Tìm hiểu bài toán Automatic Speech Recognition (ASR)
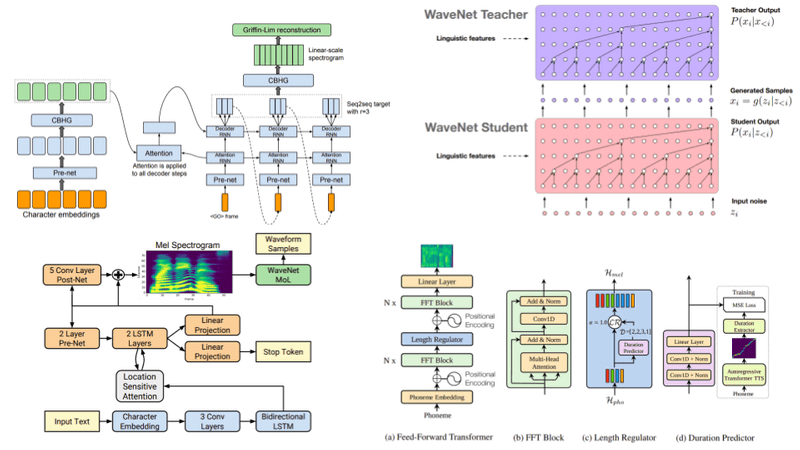
Đây là bài cuối cùng trong chuỗi 6 bài về Audio Deep Learning. Trong bài này, chúng ta sẽ tổng hợp lại các kiến trúc mô hình DL để giải quyết bài toán Speech Synthesis.
Speech Synthesis là bài toán sinh ra Speech từ một văn bản cho trước. Một số ứng dụng của nó như: tổng đài trả lời tự động, đọc báo tự động, …
Trước khi các kỹ thuật DL phát triển, đã có một vài phương pháp truyền thống được đưa ra để giải quyết bài toán này. Nổi bật trong số đó là 2 phương pháp Concatenation Synthesis và Parametric Synthesis. Cũng giống như nhiều bài toán khác, các phương pháp này thường mang lại hiệu quả không cao, khó áp dụng được vào thực tế. Với sự bùng nổ của kỷ nguyên AI trong thời đại ngày nay, có khá nhiều kiến trúc mô hình DL được đề xuất cho bài toán này. Chúng ta sẽ lần lượt tìm hiểu về chúng ngay sau đây.
1. Metric đánh giá DL model
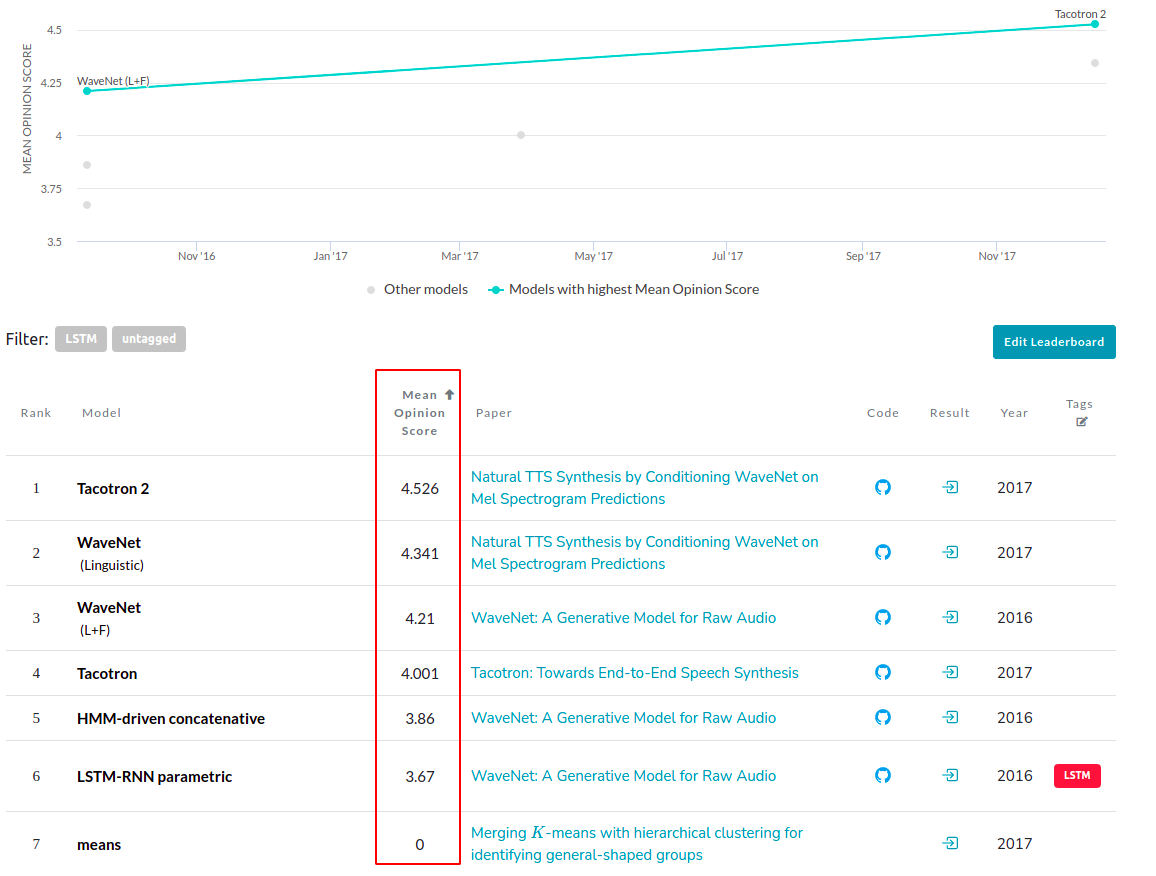
Trước khi đi vào tìm hiểu chi tiết từng kiến trúc mô hình DL, chúng ta nên biết qua về Metric dùng để đánh giá các mô hình này. Metric đó có tên là Mean Opinion Score (MOS). Nó xuất phát từ lĩnh vực viễn thông (Telecommunication), có dải giá trị từ 0 đến 5, tương ứng với chất lượng âm thanh tăng dần. Về bản chất, MOS là trung bình ý kiến