Self-Attention và Multi-head Sefl-Attention trong kiến trúc Transformer
Kiến trúc Transformer với xương sống là Self-Attention đã làm mưa làm gió trong cộng đồng NLP trong 1-2 năm gần đây. Nó đạt được độ chính xác rất cao trong hầu hết các bài toán NLP. Trong bài này, hãy cùng nhau tìm hiểu kỹ hơn về cơ chế Self-Attention, làm tiền đề cho việc tìm hiểu kiến trúc Transformer ở bài sau.
1. Self-Attention là gì?
Chúng ta đều biết rằng Word Embedding là vector đại diện cho ngữ nghĩa của một từ trong câu. Những từ mà có nghĩa tương tự nhau thì vector của chúng cũng sẽ gần giống nhau và ngược lại. Tuy nhiên, trong một câu, ý nghĩa của các từ riêng lẻ không đại diện cho cả câu đó. Ví dụ, xét câu: The bank of a river. Hai từ bank và river, nếu tách riêng thì có ý nghĩa hoàn toàn khác nhau, và nếu mang ý nghĩa đó của chúng vào câu thì sai hoàn toàn.
Cơ chế Self-Attention được đề xuất trong bài báo Attention is all you need có thể giải quyết tốt vấn đề này. Ý tưởng làm việc của nó là so sánh các từ với nhau đôi một, bao gồm cả chính nó (self) để tìm ra mức độ quan trọng của mỗi từ mà nó nên chú ý tới (thể hiện qua trọng số).
2. Minh họa cách làm việc của Self-Attention
Cơ chế Attention có thể được hiểu như là sự kết hợp giữa một Query và một cặp Key-Value để cho ra một Output. Công thức tính như sau:
$Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}}) \times V$
Trong đó, $\frac{1}{\sqrt(d_k)}$ là hệ số tỷ lệ. $d_k$ là số chiều của Key.
2.1 Bước 1 - Chuẩn bị Input
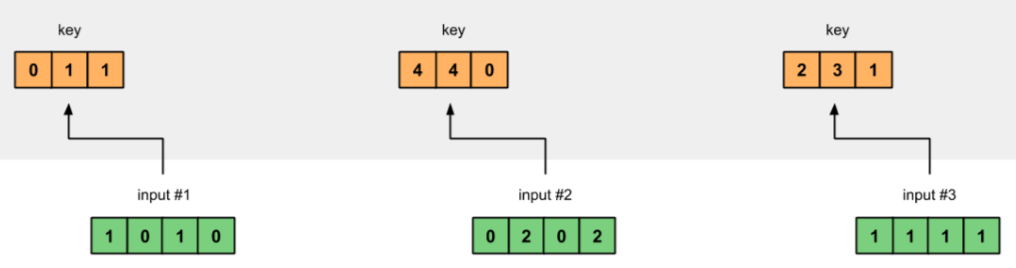
Giả sử, chúng ta có 3 Inputs (3 từ trong Input Sequence), mỗi Input là một vector 4 chiều như sau:


2.2 Bước 2 - Khởi tạo trọng số (Weight) cho Key, Query và Value
Mỗi một Input sẽ được đại diện bởi 3 đại lượng: key, query và value có số chiều tùy ý. Giả sử, 3 đại lượng này có số chiều là 3. Để tạo ra chúng, ta cần khởi tạo các trọng số cho từng đại lượng. Vì Input có số chiều là 4, (Key, Query, Value) có số chiều là 3 nên các Weights phải có kích thước 4x3. Chúng thường có giá trị nhỏ, được khởi tạo ngẫu nhiên sử dụng một trong số các phân phối Gaussian, Xavier, Kaiming, …
-
Weight cho Key:

-
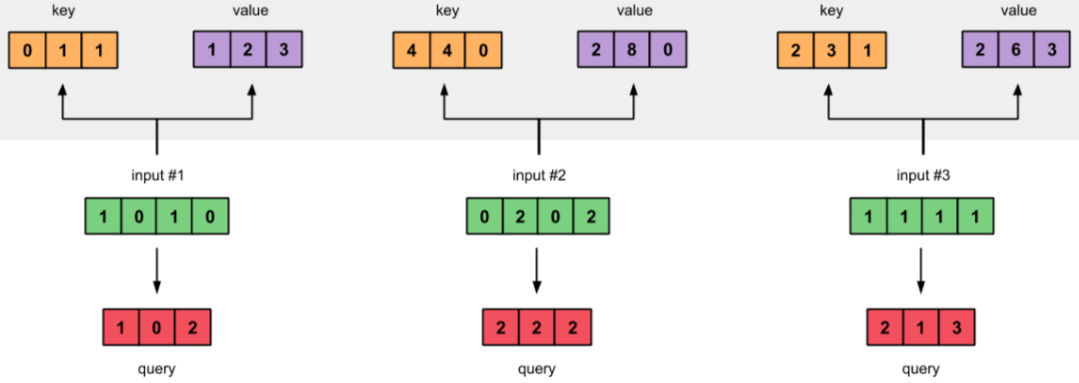
Weight cho Query:

-
Weight cho Value:

2.3 Bước 3 - Tính Key, Query, Value
Key, Query, Value đạt được bằng cách nhân (dot product) Input với trọng số tương ứng của chúng.
