DP4ML - Feature Selection - Phần 6 - How to Use Feature Importance
Bài thứ 13 trong chuỗi các bài viết về chủ đề Data Preparation cho các mô hình ML và là bài thứ 6 về Feature Selection. Trong bài này, chúng ta sẽ tìm hiểu về Feature Importance và cách sử dụng nó để lựa chọn features thông qua việc thực hành trên một bộ dữ liệu giả được sinh ra ngẫu nhiên.
1. Feature Importance Score (FIS)
Feature Importance đề cập đến các kỹ thuật xác định điểm số - score cho các features dựa trên cách mối liên hệ của chúng với target. Có nhiều loại và cách tính score cho các features như Statistic Correlation Score, Coeficients Score, Permutatation Score, … FIS đóng một vai trò quan trọng trong việc mô hình hóa dữ liệu, nó giúp chúng ta có cái nhìn sâu sắc về dữ liệu, về mô hình và là cơ sở để thực hiện Feature Selection.
Trong bài này, chúng ta sẽ thực hiện tính toán FIS theo ba cách:
- FIS from model coefficients
- FIS from Decision Tree
- FIS from Permutation Testing
2. Create Test Data
Trước tiên, chúng ta sẽ tạo ra 2 bộ dữ liệu để thực hành. Một bộ cho bài toán Classification và 1 bộ cho bài toán Regression. Cả 2 bộ đều có 1000 mẫu, mỗi mầu có 10 features, 5 features trong số đó là informative, còn lại là redundant.
2.1 Classification Dataset
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1)
# summarize the dataset
print(X.shape, y.shape)
2.2 Regression Dataset
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1)
# summarize the dataset
print(X.shape, y.shape)
3. Coefficients as Feature Importance
Tất cả các thuật toán Regression/Classification như Linear Regression, Logistic Regression, Ridge Regression, LASSO, Elastic Net, … đều sử dụng phương pháp đánh trọng số cho các features để thực hiện phép dự đoán. Các trọng số (coeficients) này có thể được coi là một loại FIS.
3.1 Linear Regression Feature Importance
Chúng ta sẽ thực hiện fit LinearRegression model trên tập Regression dataset và xem các coefficients của nó:
# linear regression feature importance
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from matplotlib import pyplot
# define dataset
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1)
# define the model
model = LinearRegression()
# fit the model
model.fit(X, y)
# get importance
importance = model.coef_
# summarize feature importance
for i,v in enumerate(importance):
print('Feature: %0d, Score: %.5f' % (i,v))
# plot feature importance
pyplot.bar([x for x in range(len(importance))], importance)
pyplot.show()
Kết quả thực hiện:
Feature: 0, Score: -0.00000
Feature: 1, Score: 12.44483
Feature: 2, Score: -0.00000
Feature: 3, Score: -0.00000
Feature: 4, Score: 93.32225
Feature: 5, Score: 86.50811
Feature: 6, Score: 26.74607
Feature: 7, Score: 3.28535
Feature: 8, Score: -0.00000
Feature: 9, Score: 0.00000

Kết quả này nói cho ta biết rằng model tìm thấy 5 Important Features, những features khác có thể được loại bỏ khi mô hình hóa dữ liệu.
3.2 Logistic Regression Feature Importance
# logistic regression for feature importance
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from matplotlib import pyplot
# define dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1)
# define the model
model = LogisticRegression()
# fit the model
model.fit(X, y)
# get importance
importance = model.coef_[0]
# summarize feature importance
for i,v in enumerate(importance):
print('Feature: %0d, Score: %.5f' % (i,v))
# plot feature importance
pyplot.bar([x for x in range(len(importance))], importance)
pyplot.show()
Kết quả thực hiện:
Feature: 0, Score: 0.16320
Feature: 1, Score: -0.64301
Feature: 2, Score: 0.48497
Feature: 3, Score: -0.46190
Feature: 4, Score: 0.18432
Feature: 5, Score: -0.11978
Feature: 6, Score: -0.40602
Feature: 7, Score: 0.03772
Feature: 8, Score: -0.51785
Feature: 9, Score: 0.26540
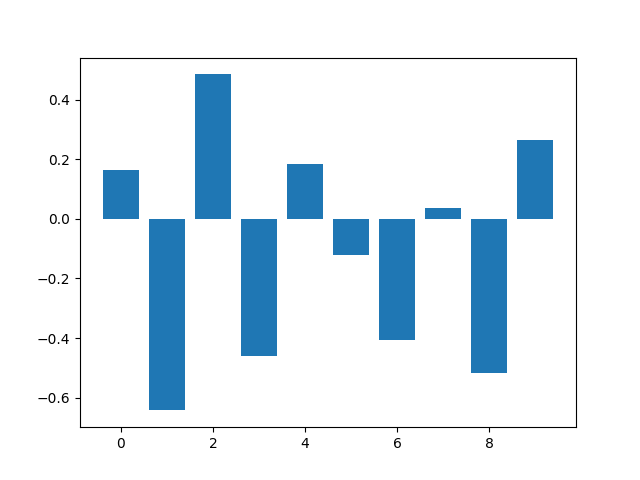
Đối với bài toán Classification và thuật toán Logistic Regression thì các coefficients có cả giá trị âm và dương. Giá trị âm chỉ ra rằng feature đó dự đoán cho class 0, còn giá trị dương chỉ ra rằng feature đó dự đoán cho class 1. Các giá trị coefficients ở đây không thể coi là FIS và không được sử dụng để thực hiện Feature Selection.
