Tìm hiểu cơ chế Attention trong mô hình Seq2Seq
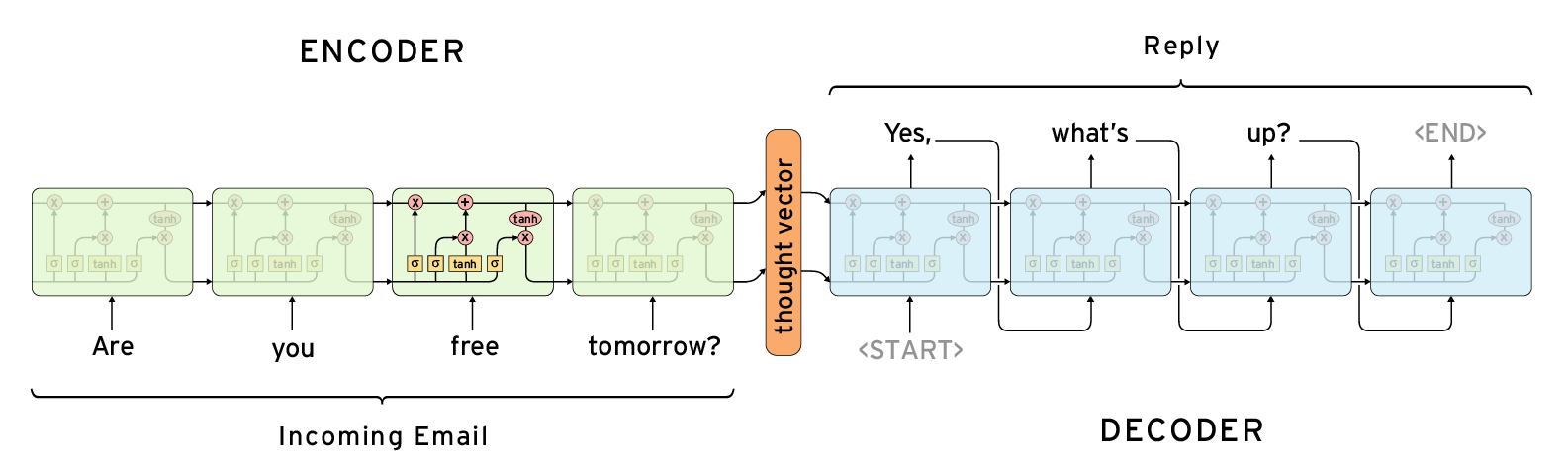
Trong bài này, mình sẽ giải thích qua về kiến trúc Encoder-Decoder với mô hình Seq2Seq. Sau đó, chúng ta sẽ tìm hiểu chi tiết về cơ chế Attention áp dụng trong kiến trúc đó.
1. Giới thiệu mô hình Sequence to Sequence (Seq2Seq)
Mô hình Seq2Seq được giới thiệu lần đầu vào năm 2014 bởi Google. Mục đích của nó là ánh xạ một Input Sequence Data có chiều dài cố định thành một Output Sequence Data có chiều dài cố định. Chiều dài của 2 Sequence Data không nhất thiết phải giống nhau. Ví dụ khi dịch câu có 5 từ What are you doing now? từ tiếng Anh sang câu có 7 ký tự 今天你在做什麼? trong tiếng Trung Quốc.
Mô hình Seq2Seq có thể giải quyết các bài toán sau:
- Text Summarization - Đây là bài toán tóm tắt nội dung của một văn bản dài thành một đoạn văn bản ngắn hơn. Kể từ khi được Google giới thiệu năm 2014, nó đã trở nên khá phổ biến.
- Machine Translation - Dịch văn bản giữa các ngôn ngữ khác nhau. Google Translate chính là một sản phẩm của bài toán này.
- Image/Video Captioning - Đưa cho máy tính một bức ảnh hoặc một video, nó sẽ trả lại cho bạn một (hoặc một vài) câu miêu tả nội dung của bức ảnh / Video đó. Mình đang nghĩ rằng phần thi đầu tiên của kỳ thi TOEIC (phần thi miêu tả tranh) có thể chính là một ứng dụng thực tế của bài toán này.
- Speech Recognition - Bài toán trong lĩnh vực Audio, còn được gọi là Speech To Text, tức chuyển đổi âm thanh thành văn bản.
- Music Generation - Đây là một bài toán rất thú vị, máy tính có thể sáng tác nhạc cho bạn. Nghe chắc sẽ rất ngầu! :D
- Recommendation Engine - Hệ thống khuyến nghị có lẽ đã không còn xa lạ với mọi người. Có rất nhiều các để tạo ra nó, và mô hình Seq2Seq với kiến trúc Encoder-Decoder cũng là một trong số đó, cho kết quả rất khả quan.
- Chatbot - Hay còn gọi là hệ thống Question-Answer. Siri hay Alexa là ví dụ thực tế.
Các bài toán kể trên đều có chung một đặc điểm là chúng sử dụng dữ liệu ở dạng chuỗi (tuần tự), bao gồm nhiều TimeSteps. Đó có thể là văn bản, âm thanh, tín hiệu, … Ví dụ đối với văn bản thì mỗi TimeStep có thể hiểu là một từ trong văn bản đó.
2. Kiến trúc của mô hình Seq2Seq
Mô hình Seq2Seq bao gồm 2 thành phần: Encoder và Decoder. Mỗi một thành phần bao gồm nhiều NN Layers xếp chồng lên nhau (stack). NN Layer có thể là CNN, RNN, LSTM. GRU, … Trong bài này, mình sẽ lấy ví dụ là LSTM.

2.1 Quá trình huấn luyện
Trong quá trình huấn luyện, mỗi thành phần sẽ thực hiện nhiệm vụ như sau:
-
Encoder - Đọc vào toàn bộ Input Sequence, lần lượt từng TimeStep tại các LSTM Cell. Tại TimeStep $t$, Output ra của các Cell là Hidden State ($h_t$) và Cell State ($C-t$), gọi chung là Internal State. Internal State của TimeStep trước được sử dụng cùng với Input của TimeStep hiện tại để làm đầu vào cho Cell hiện tại. Internal State ($h_0, c_0$) được khởi tạo ngẫu nhiên. Internal State của Cell cuối cùng của Encoder được sử dụng làm đầu vào cho Decoder. Chi tiết về Internal State của LSTM Cell, bạn có thể xem lại bài này của mình.