- Key:

- Query:

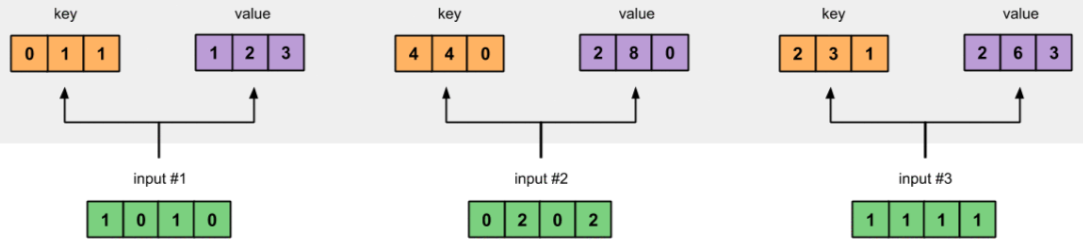
- Value:

Trong thực tế, một Bias Vector có thể được thêm vào khi tính các giá trị Key, Query và Value.
2.4 Bước 4 - Tính Attention Scores
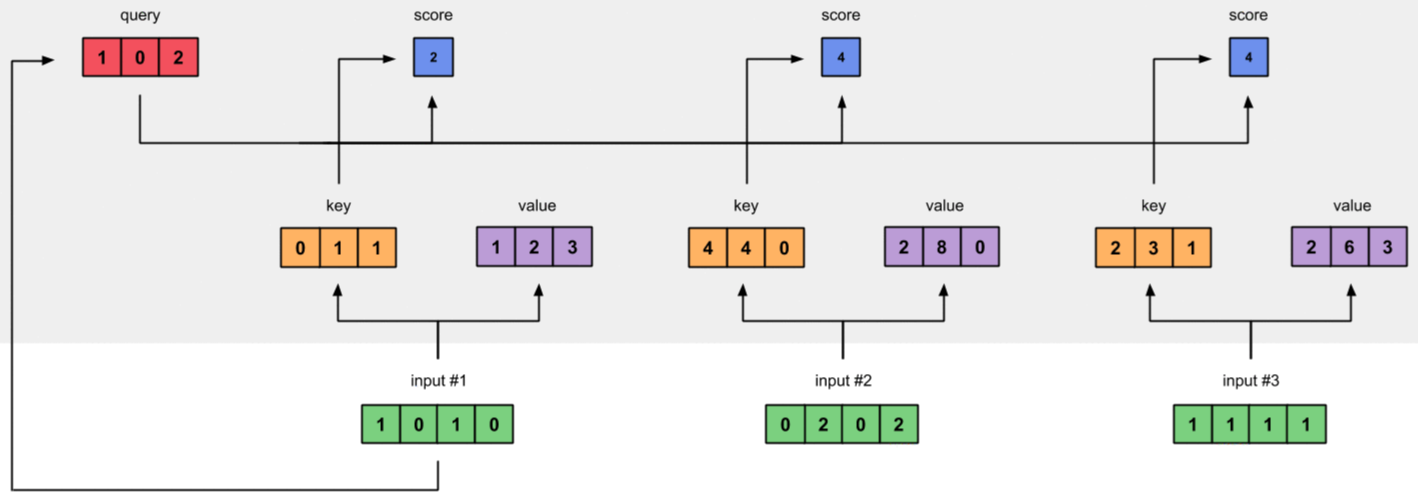
Để tính Attention Scores cho Input1, ta nhân (dot product) Query của nó với tất cả các Keys.

