Transformers - Nhưng không phải là kẻ hủy diệt …

Nếu bạn là dân ngoại đạo, bạn cũng có thể đã từng nghe về Transformers. Đó là một bộ phim bom tấn, liên tục lập kỷ lục phòng vé tại thời điểm nó ra mắt. Tuy nhiên, Transformers mình muốn nói ở đầy là một AI model. Được giới thiệu lần đầu vào năm 2017 trong bài báo Attention is all you need, cũng như bộ phim kia, nó cũng lập tức gây chấn động cộng động NLP lúc bấy giờ bởi hiệu năng của nó hơn hẳn so với các kiến trúc mô hình tồn tại trước đó trong các thử nghiệm được công bố.
1. So sánh Transformers và họ hàng nhà RNN (LSTM, GRU)
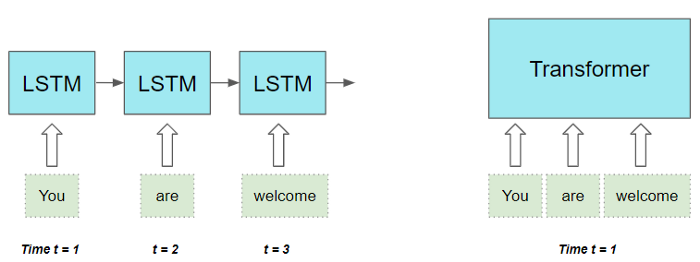
Đầu tiên, chúng ta thử so sánh Transformers với họ hàng RNN để thấy được ưu điểm của nó, và hiểu tại sao nó lại được yêu mến đến vậy.
Như chúng ta đã biết, kiến trúc Encoder-Decoder với RNN truyền thống tồn tại 2 nhược điểm:
- Không có khả năng tận dụng hết thông tin ngữ nghĩa của Input và Targer Sequence, đặc biệt là trong trường hợp Input Sequence có chiều dài lớn (Với cơ chế Attention, khả năng này có tốt hơn một chút nhưng vẫn chưa đủ).
- Vì phải xử lý tuần tự từng TimeStep một nên thời gian tính toán rất lâu.
Transformers giải quyết được 2 nhược điểm đó bằng cách:
- Sử dụng cơ chế Self-Attention (nhiều tầng Self-Attentions) để nắm bắt tốt hơn thông tin ngữ nghĩa của Input và Targer Sequence.
- Xử lý song song tất cả các TimeStep cùng một lúc –> Giảm được rất nhiều thời gian tính toán.
2. Kiến trúc và thành phần của Transformers
Transformer tỏ ra vượt trội trong việc xử lý dữ liệu văn bản vốn có tính chất tuần tự. Nó lấy một chuỗi văn bản làm đầu vào và tạo ra một chuỗi văn bản khác. Ví dụ như bài toán Machine Translation hay Text Summarization.
Về thành phần cấu tạo, Transformers bao gồm một nhóm các bộ Encoders (Encoder stack) và một nhóm các bộ Decoder (Decoder stack). Ngoài ra còn có các thành phần Embedding, Encoding, Mask, … khác để xử lý dữ liệu đầu vào và đầu ra.
2.1 Positional Encoder
Việc xử lý đồng thời tất cả cá từ trong câu một lượt mang lại khả năng tính toán nhanh chóng cho Transformers, nhưng nó lại vô tình làm mất thông tin về vị trí của các từ trong câu đó. Để khắc phục vấn đề này, thông tin về vị trí của từ được mã hóa thành Positional Encoding (PE) vector để làm đầu vào cho Transformers.
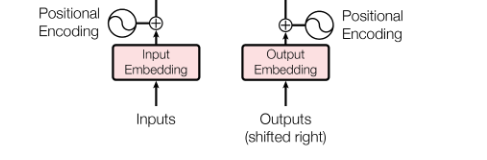
PE được tính như sau:
$PE_{(pos,2i)} = sin(\frac{pos}{1000^{\frac{2i}{d}}})$
$PE_{(pos,2i+1)} = cos(\frac{pos}{1000^{\frac{2i}{d}}})$
Trong đó, $pos$ là vị trí của từ trong câu, còn $i$ là chỉ số của các phần tử trong PE vector, $d$ là số chiều của Work/Token Embedding (cũng bằng với kích thước của PE).
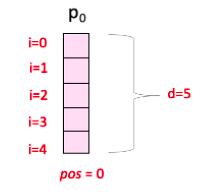
Trong khi $d$ cố định thì $pos$ và $i$ thay đổi. PE cuối cùng là tổng hợp của tất cả các PE với sự thay đổi của $pos$ và $i$ đó.