-
Decoder - Đọc vào toàn bộ Target Sequence, lần lượt từng TimeStep. Khác với Encoder, Target Sequence được thêm vào tiền tố START_ và hậu tố _END để chỉ ra điểm bắt đầu và kết thúc của nó. Internal State ban đầu ($h_0, s_0$) của Decoder được khởi tạo bằng với Intern State của Cell cuối cùng trong Encoder. Tại mỗi TimeStep $t$, Decoder sẽ đọc vào một từ trong văn bản Target Sequence, cho ra ra một từ dự đoán ($y'_t$) và Internal State ($h_t, c_t$). Internal State này cũng sẽ được sử dụng cho TimeStep tiếp theo, còn $y'_t$ sẽ được dùng để tính toán lỗi với Target Sequence, sau đó Backpropagation sẽ cập nhật lại các trọng số của model theo lỗi đó. Internal State ở Cell cuối cùng của Decoder được loại bỏ vì không dùng đến.
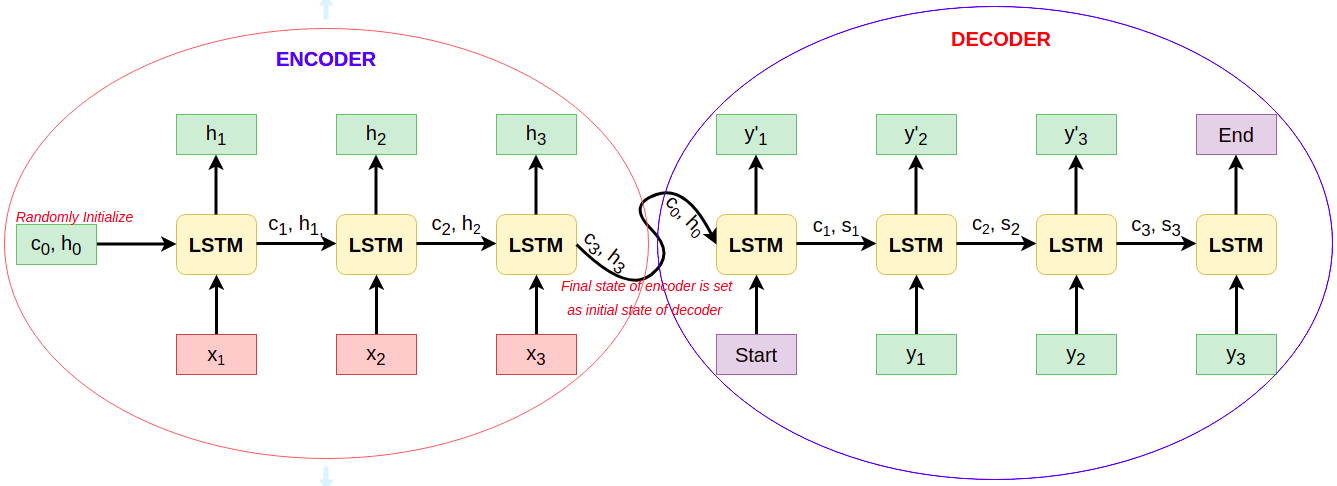
2.2 Quá trình dự đoán
Quá trình dự đoán của Encoder vẫn giống như quá trình huấn luyện nó. Còn đối với Decoder, quá trình dự đoán diễn ra như sau:
- Internal State ban đầu ($h_0, s_0$) của Decoder được khởi tạo bằng với Intern State của Cell cuối cùng trong Encoder.
- Input của Decoder luôn bắt đầu bằng START_.
- LSTM Cell của Decoder sinh ra mỗi từ tại mỗi TimeStep.
- Internal State của mỗi TimeStep được sử dụng cho TimeStep tiếp theo.
- Từ dự đoán sinh ra tại mỗi TimeStep ($y'_t$) được chuyển thành Input cho TimeStep tiếp theo.
- Quá trình dự đoán kết thúc khi Decoder dự đoán ra $y'_t$ là _END.
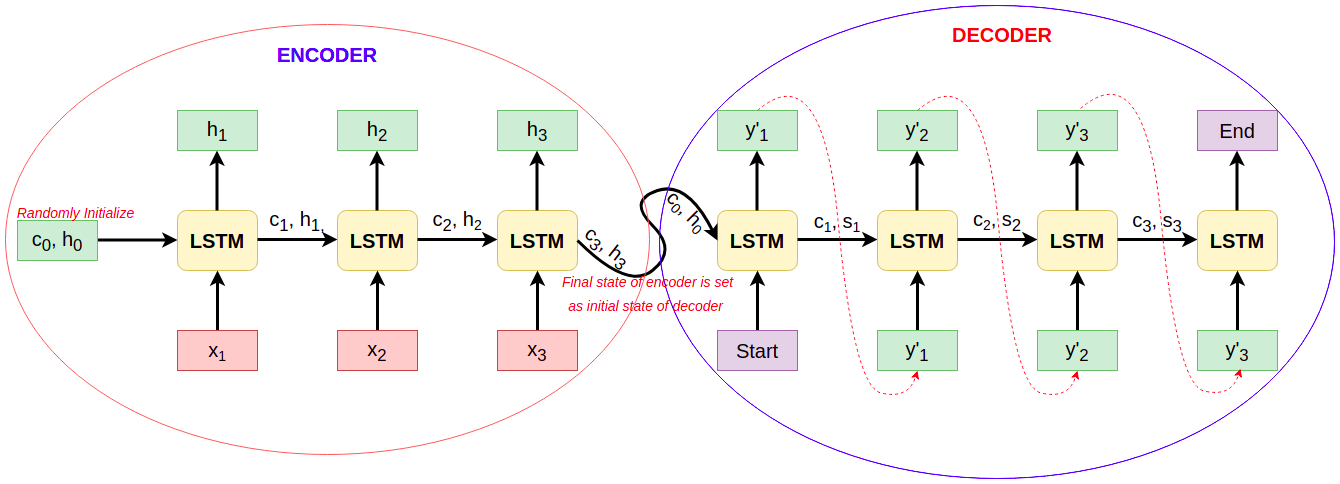
3. Hạn chế của mô hình Seq2Seq với kiến trúc Encoder-Decoder
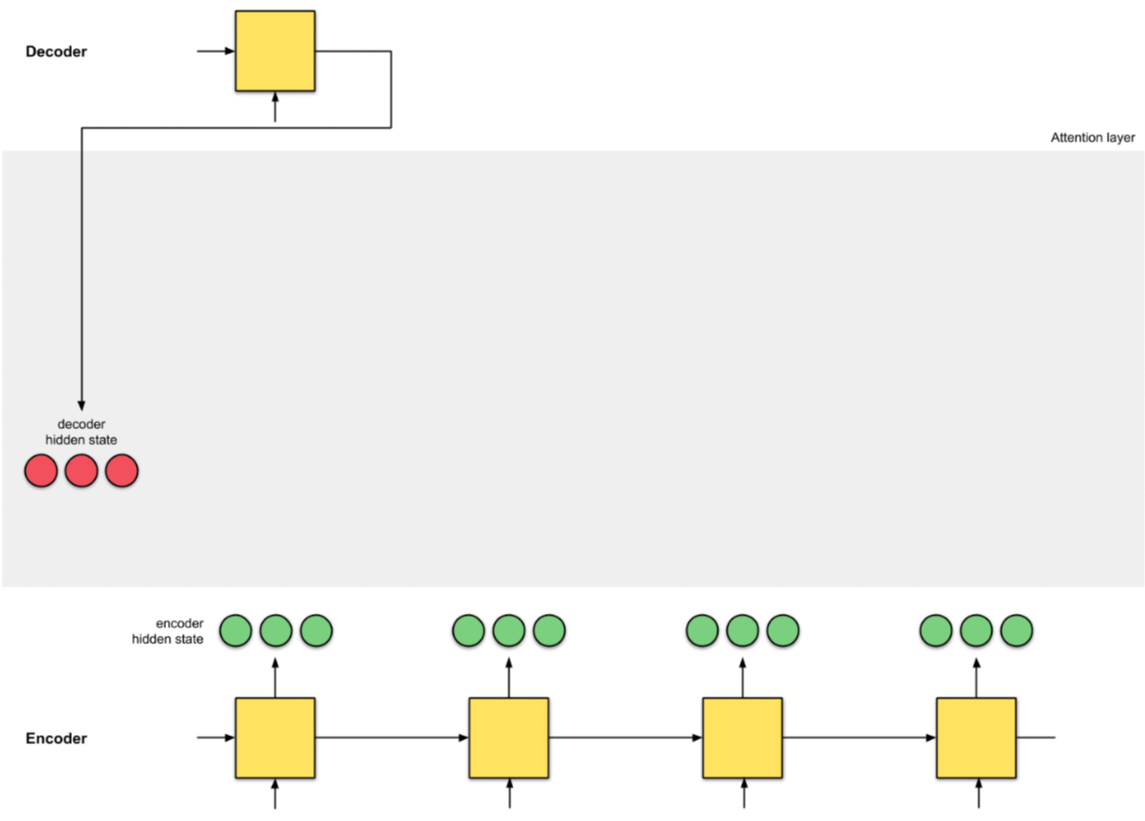
Kiến trúc Encoder-Decoder làm việc rất hiệu quả đối với Input Sequence có chiều dài nhỏ, nhưng hiệu năng sẽ giảm dần khi kích thước của Input Sequence tăng lên. Giả sử, Encoder nhận vào một Input Sequence {$x_1, x_2, …, x_n$} và mã hóa thành các vectors có chiều dài cố