Từ bước 4 đến bước 7, mình chỉ tính cho Input1 làm đại diện. Hai Inputs còn lại được tính tương tự.
2.5 Bước 5 - Tính Softmax Để đơn giản, mình bỏ qua hệ số tỉ lệ $\frac{1}{\sqrt(d_k)}$
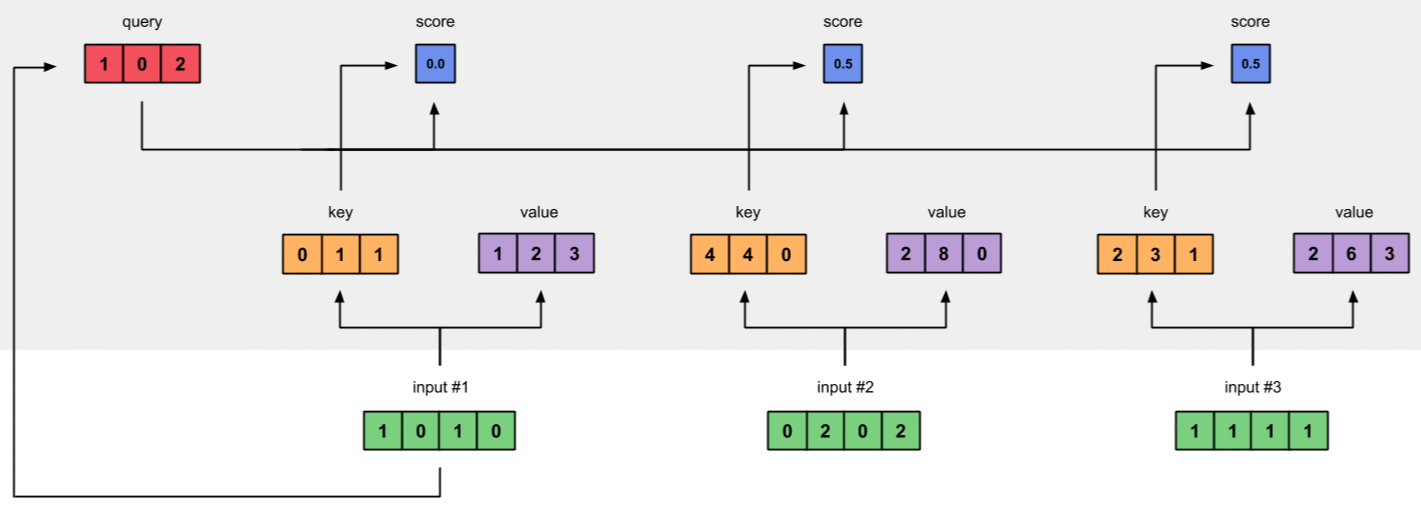
Đưa Attention Scores qua hàm Softmax ta được:

2.6 Bước 6 - Tính Weighted Values
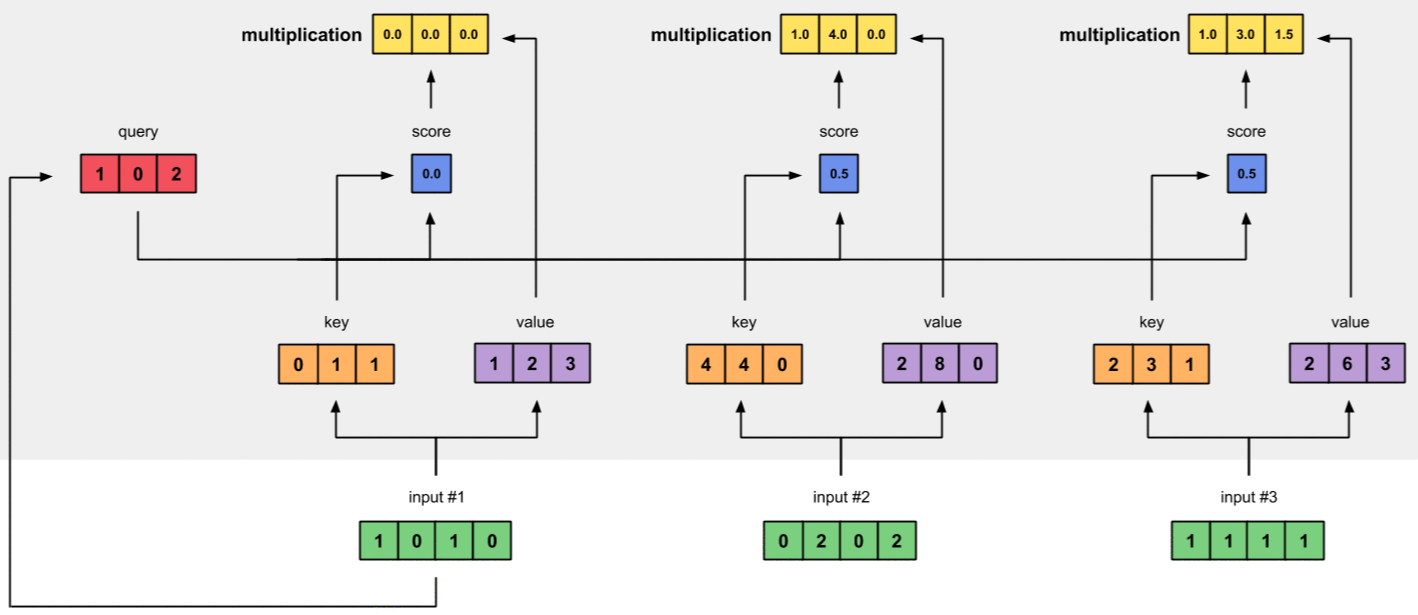
