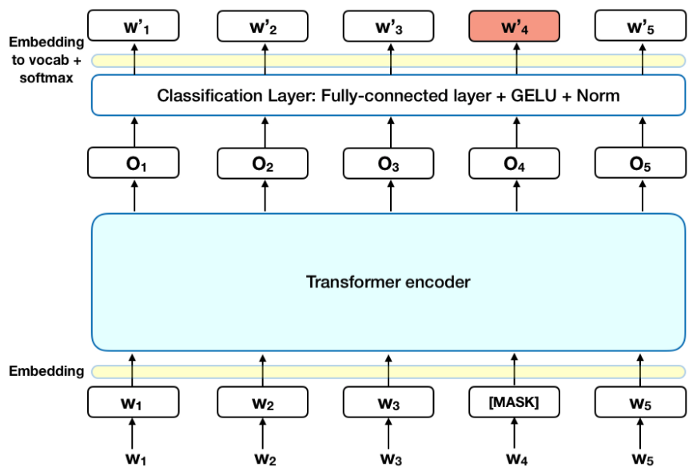
Ý tưởng của LMS khá đơn giản: Lựa chọn ngẫu nhiên 15% các từ trong Input Sequence, thay thế chúng bằng [MASK] token, sau đó toàn bộ qua BERT model để dự đoán các từ được Masked dựa trên mỗi liên hệ trước sau với các từ còn lại. Về mặt kỹ thuật, các bước để thực hiện dự đoán như sau:
- Thêm một lớp Classification ngay sau Ouput của Encoder Stack.
- Nhân Ouput của Encoder Stack với Embedding Matrix để chuyển chúng sang miền của Vocabulary.
- Tính toán xác suất của mỗi từ trong Vocabulary với hàm Softmax.
Ý tưởng này tuy đơn giản dễ thực hiện nhưng lại gặp phải một vấn đề. Đó là BERT model sẽ chỉ dự đoán khi gặp [MASK] token trong Input Sequence, trong khi đó, chúng ta muốn nó phải dự đoán trong bất cứ trường hợp nào, có hoặc không có [MASK] token. Để giải quyết vấn đề này, trong số 15% số từ được lựa chọn ngẫu nhiên kia:
- 80% được thay thế bằng [MASK] token.
- 10% được thay thế bằng token ngẫu nhiên.
- 10% còn lại được giữ nguyên, không thay đổi.
Trong khi huấn luyện BERT model, Loss Function chỉ áp dụng đối với các dự đoán của Masked token và bỏ qua dự đoán của các Non-masked tokens khác. Thời gian huấn luyện cũng lâu hơn khá nhiều so với các model sử dụng phương pháp Nondirection training.
3.2 Next Sentence Prediction (NSP)
Để hiểu được mối quan hệ giữa 2 câu, BERT sử dụng một kỹ thuật gọi là NSP. Trong quá trình huần luyện, một cặp câu được đưa vào, model sẽ học để dự đoán câu thứ 2 trong cặp câu Input đó có phải là câu tiếp theo của câu thứ nhất hay không? (ý tưởng nghe cũng khá giống với Siamese Network trong CV, :D).
Cụ thể, dữ liệu huấn luyện sẽ có 50% số cặp là liên tiếp (câu thứ 2 là tiếp theo của câu thứ nhất), 50% số cặp còn lại là 2 câu rời rạc nhau.
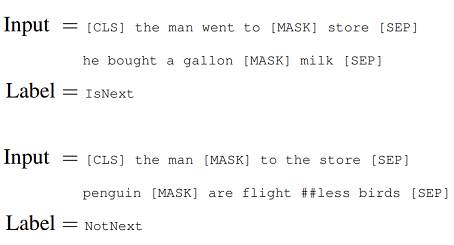
Để dự đoán xem câu thứ 2 có phải là tiếp theo của câu thứ nhất hay không, model sẽ làm như sau:
- Toàn bộ Input Sequence được đưa qua model.
- Ouput của [CLS] token được chuyển về vector kích thước 2x1 thông qua một lớp Classification đơn giản.
- Tính toán xác suất của mỗi nhãn sử dụng hàm Softmax.
MLM và NSP được sử dụng song song trong quá trình huấn luyện BERT model, với mục tiêu là tối thiểu hóa Loss Function kết hợp của cả 2 chiến lược đó. Đây là một ví dụ của câu nói nổi tiếng - Together to better.