định {$h_1, h_2, …, h_n$}, gọi là Hidden State hay Context Vector. Chỉ có Context Vector cuối cùng $h_n$ mới được sử dụng cho bộ Decoder để dự đoán Output, dẫn đến thông tin của toàn bộ Input Sequence không được sử dụng đầy đủ (mất thông tin). Attention xuất hiện như là một giải pháp hữu hiệu để giải quyết vấn đề này.
4. Giới thiệu Attention
Attention là một kỹ thuật được Bahdanau et al., 2014 và Luong et al., 2015 giới thiệu trong các bài báo của họ. Ý tưởng của nó là cho phép Decoder sử dụng thông tin của toàn bộ Input Sequence, nhưng chỉ tập trung vào những phần quan trọng tại mỗi TimeStep. Nói một cách cụ thể và dễ hiểu hơn, Attention thực chất là cơ chế tạo ra một Context Vector bằng cách tính trung bình có trọng số của toàn bộ Internal State của Input Sequence trong bộ Encoder:
$c_i = \sum_{j=1}^n\alpha_{ij}h_j$
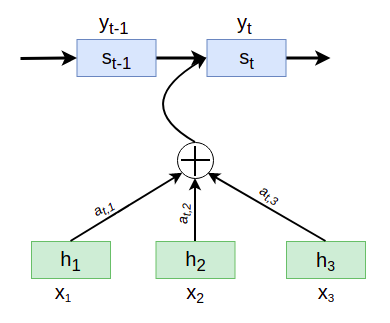
Trong đó:
- $\alpha_{ij}$ là trọng số của TimeStep $j$ của Decoder và TimeStep $i$ của Encoder. Nói cách khác, Output thứ $j$ của Decoder nên chú ý một lượng $alpha_{ij}$ đến Input thứ $i$ của Encoder.
- $h_i$ là Hidden State tại TimeStep $i$ của Encoder.
- $n$ là chiều dài của Input Sequence.
$\alpha_{ij}$ được tính bằng cách lấy Softmax của Attention Score ($e_{ij}$):
$\alpha_{ij} = softmax(e_{ij}) = \frac{exp(e_{ij})}{\sum_{k=1}^m exp(e_{ik}}$
$e_{ij} = f(s_{i-1}, h_j) = AlignScore(s_{i-1}, h_j)$
Trong đó:
- $h_{i-1}$ là Hidden State tại TimeStep $i-1$ của Decoder.
- $s_j$ là Hidden State tại TimeStep $j$ của Encoder.
Context Vector $c_{ij}$ sau đó được sử dụng để Decoder tính ra Output $y_i$.
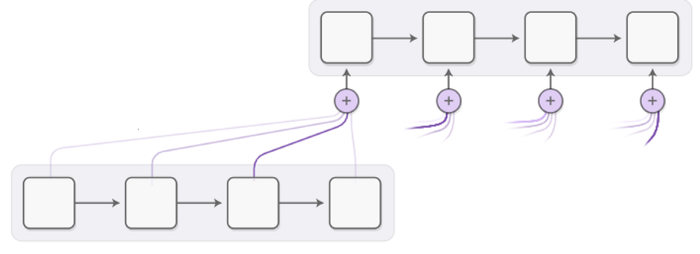
5. Bahdanau Attention & Luong Attention
Như bên trên đã giới thiệu, hai nhóm tác giả đã giới thiệu 2 loại Attention khác nhau, gọi là Bahdanau Attention và Luong Attention.
