Text Recognition với CRNN và CTC
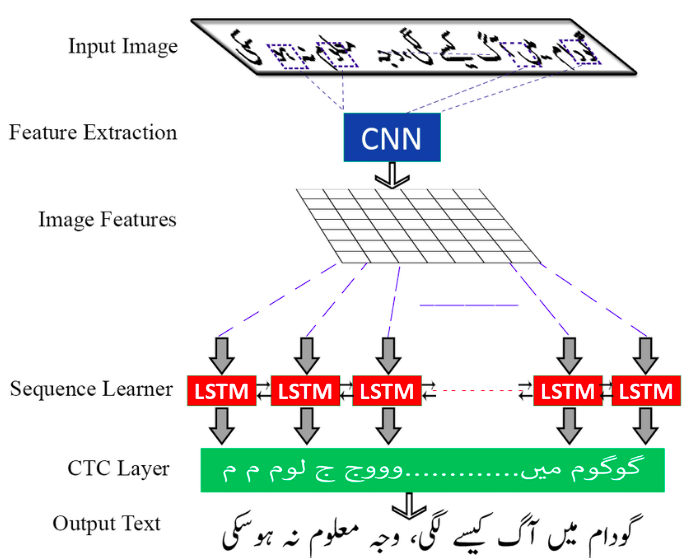
1. CRNN Model
Convolutional Recurrent Neural Network (CRNN) là một kiến trúc được thiết kế chuyên biệt để giải quyết nhiệm vụ Text Recognition trong bài toán OCR. Xuất hiện trong bài báo An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition xuất bản năm 2015, cho đến nay, nó vẫn được coi là một trong những model hiệu quả nhất cho việc thực hiện Text Recognition.
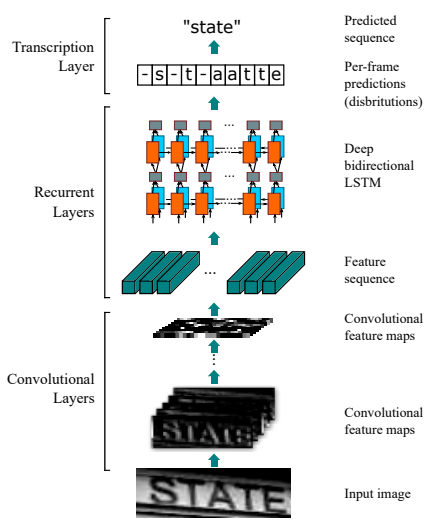
CRNN, đúng như cái tên của nó, là sự kết hợp giữa CNN và RNN. Đây là một sự cộng sinh rất hợp lý bởi vì nhiệm vụ của nó là nhận một bức ảnh đầu vào và cho ra một văn bản chứa trong bức ảnh đó. Nhắc đến xử lý ảnh thì CNN chắc chắn không thể thiếu, và xử lý văn bản thì RNN cũng là ứng cử viên nặng ký. Kiến trúc của CRNN chia thành 3 phần rõ rệt.
1.1 Convolutional Layers
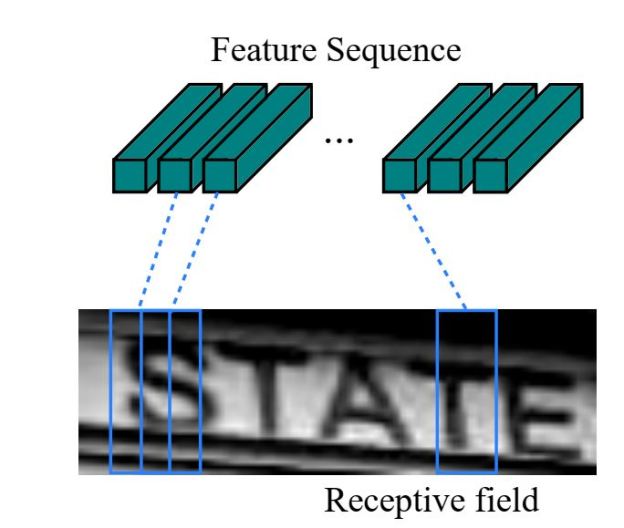
Ảnh đầu vào được cho đi qua các lớp Conv, sinh ra các Feature Maps. Các Feature Maps sau đó lại được chia ra thành một chuỗi của các Feature Vectors (các TimeSteps), gọi là Feature Sequence.