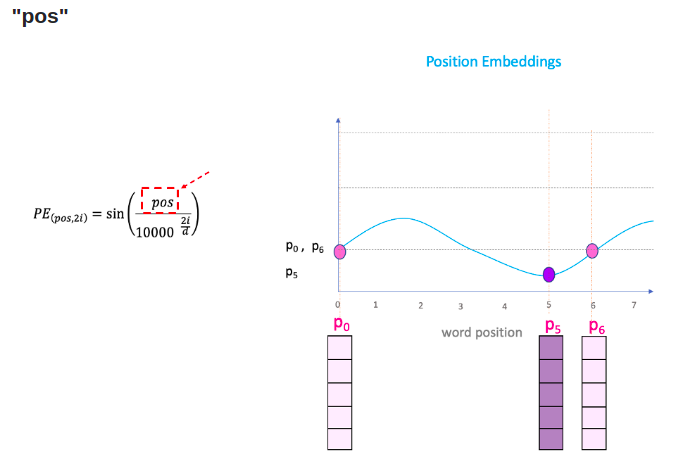
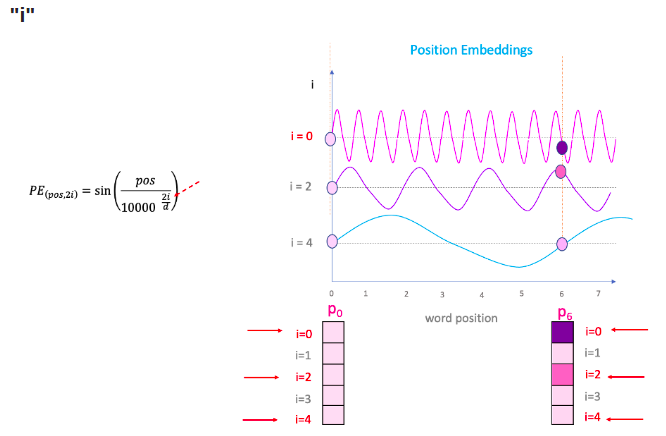
Chi tiết thêm về Positional Encoding, các bạn có thể tham khảo tại đây.
2.2 Masking
Mục đích chính của Masking là che giấu (Mask) đi phần thông tin của Token phía sau, chỉ cho phép Decoder sử dụng thông tin của Token hiện tại và trước đó khi tạo Ouput. Ví dụ như trong một kỳ thi, ta cần phải che giấu đáp án đi, chỉ cho phép thí sinh sử dụng kiến thức của họ để làm bài.
Xem xét cách tính Output của Self-Attention như hình dưới đây:
Có 4 bước, chúng ta sẽ đi chi tiết mỗi bước.
- Bước 1
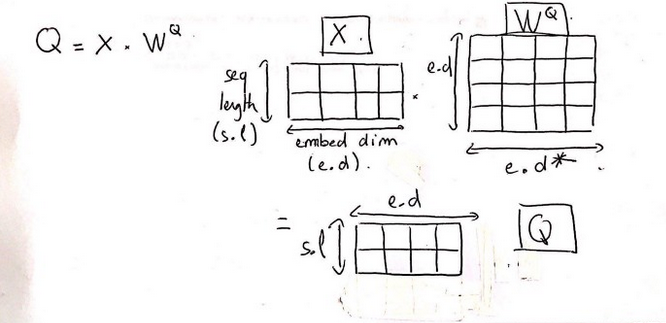
Ma trận Query (Q) được tạo từ Input (X) và ma trận trọng số của Q ($W^Q$). Tương tự cho Key (K) và Value (V).
X có kích thước là (2,4), trong đó 2 là chiều dài của Input Sequence (số từ trong câu), 4 là số chiều của Word Embedding của 1 từ.
$W^Q$ có kích thước là (4,4), trong đó 4 là số chiều của Word Embedding của 1 từ, 4 là do chúng ta giả sử $W^Q$ là ma trận vuông cho dễ xử lý. Thực tế có thể phức tạp hơn.
Kết quả, các ma trận Q, V, K có kích thước (2, 4).
- Bước 2
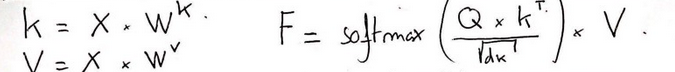
Đây chính là công thức tính Output của Self-Attention.