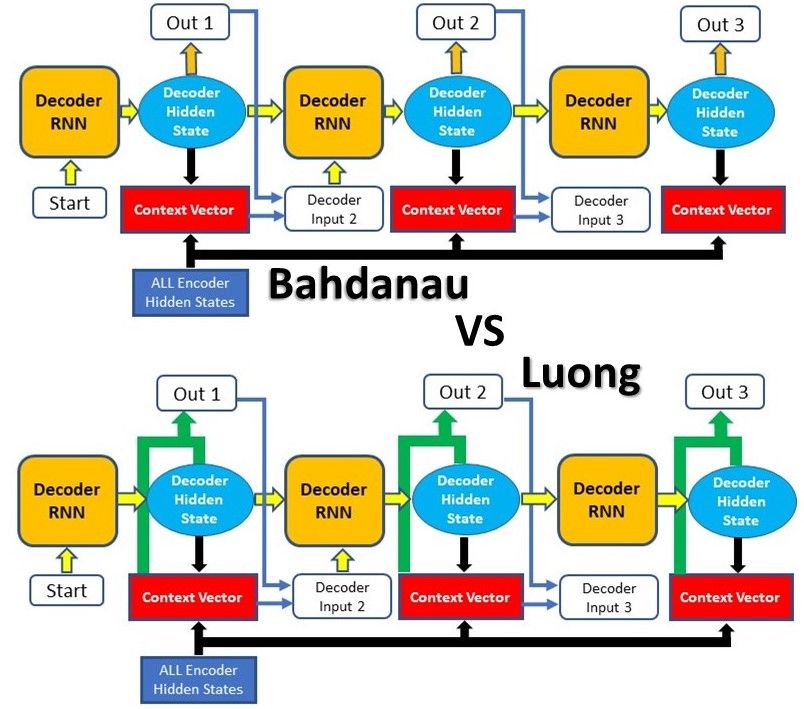
Xét về nguyên lý hoạt động thì 2 dạng Attention này đều giống nhau. Sự khác nhau của chúng nằm ở kiến trúc và cách tính toán của mỗi loại.
5.1 Bahdanau Attention
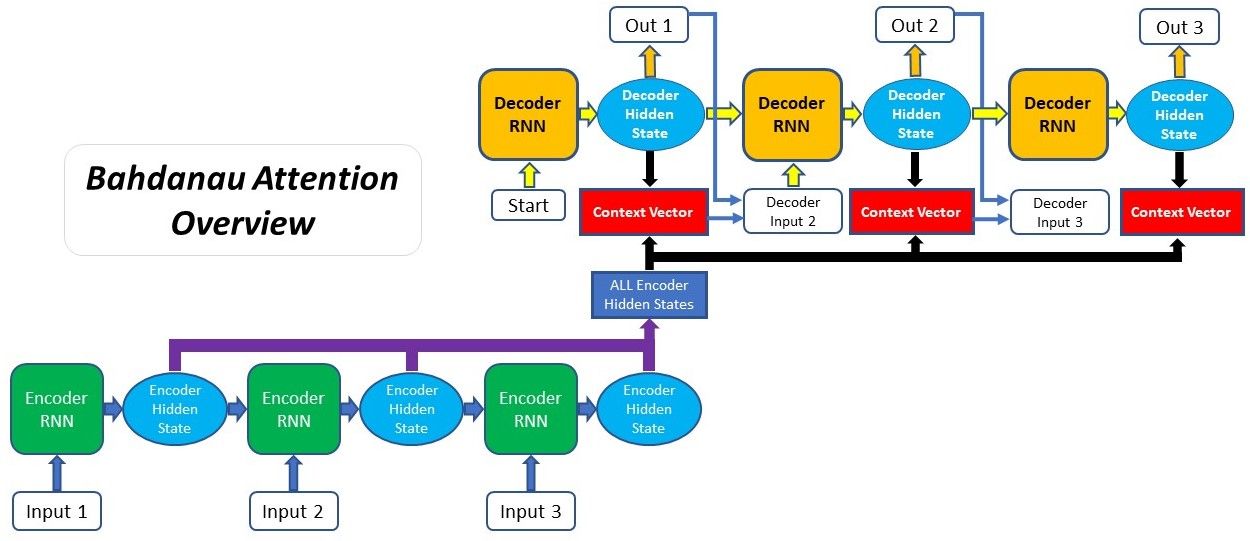
Bahdanau Attention còn được gọi là Additive Attention, được tạo ra bởi Dzmitry Bahdanau trong bài báo vào năm 2014. Mục tiêu của nó là cải thiện hiệu năng của mô hình Seq2Seq bằng cách thay đổi đầu vào của Decoder với các thông tin từ Input Sequence. Các bước tiến hành như sau:
- Tạo Encoder Hidden State - Encoder sinh ra Hidden State tại mỗi TimeStep.
- Tính toán Alignment Score giữa Decoder Hidden State ở TimeStep trước đó với mỗi Encoder Hidden State. Chú ý rằng, Encoder Hidden State ở TimeStep cuối cùng được sử dụng như là Decoder Hidden State ở TimeStep đầu tiên.
- Tính toán Softmax của Alignment Score - Giá trị của Alignment Score ở bước trên được đưa về khoảng giá trị [0,1] bằng cách sử dụng hàm Softmax.
- Tính toán Context Vector - Encoder Hidden State và Alignment Score tương ứng của nó được nhân với nhau để tạo thành Context Vector cho mỗi TimeStep.
- Tính toán Output của Decoder - Các Context Vectors được cộng lại với nhau, rồi cộng với vào Decoder Output và Decoder Hidden State tại TimeStep trước đó, để sinh ra Decoder Output mới tại TimeStep hiện tại.
- Lặp lại bước 2-5 đối với mỗi TimeStep của Decoder đến tận khi Decoder Output là _END hoặc chiều dài của Output Sequence đặt đến giá trị tối đa quy định trước.
5.2 Luong Attention
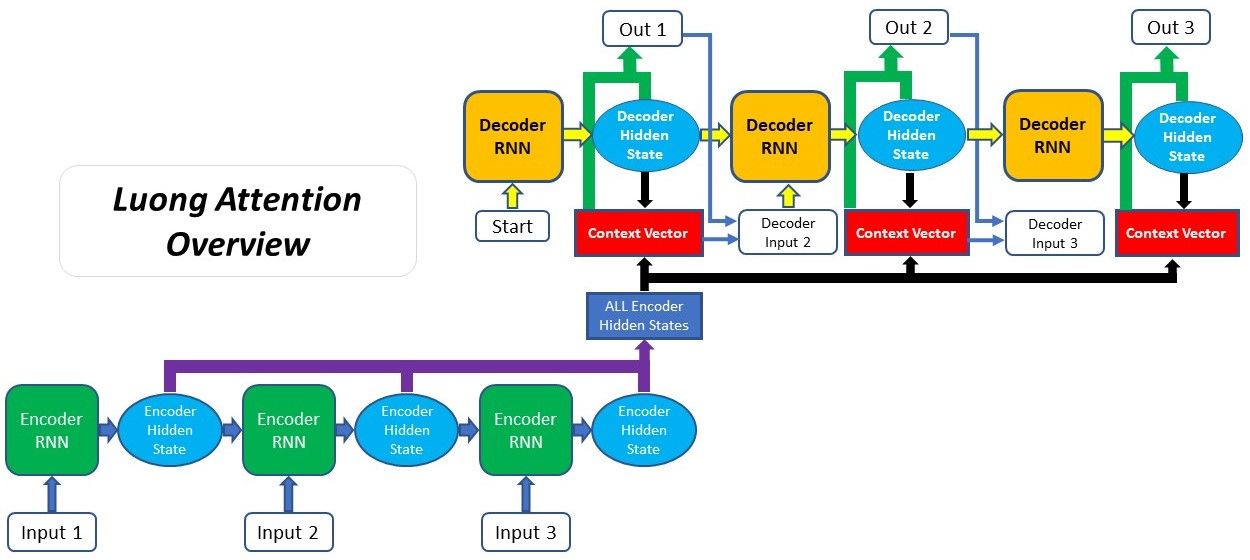
Luong Attention được đề xuất bởi Thang Luong trong bài báo của anh ấy và đồng nghiệp. Nó còn có tên khác là Multiplicative Attention, kế thừa từ Bahdanau Attention. Hai điểm khác biết chủ yếu giữa Luong Attention và Bahdanau Attention là:
- Cách tính toán Alignment Score. Có 3 phương pháp tính Aligment Score trong Luong Attention so với 1 phương pháp của Bahdanau Attention.