Softmaxed Attention Score nhân với tất cả các Values ta được Weighted Values.

2.7 Bước 7 - Tính tổng Weighted Values
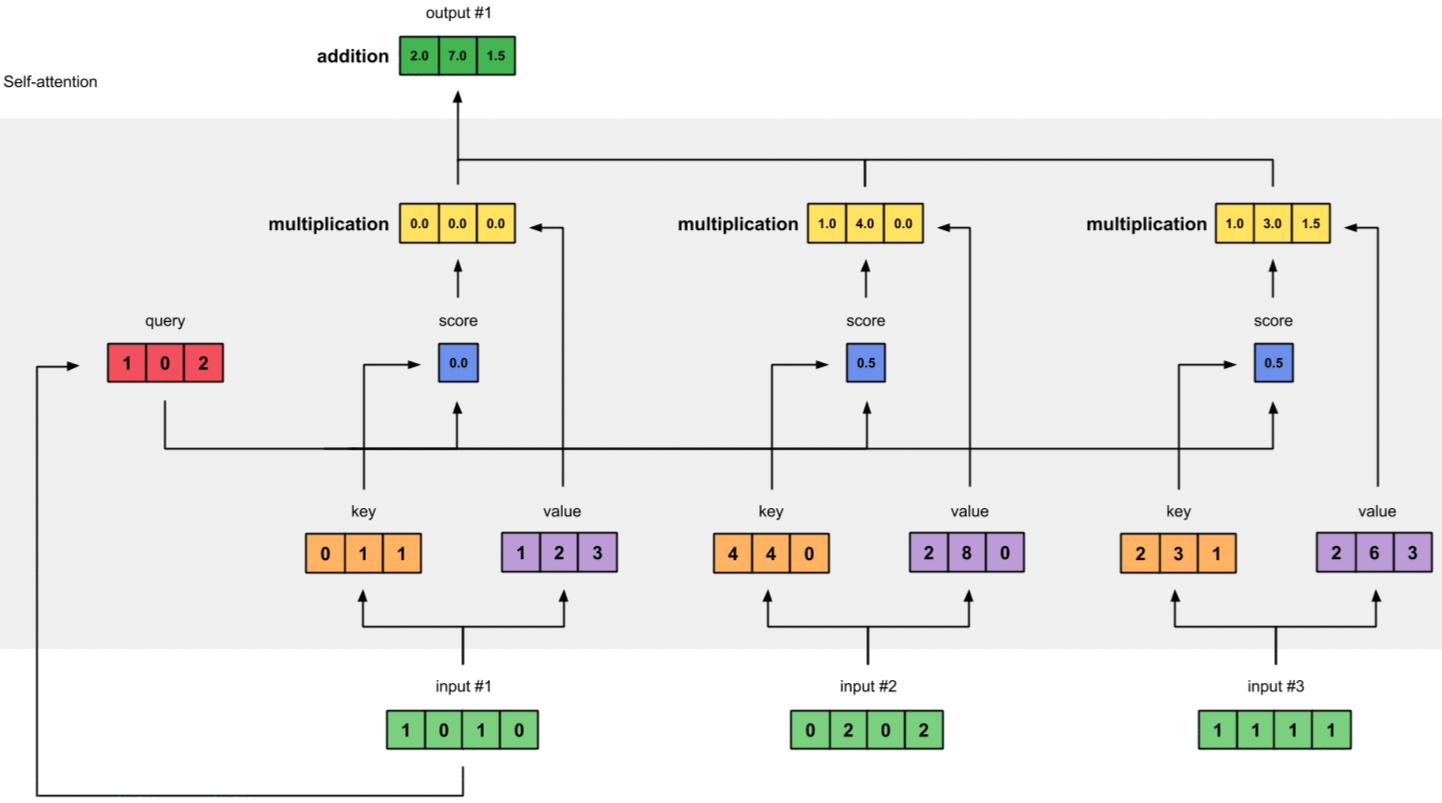
Tính tổng Weighted Values theo kiểu element-wise ta được Output1 vector:

[2.0, 7.0, 1.5] chính là bộ trọng số thể hiện sự tương quan của Input1 với từng Input (bao gồm chính nó).