1.2 Recurrent Layers
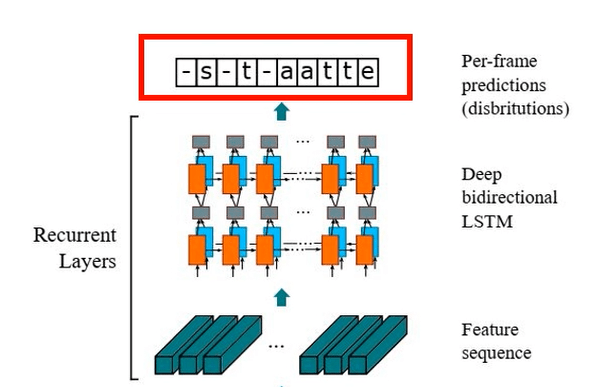
Feature Sequence được đưa vào các lớp Bidirectional LSTM, sinh ra một chuỗi các ký tự (Seq2Seq), mà mỗi một ký tự tương ứng với một TimeStep trong Feature Sequence. Về lý thuyết thì đây chính là văn bản đầu ra cần xác định. Tuy nhiên, Feature Maps không phải lúc nào cũng được chia chính xác thành các Feature Vectors, mà mỗi Feature Vector chứa đúng 1 ký tự cần nhận diện, nên chuỗi đầu ra của LSTM cũng rất lộn xộn: trùng lặp, không có ký tự, …
1.3 Transcription Layers
Nhiệm vụ của phần này là xử lý đầu ra của Recurrent Layers, sắp xếp lại các ký tự, loại bỏ các lỗi tồn tại (alignment) để đưa ra kết quả cuối cùng.
Một số hướng tiếp cận của Transcription Layers như sau:
- Cách 1 - Quy định mỗi ký tự tương ứng với một số cố định TimeSteps. Ví dụ, chúng ta có 10 TimeSteps, tương ứng với Output là State thì ta sắp xếp các TimeSteps như sau: “S, S, T, T, A, A, T, T, E, E”. Cách này đơn giản nhưng chỉ đúng khi kích thước, kiểu chữ, … của văn bản không đổi.
- Cách 2 - Đánh nhãn cho mỗi TimeStep như hình bên dưới, rồi huấn luyện model sử dụng dữ liệu này.

Cách này có vẻ chính xác hơn, nhưng nhược điểm là tốn rất nhiều thời gian cho việc tạo dữ liệu.
- Cách 3 - Sử dụng Connectionist Temporal Classification (CTC)
CTC ra đời từ năm 2006 để giải quyết vấn đề Alignment (chính là vấn đề ánh xạ từ Output của RNN ra kết quả cuối cùng) cho các bài toán OCR, Speech Recognition, … một cách hiệu quả. Chúng ta sẽ tìm hiểu chi tiết về nó trong phần 2 dưới đây.
Để nâng cao hiệu quả của CRNN, chúng ta có thể thêm vào một lớp Attention ở giữa hai lớp CNN và RNN. Cơ chế hoàn toàn giống như trong bài Tìm hiểu cơ chế Attention trong mô hình Seq2Seq.
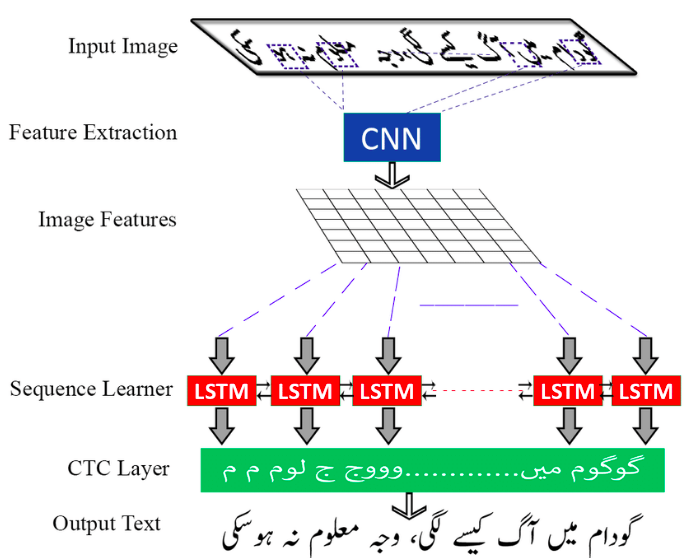
2. Connectionist Temporal Classification
CTC đơn giản là một Loss Function được sử dụng để huấn luyện các Deep Learning model. Mục tiêu của nó là tìm ra cách ánh xạ (alignment) giữa một Input X và Output Y. Nó không yêu cầu Aligned Data (dữ liệu được gắn nhãn cụ thể cho mỗi TimeStep), bởi vì nó có thể đưa ra được xác suất cho mỗi khả năng Align từ X sang Y. Nó chỉ yêu cầu đầu vào là một hình ảnh (ma trận Feature của hinh ảnh) và đoạn Text tương ứng với hình ảnh đó.

Thực chất, bản thân CTC cũng ko biết chính xác cách Alignment giữa X và Y. Nó làm việc theo kiểu Work Arround, tức là nếu đưa cho nó X thì nó sẽ trả lại cho ta tất cả các khả năng của Y, kèm theo xác suất chính xác của mỗi khả năng đó. Chúng ta cần huấn luyện model sao cho:
Trong đó $Y^*$ là kết quả đầu ra cuối cùng mà ta mong đợi, nó càng giống với nhãn (Ground Trust - GT) càng tốt.