- Vị trí của Attention trong kiến trúc Encoder-Decoder.
Các bước thực hiện Luong Attention như sau:
- Tạo Encoder Hidden State - Encoder sinh ra Hidden State tại mỗi TimeStep.
- Tạo Decoder Hidden State - Decoder Hidden State và Decoder Output của TimeStep trước đó được đưa qua Decoder RNN Cell để sinh ra Decoder Hidden State tại TimeStep hiện tại.
- Tính toán Alignment Score - Sử dụng Decoder Hidden State ở bước trên và Encoder Hidden State để tính Alignment Score.
- Tính toán Softmax của Alignment Score - Giá trị của Alignment Score ở bước trên được đưa về khoảng giá trị [0,1] bằng cách sử dụng hàm Softmax.
- Tính toán Context Vector - Encoder Hidden State và Alignment Score tương ứng của nó được nhân với nhau để tạo thành Context Vector.
- Tính toán Output của Decoder - Context Vector được cộng vào Decoder Output và Decoder Hidden State tại TimeStep trước đó, để sinh ra Decoder Output mới tại TimeStep hiện tại.
- Lặp lại bước 2-6 đối với mỗi TimeStep của Decoder đến tận khi Decoder Output là _END hoặc chiều dài của Output Sequence đặt đến giá trị tối đa quy định trước.
Như chúng ta thấy, thứ tự các bước của Luong Attention khác so với Bahdanau Attention.
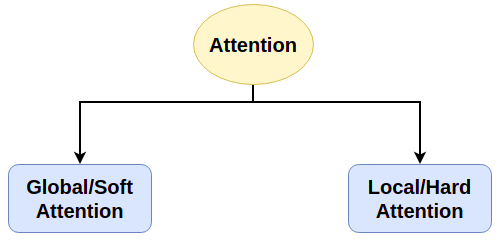
6. Global/Soft Attention & Local/Hard Attention
Phụ thuộc vào việc có bao nhiêu Encoder Hidden State tham gia vào quá trình tạo Context Vector cho Decoder mà chúng ta có thể chia Attention thành 2 loại: Global/Soft Attention và Local/Hard Attention.
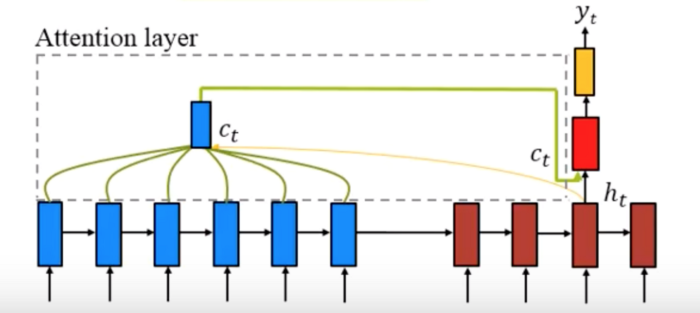
6.1 Global/Soft Attention
Global Attention, tên khác là Soft Attention là loại Attention mà ở đó toàn bộ Encoder Hidden State đều được sử dụng để tính toán Context Vector tại mỗi TimeStep.
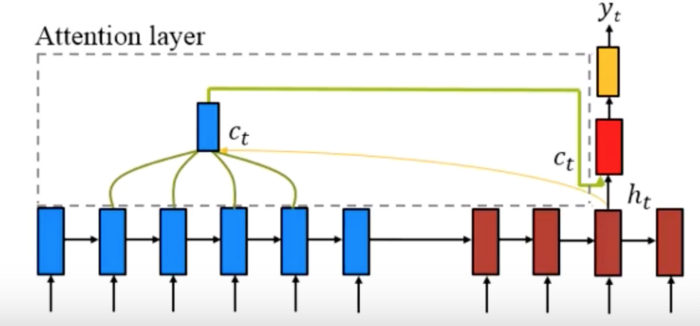
6.2 Local/Hard Attention
Global Attention có một nhược điểm là nó yêu cầu tài nguyên tính toán khá lớn, nhất là đối với các bài toán mà Input Sequence có chiều dài lớn. Đó chính là lý do Local/Hard Attention ra đời. Nó giải quyết vấn đề của Global Attention bằng cách chỉ sử dụng một số lượng nhất định Encoder Hidden State thay vì tất cả.
7. Mở rộng của Attention (Extended Attention)
Các loại Attention mà chúng ta nói từ đầu đến giờ chỉ hoạt động với kiến trúc Encoder-Decoder (có đủ 2 thành phần Encoder và Decoder), tức là phải có cả Input Sequence và Target Sequence như trong bài toán Machine Translation hay Text Summarization. Để áp dụng vào bài toán mà chỉ có một thành phần Encoder (chỉ có Input Sequence, không có Target Sequence) hoặc ngược lại, như Text Classification, chúng ta phải sử dụng các dạng mở rộng của Attention. Có 3 loại Extended Attention là: Self-Attention, Multi-head Self-Attention và Hierarchical Attention.
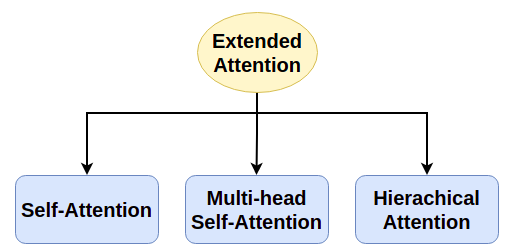
Chúng ta sẽ tìm hiểu kỹ hơn về Self-Attention và Multi-head Sefl-Attention trong bài tiếp theo. Còn Hierachical Attention, các bạn đọc thêm tại đây.