2.8 Bước 8 - Lặp lại từ bước 4-7 cho Input2 & Input3
Chúng ta đã tính xong Output1, lặp lại các bước từ 4-7 đối với Input2 & Input3 ta được Output2 & Output3.
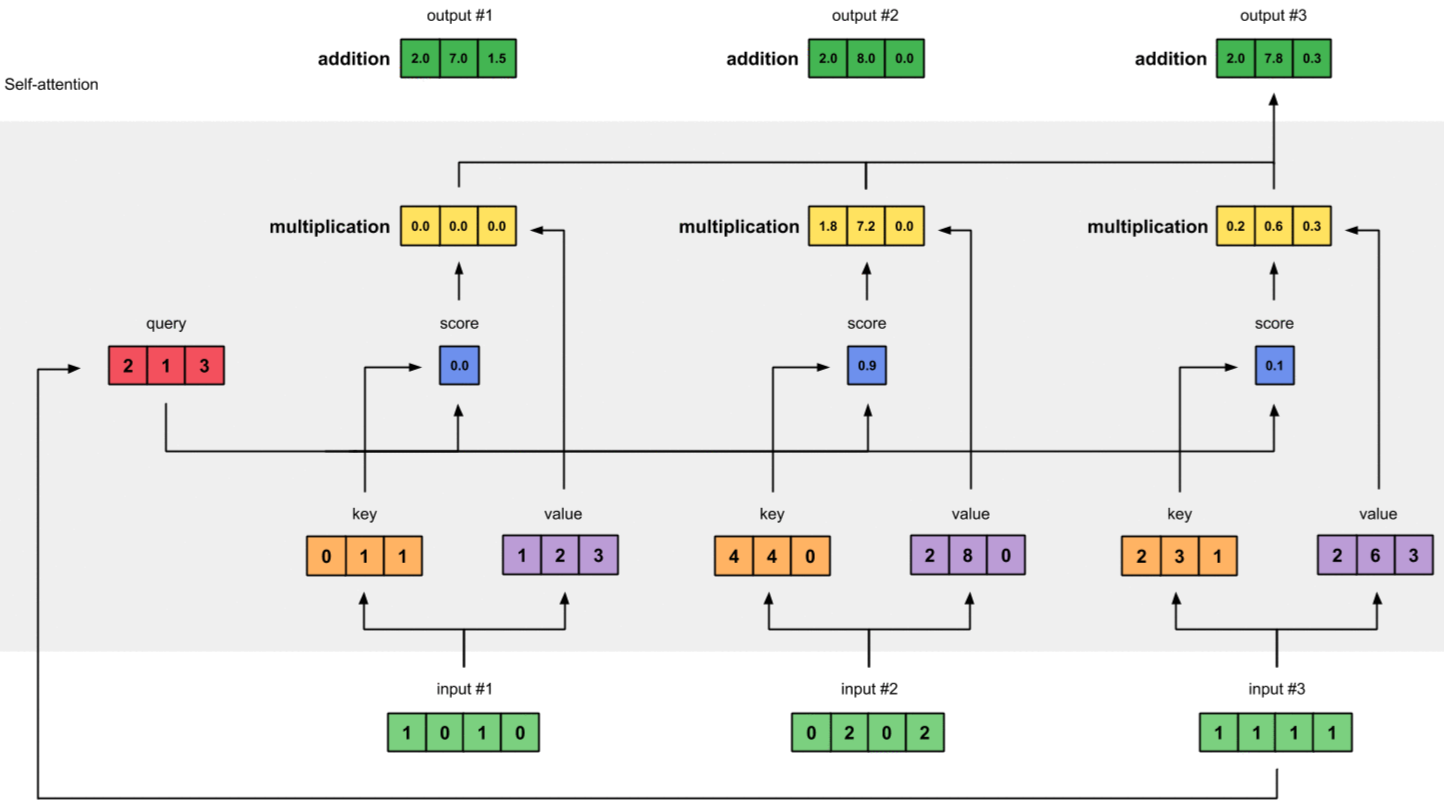
Chú ý - Kích thước của Query và Key phải luôn bằng nhau để có thể thực hiện được dot product, còn kích thước của Value có thể khác. Kich thước của Output sẽ giống với kích thước của Value.