Quá trình làm việc của CTC bao gồm 3 bước:
2.1 Encoding Text
Lý tưởng thì mỗi TimeStep sẽ tương ứng với một ký tự. Nhưng nếu không phải vậy thì sao, nếu một ký tự tồn tại trong cả 2 TimeSteps thì sao? Khi đó, kết quả sẽ xuất hiện các ký tự trùng nhau. CTC giải quyết vấn đề này bằng cách gộp tất cả các ký tự trùng nhau thành một. Ví dụ: ttiien ssuu -> tien su.
Tuy nhiên, nếu làm như vậy thì những từ mà bản thân nó có các ký tự trùng nhau thì sao? Ví dụ: hello, sorry, … Để tiếp tục xử lý vấn đề, CTC sử dụng một ký tự giả, gọi là blank và ký hiệu là “-”. Trong khi mã hóa Text, nếu gặp 2 ký tự trùng nhau, CTC sẽ chèn thêm kí tự blank vào giữa chúng. Ví dụ: meet -> mm-ee-ee-t, mmm-e-ee-tt. Trong quá trình Decoding Text, nếu gặp ký tự blank này thì CTC hiểu rằng phải giữ lại cả 2 ký tự 2 bên ký hiệu đó.
2.2 Loss Calculate
Loss được tính toán cho mỗi Training Sample (một cặp ảnh và GT Text tương ứng). Nó là tổng tất cả các Scores của tất cả các khả năng Alignments của GT Text. Giả sử chúng ta có một ma trận Score là Ouput của CRNN như sau:
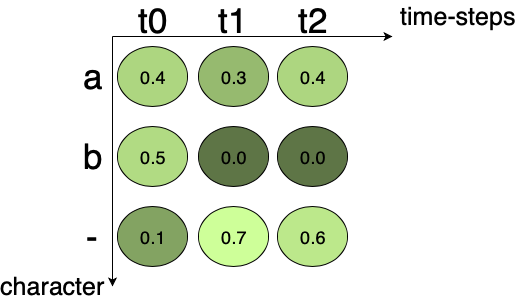
Ma trận này gồm 2 TimeSteps, và GT Text có 3 ký tự: a, b và ký tự blank (-). Tổng Score tại mỗi TimeStep bằng 1. Giả sử:
- Các khả năng Alignment của ký tự a là: aaa, a–, a-, aa-, -aa, –a –> Score của *a = 0.4x0.3x0.4 + 0.4x0.7x0.6 + 0.4x0.7 + 0.4x0.3x0.6 + 0.1x0.3x0.4 + 0.1x0.7x0.4 = 0.608. * –> Loss = $-\log_{10}0.6084 = 0.216$
- Các khả năng Alignment của ký tự b là: bbb, b–, b-, bb-, -bb, –b –> Score của b = 0.5x0.0x0.0 + 0.5x0.7x0.6 + 0.5x0.7 + 0.5x0.0x0.6 + 0.1x0.0x0.0 + 0.1x0.7x0.0 = 0.56 –> *Loss = * $\log_{10}0.56 = 0.25$
- Các khả năng Alignment của ký tự blank là: –, — -> Score của blank = 0.1x0.7 + 0.1x0.7x0.6 = 0.112 –> Loss = $-\log_{10}0.112 = 0.95$
Tổng Loss = 0.216 + 0.25 + 0.95 = 1.416.
Chúng ta cần tối thiểu hóa giá trị Loss này trong quá trình huấn luyện model, sử dụng thuật toán Backpropagation và SGD.
2.3 Decoding Text
Quá trình Decoding một Unseen Image diễn ra như sau:
- Tìm đường đi tối ưu nhất từ Score Matrix bằng cách chọn các ký tự có Score cao nhất tại mỗi TimeStep.
- Xóa bỏ các ký tự trống, ký tự trùng lặp.
Xem thử ví dụ sau:

Có 3 ký tự là a. b, - và 5 TimeSteps. Các ký tự trên đường đi tối ưu nhất là: aaa-b. Sau khi loại bỏ ký tự trùng và khoảng trắng ta được ab.
3. Kết luận
Bài này, mình đã giới thiệu đến các bạn những kiến thức khái quát về CRNN model, về CTC Loss dùng cho nhiệm vụ Text Recognition của bài toán OCR: kiến trúc, cách làm việc …
Souce Code ví dụ của CRNN + CTC, các bạn có thể tham khảo tại đây.
Ở bài tiếp theo, chúng ta sẽ chuyển qua tìm hiểu về bài toán Object Detection. Mời các bạn đón đọc.
4. Tham khảo
[1] B.Shi, X.Bai, C.Yao, An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition. arXiv preprint arXiv:1507.05717.
[2] TheAILearner, “CTC – Problem Statement”, Available online: https://theailearner.com/2021/03/10/ctc-problem-statement/ (Accessed on 07 May 2021).
[3] Harald Scheidl, “An Intuitive Explanation of Connectionist Temporal Classification”, Available online: https://towardsdatascience.com/intuitively-understanding-connectionist-temporal-classification-3797e43a86c (Accessed on 07 May 2021).
[4] Siddhant, “Explanation of Connectionist Temporal Classification”, Available online: https://sid2697.github.io/Blog_Sid/algorithm/2019/10/19/CTC-Loss.html (Accessed on 07 May 2021).