8. Một số dạng Alignment Score Function
Bảng dưới đây tổng hợp một số dạng Alignment Score Function:

9. Ví dụ về cách làm việc của Attention
Trong phần này, chúng ta sẽ minh họa cách làm việc của Attention thông qua một ví dụ trực quan để có thể hiểu rõ hơn về nó.
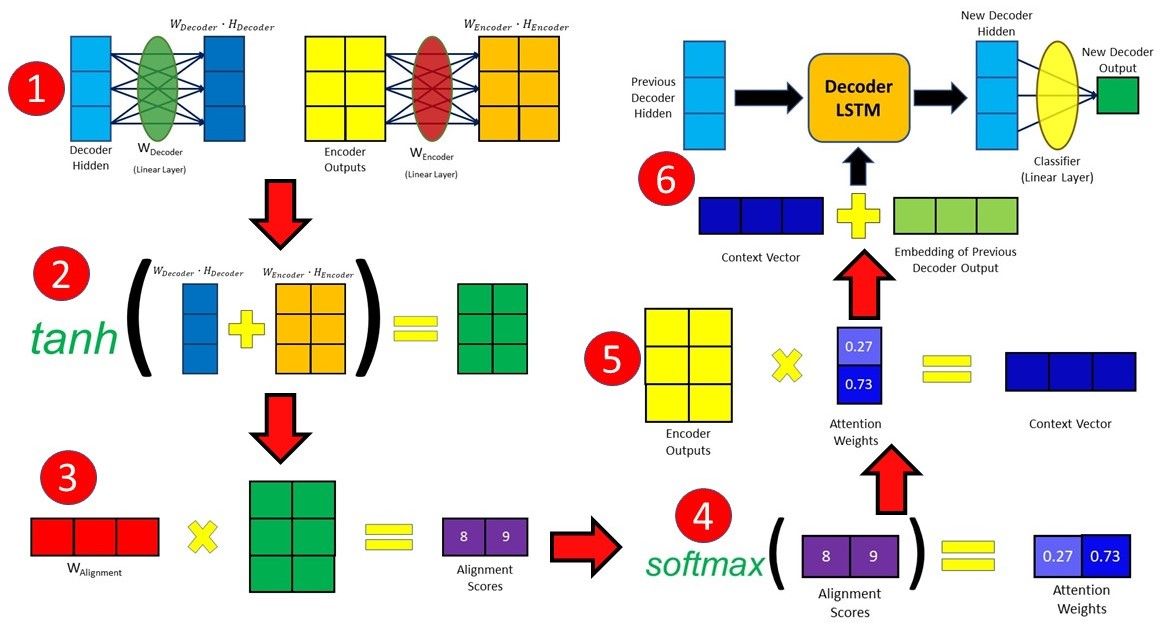
9.1 Bước 1 - Chuẩn bị Encoder Hidden State
Giả sử chúng ta có 4 Encoder Hidden States (màu xanh) và Decoder Hidden State đầu tiên (màu vàng).
9.2 Bước 2 - Tính Alignment Score
Tính Aligment Score, sử dụng Dot Product Function giữa Decoder Hidden State và Encoder Hidden States (xem mục 8).
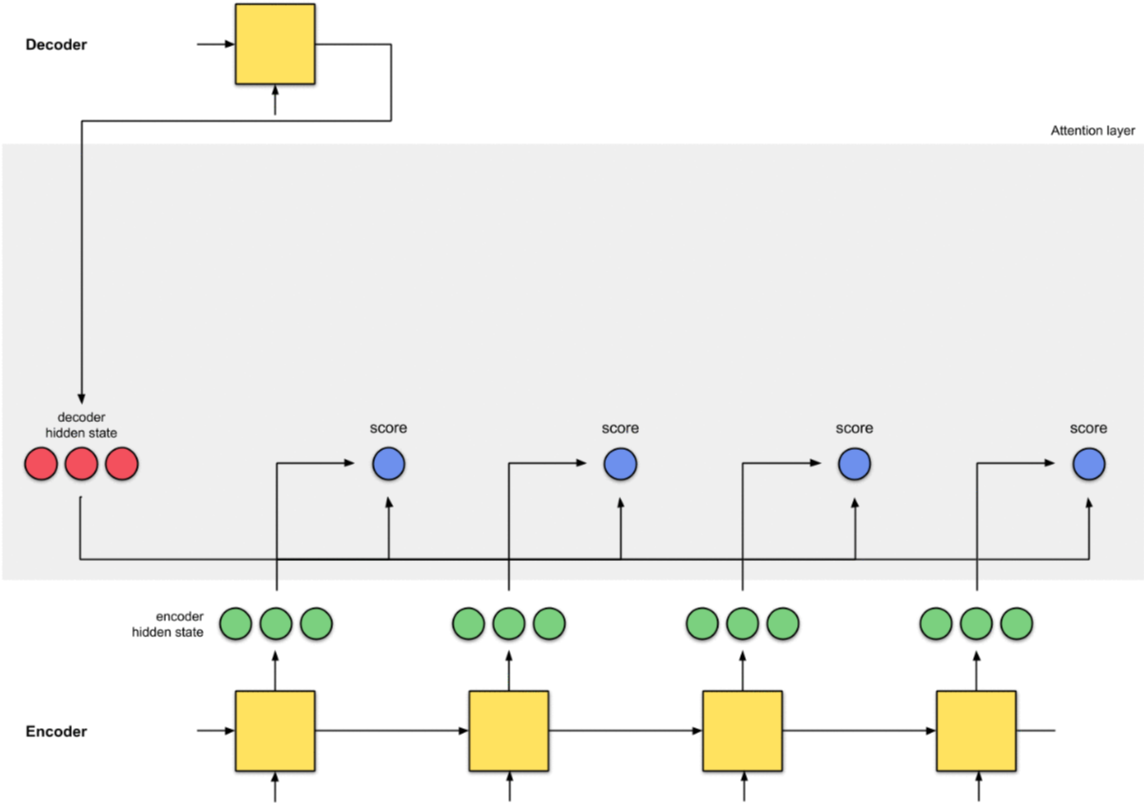
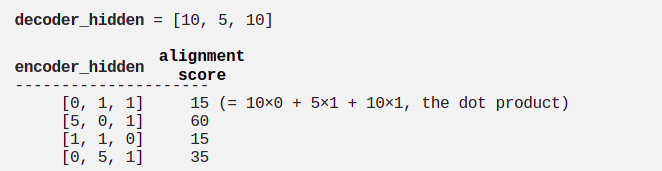
Theo kết quả trên, chúng ta đạt được Alignment Score cao nhất là 60 tại TimeStep thứ 2 của Encoder (Hidden State là [5,0,1]). Điều này có nghĩa là Output tiếp theo của Decoder sẽ chịu ảnh hưởng nhiều của Hidden State này.