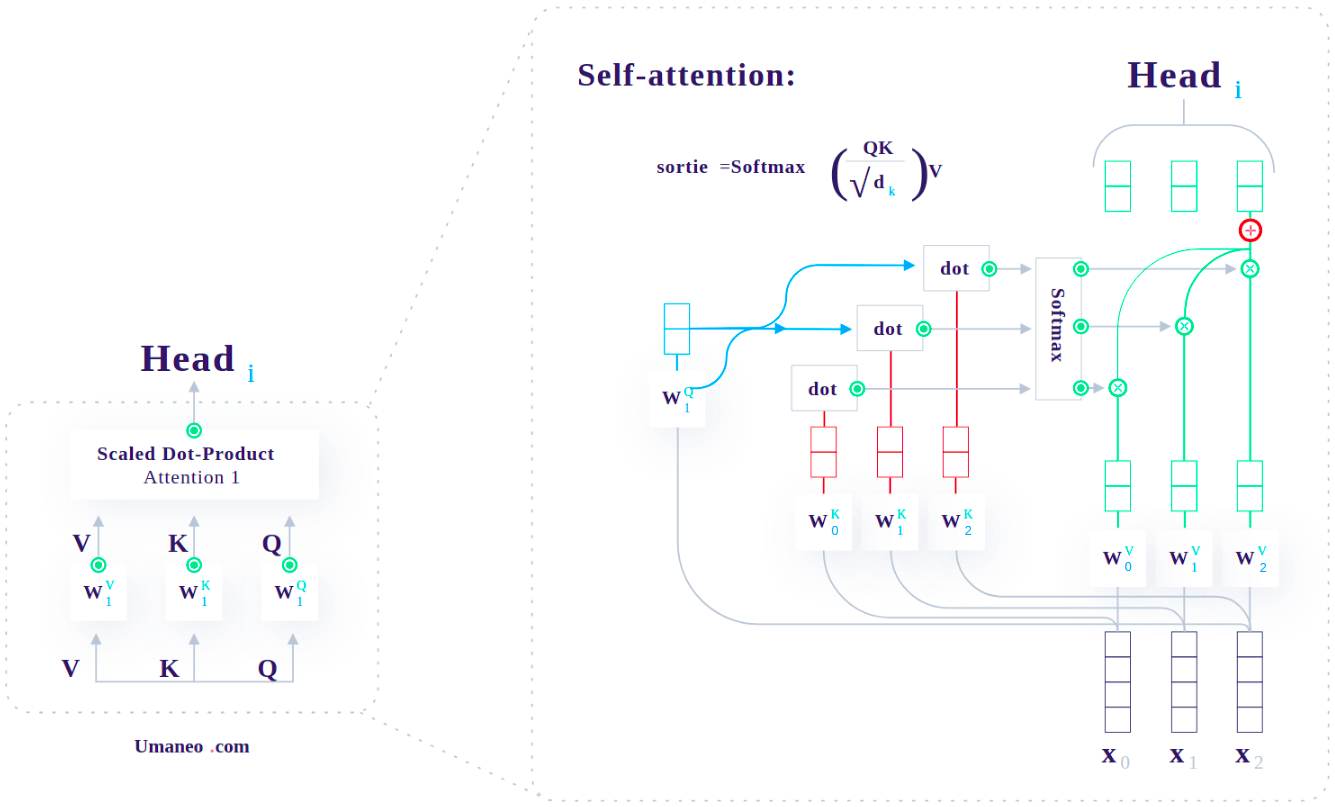
3. Multi-Head Self-Attention
Trong kiến trúc của Transformer, mỗi một Self-Attention module được gọi là một Head. Việc sử dụng nhiều Heads đồng thời gọi là Multi-Head.