- Bước 3
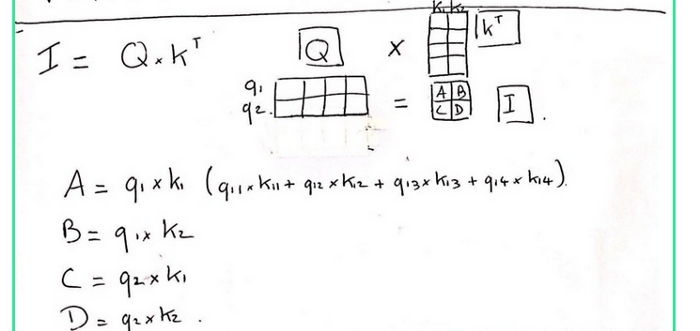
Ta biểu diễn ma trận $I = Q \times K^T$ bởi các giá trị A, B, C, D. Nhận thấy rằng, A chỉ phụ thuộc vào Embedding Token ở vị trí đầu tiên: $A = q_1 \times k_1 = x_1*W^Q \times k_1$).
Trong khi đó, B phụ thuộc vào Embedding ở vị trí thứ nhất và thứ hai: ($B = q_1 \times k_2 = x_1W^A \times x_2W^K$).
($x_1, x_2$ là các Embedding của Token thứ nhất và thứ hai).
- Bước 4
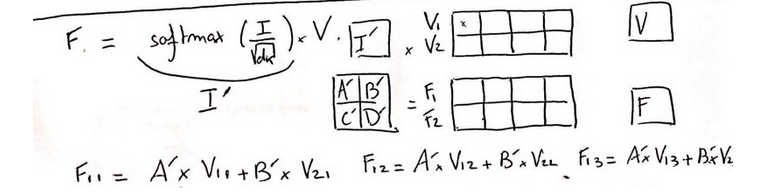
Làm tương tự cho ma trận F. Ta cũng nhận thấy B' phụ thuộc vào Embedding Token của cả hai vị trí 1 và 2. Để ngăn chặn điều này, ta thêm vào Mask như sau:
Ở đó:
Ta được:
Và cuối cùng là:
Như vậy, sau khi thêm Mask vào thì Output F của Decoder đã ko còn xuất hiện thành phần Embedding Token ở vị trí số 2.
2.3 Scaled Dot-Product Attention
Đây chính các phép tính toán của Self-Attention.
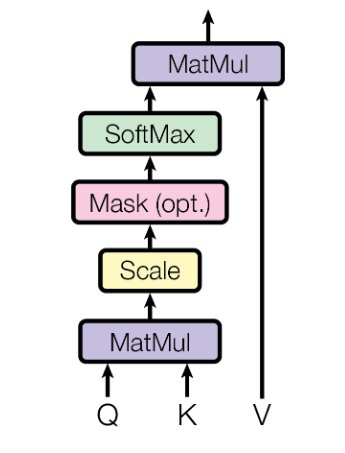
Lần lượt từng bước như sau:
-
Matmul - phép toán Matrix Dot-Product giữa ma trận Query và chuyển vị của ma trận Key.
$MatMul(Q,K) = Q.K^T$
-
Scale - Ouput của phép toán Dot-Product có thể là một giá trị rất lớn, có thể làm rối loạn hoạt động của hàm Softmax. Do vậy, ta Scale chúng bằng cách chia cho hệ số $\sqrt(d_k)$.
-
Mask - như đã đề cập ở mục 2.2.
-
Softmax - Đưa giá trị về một phân phối xác suất trong khoảng [0,1].
$Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt(d_k)})V$
2.4 Multi-Head Self-Attention
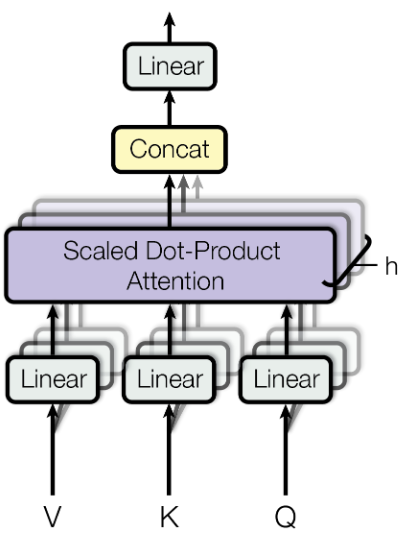
Xem lại bài trước.