4. Một số thông tin về Pre-trained BERT model
- Có 2 phiên bản của Pre-trained BERT model:
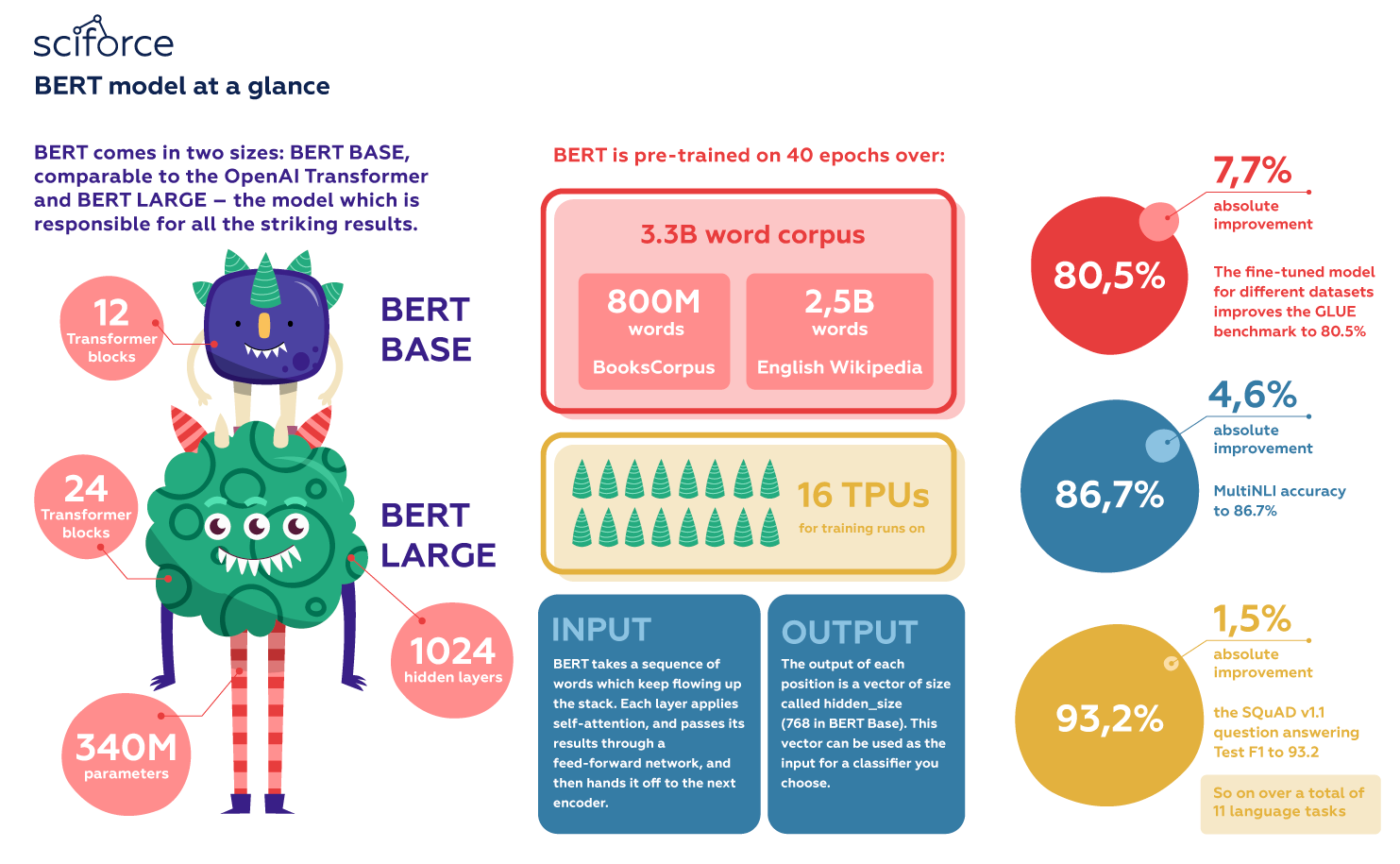
- BERT-Base: 12-layer, 768-hidden-nodes, 12-attention-heads, 110M parameters
- BERT-Large: 24-layer, 1024-hidden-nodes, 16-attention-heads, 340M parameters
Thời gian huấn luyện mỗi phiên bản như sau:

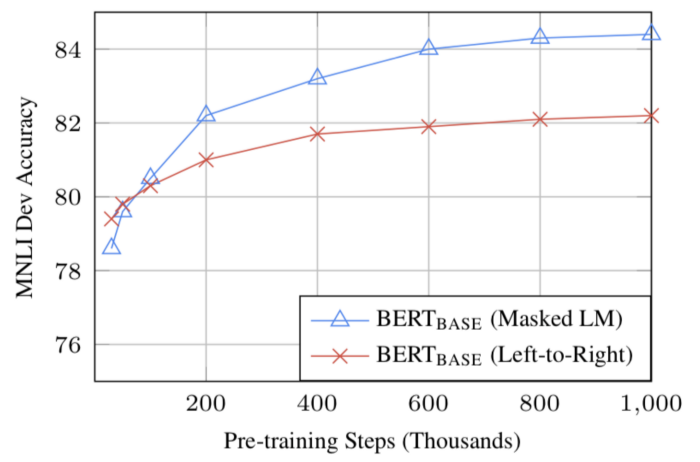
- Nếu có đủ dữ liệu huấn luyện, thời gian huấn luyện lâu hơn sẽ cho độ chính xác cao hơn. Ví dụ, đối với chiến lược Mask LM, BERT-Base model đạt được độ chính xác cao hơn 1% khi huấn luyện 1M Steps, so với 500K Steps (cùng batch_size).