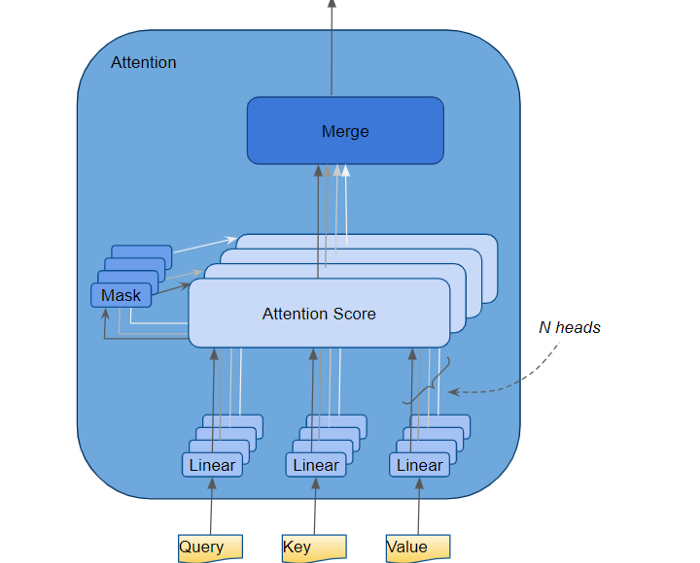
Mỗi Head nhận vào một Input $x$ (Token Embedding và Positional Decoding) và cho ra:
$Head_i = Attention_i(x) = softmax(\frac{Q_iK_i^T}{\sqrt(d_k)})V_i$
Trong đó, $d_k = d_k$(trong trường hợp một Head) /(số lượng Head).
Sau khi có được các Output của từng Head, ta sẽ tổng hợp chúng lại thành 1 Output duy nhất.
$MultiHead(Q,K,V) = Concat(Head_1, Head_2, ..., Head_h)W^0$
$W^0$ là ma trận có chiều rộng bằng với chiều rộng của ma trận Input, mục đích sử dụng của nó là để đưa kích thước của Output về bằng với kích thước của Input.
4. So sánh Attention và Self-Attention
Nếu bạn vẫn còn mơ hồ giữa Attention và Self-Attention thì mình sẽ liệt kê những điểm khác nhau giữa chúng cho bạn.
- Attention thường sử dụng kết hợp với RNN/LSTM/GRU để cải thiện hiệu năng của mô hình hiện tại. Self-Attention thay thế hoàn toàn RNN/LSTM/GRU.
- Attention thường xuất hiện trong kiến trúc có đủ 2 thành phần Encoder và Decoder để truyền thông tin giữa chúng. Ngược lại,Self-Attention thường chỉ áp dụng trong phạm vi một thành phần, hoặc Encoder hoặc Decoder.
- Attention chỉ có thể sử dụng 1 lần trong một kiến trúc mô hình, trong khi đó, Self-Attention có thể áp dụng nhiều lần (VD: 18 lần trong Transformer).
- Self-Attention, như tên gọi, làm nhiệm vụ mô hình hóa mối quan hệ giữa các từ trong một cùng 1 chuỗi (Query, Key, Value xuất phát từ cùng 1 nguồn), còn Attention thì là 2 chuỗi khác nhau.
- Attention có thể kết nối 2 kiểu Input Sequence khác nhau (VD: text & image), Self-Attention thì chỉ làm việc với 1 loại.
- Cơ chế Multi-Head thường áp dụng cho Self-Attention. Nhưng về mặt lý thuyết, nó cũng có thể được sử dụng cho Attention.
- Tương tự, Query/Key/Value thường sử dụng đối với Self-Attention, nhưng nó cũng có thể được áp dụng cho Attention.
5. Kết luận
Trong bài này, chúng ta đã cùng nhau tìm hiểu khá chi tiết về cơ chế Self-Attention cũng như khái niệm Multi-Head Self-Attention.
Ở bài tiếp theo, mình sẽ giới thiệu về mô hình Transformer. Mời các bạn đón đọc.
6. Tham khảo