đánh giá của nhiều người đối với âm thanh đó. Hãy nhớ lại, khi chúng ta thực hiện cuộc gọi audio/video qua ứng dụng Skype hoặc Facebook, sau khi kết thúc cuộc gọi luôn xuất hiện màn hình yêu cầu chúng ta đánh giá chất lượng cuộc gọi đó. Khi thu thập được đủ số lượng ý kiến đánh giá, nhà phát triển sẽ tính toán ra được MOS.
Dưới đây là bảng so sánh MOS của một số kiến trúc mô hình từ trang paperwithcode
7. Kết luận
Như vậy là chúng ta đã kết thúc bài thứ 5 tại đây. Qua bài này, chúng ta đã hiểu được phần nào rõ hơn về bài toán ASR, từ kiến trúc cho đến cách làm việc
Trong bài tiếp theo, bài cuối cùng trong chuỗi bài về Audio Deep Learning, chúng ta sẽ tìm hiểu một số thuật toán, kiến trúc mô hình của bài toán tổng hợp tiếng nói - Speech Synthesis hay Text-to-Speech. Mời các bạn đón đọc.
8. Tham khảo
[1] Ketan Doshi, “Audio Deep Learning Made Simple: Automatic Speech Recognition (ASR), How it Works”, Available online: https://towardsdatascience.com/audio-deep-learning-made-simple-automatic-speech-recognition-asr-how-it-works-716cfce4c706 (Accessed on 05 Jun 2021).
[2] Scott Duda, “Urban Environmental Audio Classification Using Mel Spectrograms”, Available online: https://scottmduda.medium.com/urban-environmental-audio-classification-using-mel-spectrograms-706ee6f8dcc1 (Accessed on 05 Jun 2021).