9.3 Bước 3 - Cho Alignment Score qua Softmax Function
Tiếp theo, chúng ta đưa Alignment Scores đi qua hàm Softmax, thu được các giá trị trong khoảng [0,1].
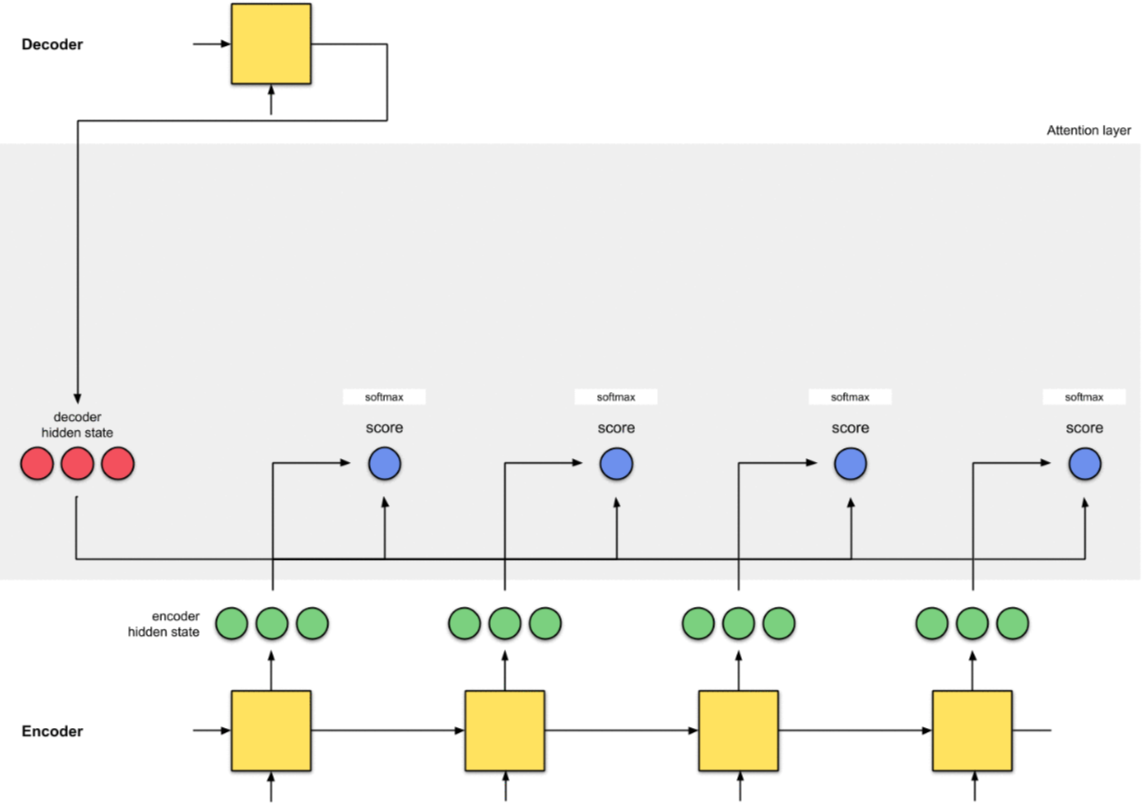

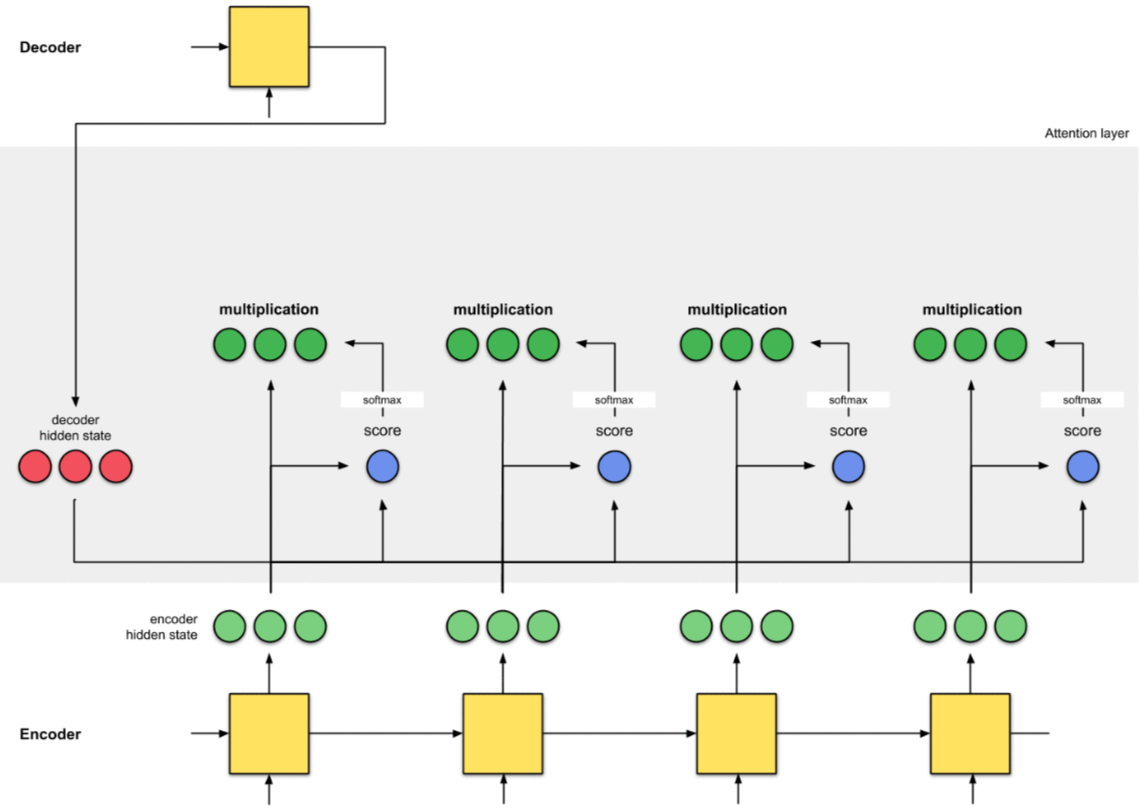
9.4 Buớc 4 - Tính Context Vector của mỗi TimeStep
Vector Context được tính bằng cách nhân Encoder Hidden State với Alignment Score (đã đi qua hàm Softmax) tương ứng của nó.