6. Cách sử dụng BERT để Fine-tune model
BERT có thể sử dụng cho rất nhiều tác vụ trong NLP:
- Classification task: Thêm một Classification layer ngay sau Ouput của Encoder Stack cho [CLS] token.
- Question Answering task: Một Q&A model nhận một câu hỏi và nhiệm vụ của nó là tìm ra câu trả lời trong Corpus. Sử dụng BERT, nó có thể được huấn luyện bằng cách học từ các cặp câu trong Input Sequence để dự đoán xem cặp câu đó có phải là một cặp câu hỏi - trả lời hay không?
- Named Entity Recognition (NER): Model nhận một câu và được yêu cầu là đánh dấu các dạng Entities khác nhau (Person, Organization, Date, …) xuất hiện trong câu đó. Sử dụng BERT, model này có thể được huấn luyện bằng cách cho Ouput vector của mỗi Token đi qua một Classification layer để dự đoán xem đó có phải là một Entity hay không?
Trong quá trình Fine-tune, hầu hết các Hyper-parameters của BERT model được giữ nguyên. Các tác giả của bài báo đã đưa ra một số chỉ dẫn về các Hyper-parameters cần quan tâm, thay đổi để đạt được kết quả tốt nhất.
- Dropout – 0.1
- Batch Size – 16, 32
- Learning Rate (Adam) – 5e-5, 3e-5, 2e-5
- Number of epochs – 3, 4
Các bạn có thể đọc chi tiết trong Section 3.5 & 4 của bài báo đó.
7. Một số Pre-trained BERT model cho các tác vụ (lĩnh vực) cụ thể
BERT là mã nguồn mở, có nghĩa là bất kỳ ai cũng có thể sử dụng nó. Google tuyên bố rằng người dùng có thể huấn luyện một hệ thống Question&Answering chỉ mất khoảng 30 phút nếu sử dụng TPU trên Cloud và vài giờ nếu sử dụng GPU. Nhiều tổ chứcc, nhóm nghiên cứu và các nhóm riêng biệt của Google đang tinh chỉnh kiến trúc mô hình BERT để tối ưu hóa hiệu quả của nó hoặc chuyên môn hóa nó cho một số nhiệm vụ nhất định. Một số ví dụ bao gồm:
- patentBERT - BERT model fine-tuned thực hiện nhiệm vụ phân loại các sáng kiến theo các nhóm khác nhau.
- docBERT - BERT model fine-tuned thực hiện nhiệm vụ phân loại các văn bản nói chung.
- bioBERT - BERT model fine-tuned thực hiện tạo Vector Embedding cho các tài liệu trong lĩnh vực sinh học.
- VideoBERT - BERT model fine-tuned thực hiện gán nhãn Video trên Youtube.
- SciBERT - BERT model fine-tuned thực hiện tạo Vector Embedding cho các tài liệu trong lĩnh vực khoa học.
- G-BERT - BERT model fine-tuned kết hợp với phương pháp Hierarchical Representations để đưa ra các khuyến nghị trong lĩnh vực y học.
- TinyBERT by Huawei - Phiên bản rút gọn của BERT để chạy nhanh hơn.
- DistilBERT by HuggingFace - Tương tự TinyBERT.
- PhoBERT - BERT model fine-tuned dành riêng cho các bài toán NLP sử dụng tiếng Việt, được công bố bởi VinAI.
8. Kết luận
BERT chắc chắn là một bước đột phá trong việc giải quyết các bài toán NLP. Nó cho phép tiếp cận và tinh chỉnh nhanh các tham số, layers để áp dụng vào một loạt các bài toán thực tế . Trong bài này, chúng ta đã mô tả một số đặc điểm chính của BERT mà không đi quá sâu về mặt toán học. Nếu bạn muốn tìm hiểu tường tận, chi tiết hơn, bạn nên tìm đọc bài báo gốc của tác giả. Một tài liệu tham khảo hữu ích khác là mã nguồn BERT và các Pre-trained model của nó, bao gồm 103 ngôn ngữ và được nhóm nghiên cứu phát hành rộng rãi dưới dạng mã nguồn mở.
Ở bài tiếp theo, có lẽ mình sẽ quay lại một số chủ đề của Computer Vision. Mời các bạn đón đọc.
9. Tham khảo