2.5 Point-Wise Feed Forward Network and Residual Dropout
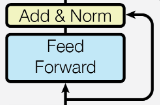
Point-Wise Feed Forward Network Block, về cơ bản là một phép biến đổi tuyến tính hai lớp được sử dụng giống nhau trong toàn bộ kiến trúc mô hình, thường là sau các khối Attention.
Để áp dụng Regularization, một Dropout được áp dụng tại đầu ra của mỗi Sub-layer, trước khi nó được đưa vào làm Input cho Sub-layer tiếp theo.
3. Huấn luyện mô hình Transformers
Dữ liệu huấn luyện bao gồm 2 thành phần: Input Sequence và Target Sequence. Quá trình huấn luyện diễn ra như sau:
- Bước 1 - Input Sequence được biến đổi thành Embedding, cùng với Positional Encoding để đưa vào Encoder Stack.
- Bước 2 - Encoder Stack xử lý và đưa ra một Vector đại diện của Input Sequence, gọi là Context Vector. Vector này sau đó được đưa sang cho Decoder Stack.
- Bước 3 - Target Sequence được bổ sung thêm tiền tố START_ (*còn gọi là start-of-sentence token*), chuyển đổi thành Embedding, cùng với Positional Decoding, đưa vào Decoder Stack.
- Bước 4 - Decoder Stack xử lý, sinh ra một Vector đại diện của Target Sequence.
- Bước 5 - Output Layer chuyển Vector đại diện này một Output Sequence.
- Bước 6 - Transformers Loss Function so sánh Output Sequence với Target Sequence. Loss sẽ được sử dụng để sinh ra Gradients để cập nhật trọng số mô hình trong quá trình Back-propagation.
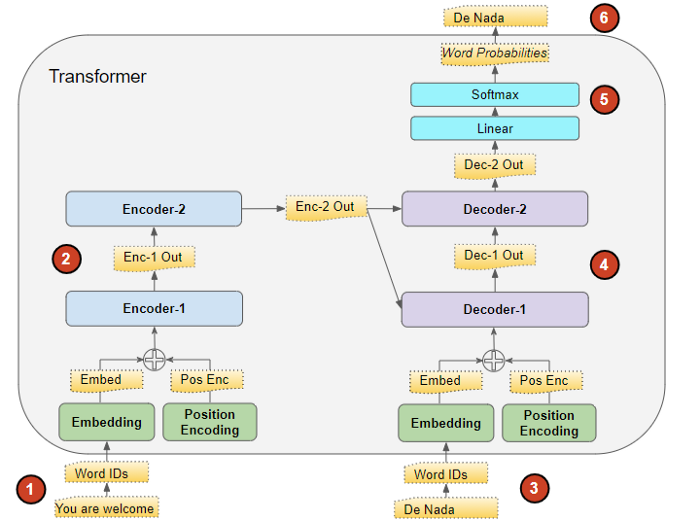
Cách thức huấn luyện như thế này còn được gọi với cái tên là Teacher Forcing. Target Sequence ở đây đóng vai trò là Teacher để Force mô hình hoạt động đúng như mong muốn. Cá nhân mình thấy, nó khá giống với phương pháp Supervise Learning mà chúng ta đã quen thuộc.
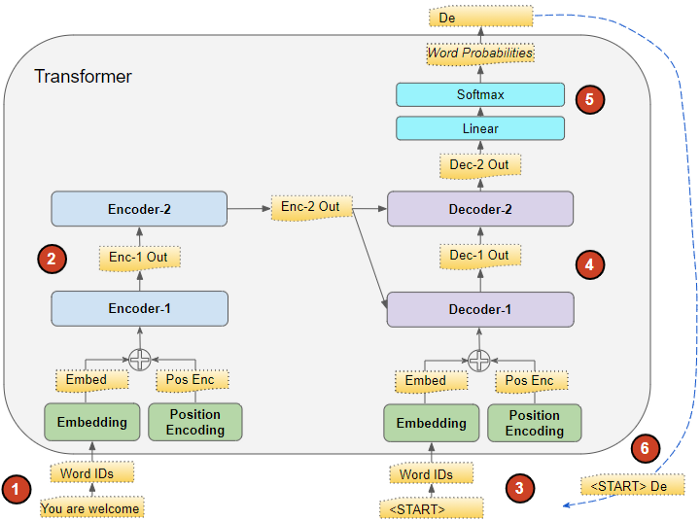
4. Sử dụng mô hình Transformers để dự đoán (Inference) 3 Quá trình dự đoán của Transformers có một chút khác biệt so với quá trình huấn luyện của nó. Chúng ta chỉ có Input Sequence, không có Target Sequence. Mục đích của Inference là sinh ra Output Sequence từ Input Sequence.