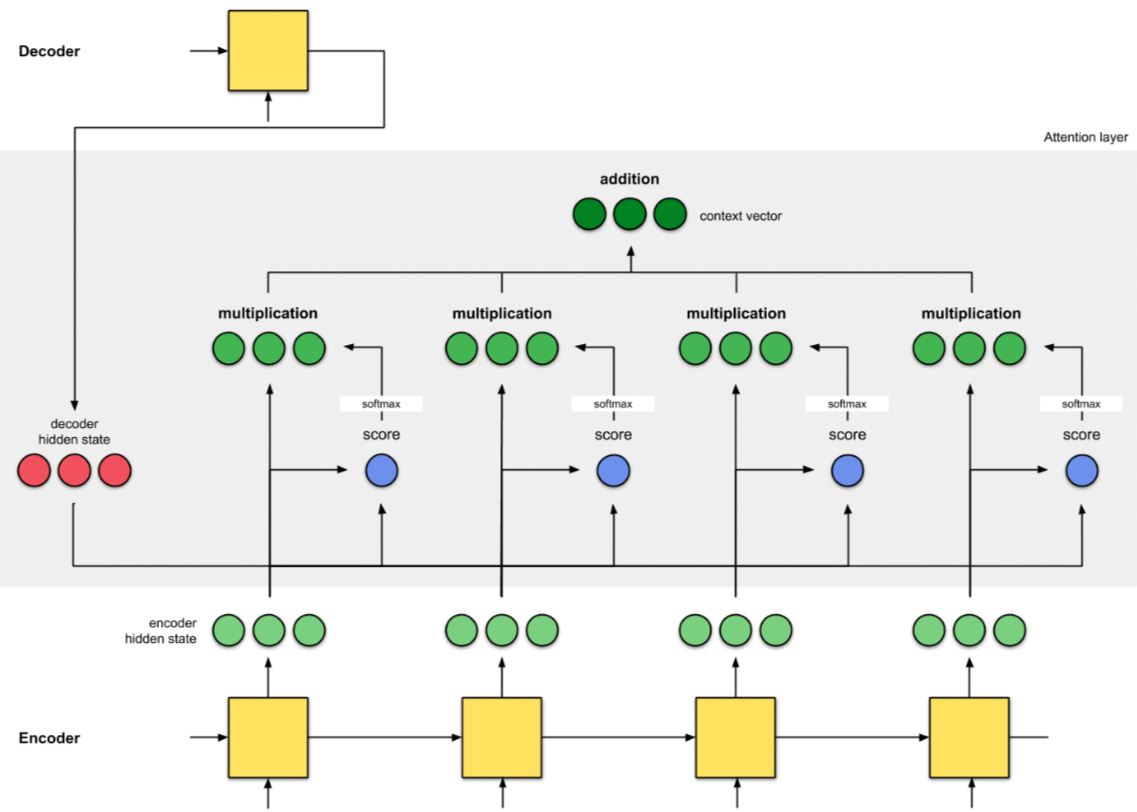
9.5 Bước 5 - Tính tổng của các Context Vector
Các Context Vector tại mỗi TimeStep được cộng lại với nhau, tạo thành 1 Context Vector chung cho toàn bộ Input Sequence.

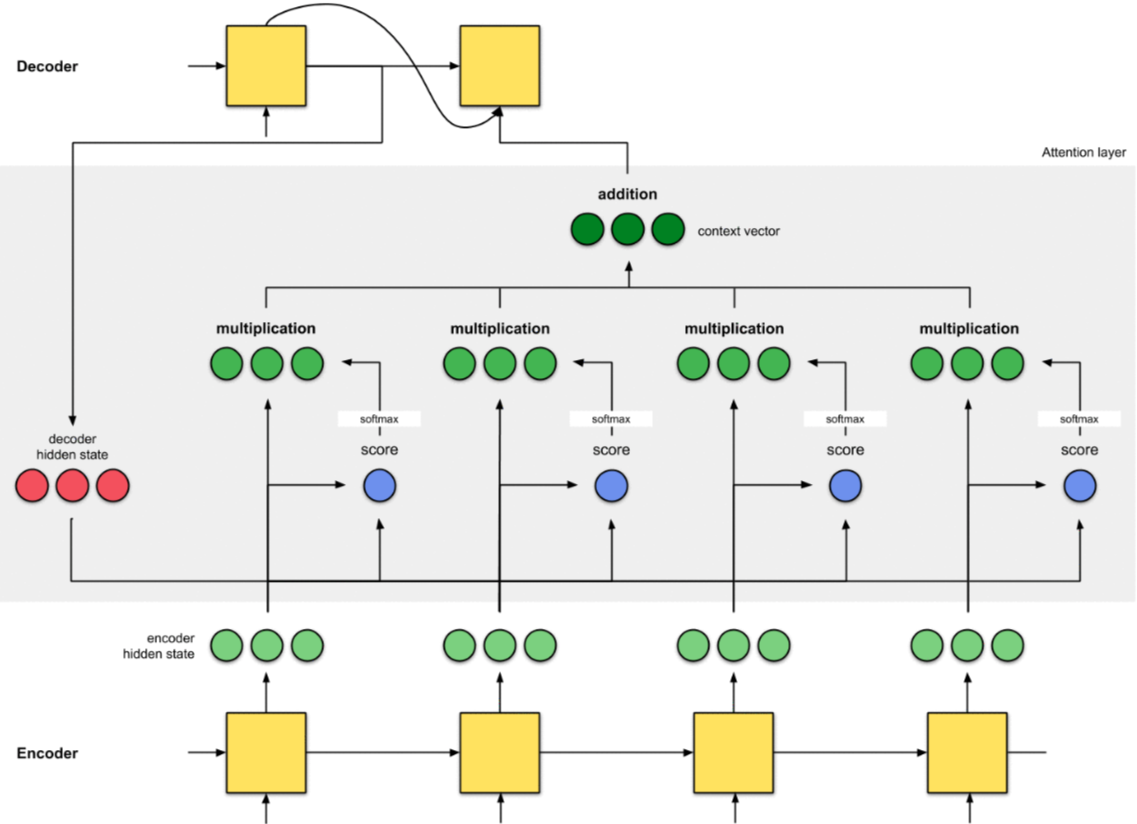
9.6 Bước 6 - Sử dụng Context Vector cho Decoder
Đến đây, ta đã được Context Vector đầy đủ của toàn bộ Input Sequence. Chúng ta sẽ đưa nó vào Decoder để sử dụng tạo ra Output mới.
10. Kết luận
Trong bài này, chúng ta đã cùng nhau tìm hiểu khá chi tiết về cơ chế Attention áp dụng cho mô hình Seq2Seq với kiến trúc Encoder-Decoder.
Ở bài tiếp theo, mình sẽ tiếp tục giới thiệu về Self_Attention và Multi-head Sefl-Attention. Hiểu được 2 lại Attention này là điều kiện tiền để để chúng ta có thể tiếp tục với mô hình Transformer. Mời các bạn đón đọc.
11. Tham khảo