Trong mô hình Seq2Seq, Output của Decoder Stack được sinh ra trong một vòng lặp, Ouput từ TimeStep trước được đưa vào làm Input của TimeStep tiếp theo. Vòng lặp kết thúc khi Output là Token kết thúc (_END). Còn trong mô hình Transformers, tại mỗi TimeStep, toàn bộ Output tại các thời điểm trước đó được đưa vào làm Input cho thời điểm tiếp theo, thay vì chỉ sử dụng Output cuối cùng.
Toàn bộ quá trình Inference diễn ra như sau:
- Bước 1 - Input Sequence đuọc chuyển thành Embedding, cùng với Positional Decoding, đưa vào Encoder Stack.
- Bước 2 - Encoder Stack xử lý và tạo ra Context Vector. Vector này được chuyển sang cho Decoder Stack.
- Bước 3 - Phía Decoder Stack, sử dụng một Input Sequence rỗng (*chỉ có một Start Token - START_*), chuyển sang Embedding, cùng với Positional Encoding, đưa vào Decoder Stack.
- Bước 4 - Decoder Stack xử lý, cùng với Context Vector từ Encoder Stack, sinh ra Vector đại diện của Output Sequence.
- Bước 5 - Output Layer biến đổi Vector đại diện này thành Output Sequence.
- Bước 6 - Từ cuối cùng trong Output Sequence đặt vào vị trí thứ 2 (sau Start Token) của Input Sequence của Decoder Stack. Sau đó, Intput Sequence mới này lại được đưa vào Decoder Stack.
- Bước 7 - Lặp lại từ bước 4-6 cho đến khi bắt gặp từ cuối cùng trong Ouput Sequence là End Token (_END).
5. Ứng dụng của Transformers
Transformers được sử dụng rất rộng rãi ở hầu hết các bài toán trong lĩnh vực NLP. Với mỗi bài toán, chúng ta sẽ sử dụng một biến thể khác của Transformers.
-
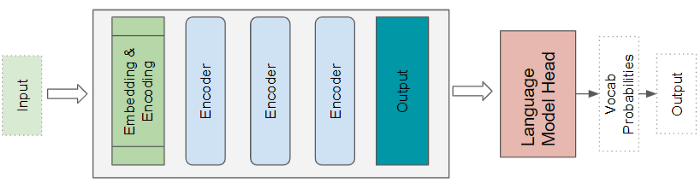
Language models - Đây là bài toán sinh ra từ mới cho câu (sáng tác nhạc, làm thơ, viết truyện, …). Ở đây, chỉ thành phần Encoder Stack của Transformers được sử dụng, như là một bộ trích xuất đặc trưng (Sequence Embedding) của Input Sequence. Đầu ra của Encoder Stack được đưa vào Language Model để cho ra một xác suất cho mỗi từ trong từ điển. Từ có xác suất cao nhất là kết quả cuối cùng.
-
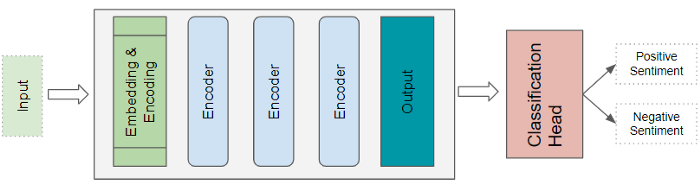
Text Classification - Đây là bài toán phân loại văn bản thành các chủ đề, nhãn, … khác nhau. Tương tự Language Model, chúng ta cũng chỉ sử dụng phần Encoder Stack cho ứng dụng này. Đầu ra của Encoder Stack được đưa vào bộ phân lớp, cho ra xác suất của từng nhãn. Nhãn có xác suất cao nhất sẽ được công nhận là kết quả chung cuộc.
-
Seq2Seq models - Đây là lớp bài toán bao gồm Machine Translation, Text Summarization, Question-Answering, Named Entity Recognition, Speech Recognition, …
Kiến trúc đầy đủ của Transformers được sử dụng trong các ứng dụng này.
5. Kết luận
Trong bài này, chúng ta đã cùng nhau tìm hiểu khá chi tiết về kiến trúc Transformers, cũng như các ưu/nhược điểm và ứng dụng của nó.
Ở bài tiếp theo, mình sẽ giới thiệu về của BERT, một state of the art language model for NLP. Mời các bạn đón đọc.
6. Tham khảo