4. Decision Tree Feature Importance
Chúng ta sử dụng thuật toán CART được implemented trong scikit-learn (DecisionTreeRegressor và DecisionTreeClassifier). Sau khi fit, model cung cấp thuộc tính *feature_importances_* có thể được sử dụng như là FIS.
4.1 CART Feature Importance
a, CART Regression Feature Importance
# decision tree for feature importance on a regression problem
from sklearn.datasets import make_regression
from sklearn.tree import DecisionTreeRegressor
from matplotlib import pyplot
# define dataset
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1)
# define the model
model = DecisionTreeRegressor()
# fit the model
model.fit(X, y)
# get importance
importance = model.feature_importances_
# summarize feature importance
for i,v in enumerate(importance):
print('Feature: %0d, Score: %.5f' % (i,v))
# plot feature importance
pyplot.bar([x for x in range(len(importance))], importance)
pyplot.show()
Kết quả thực hiện:
Feature: 0, Score: 0.00280
Feature: 1, Score: 0.00485
Feature: 2, Score: 0.00243
Feature: 3, Score: 0.00200
Feature: 4, Score: 0.51685
Feature: 5, Score: 0.43703
Feature: 6, Score: 0.02744
Feature: 7, Score: 0.00259
Feature: 8, Score: 0.00297
Feature: 9, Score: 0.00103

Kết quả chỉ ra có 3/10 Important Features.
b, CART Classification Feature Importance
# decision tree for feature importance on a classification problem
from sklearn.datasets import make_classification
from sklearn.tree import DecisionTreeClassifier
from matplotlib import pyplot
# define dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1)
# define the model
model = DecisionTreeClassifier()
# fit the model
model.fit(X, y)
# get importance
importance = model.feature_importances_
# summarize feature importance
for i,v in enumerate(importance):
print('Feature: %0d, Score: %.5f' % (i,v))
# plot feature importance
pyplot.bar([x for x in range(len(importance))], importance)
pyplot.show()
Kết quả thực hiện:
Feature: 0, Score: 0.02155
Feature: 1, Score: 0.01029
Feature: 2, Score: 0.17994
Feature: 3, Score: 0.29655
Feature: 4, Score: 0.08793
Feature: 5, Score: 0.01210
Feature: 6, Score: 0.18119
Feature: 7, Score: 0.05454
Feature: 8, Score: 0.12754
Feature: 9, Score: 0.02837
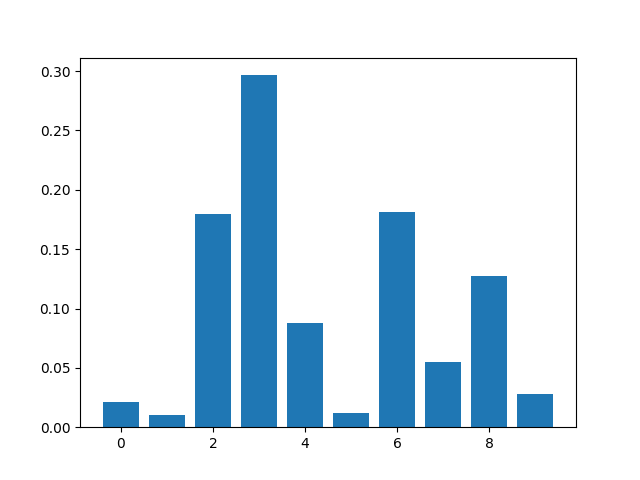
Kết quả chỉ ra có 4-5/10 Important Features.
4.2 Random Forest Feature Importance
a, Random Forest Regression Feature Importance
# random forest for feature importance on a regression problem
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from matplotlib import pyplot
# define dataset
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1)
# define the model
model = RandomForestRegressor()
# fit the model
model.fit(X, y)
# get importance
importance = model.feature_importances_
# summarize feature importance
for i,v in enumerate(importance):
print('Feature: %0d, Score: %.5f' % (i,v))
# plot feature importance
pyplot.bar([x for x in range(len(importance))], importance)
pyplot.show()
Kết quả thực hiện:
Feature: 0, Score: 0.00307
Feature: 1, Score: 0.00553
Feature: 2, Score: 0.00292
Feature: 3, Score: 0.00271
Feature: 4, Score: 0.52968
Feature: 5, Score: 0.42187
Feature: 6, Score: 0.02528
Feature: 7, Score: 0.00298
Feature: 8, Score: 0.00320
Feature: 9, Score: 0.00275
Kết quả chỉ ra chỉ có 2-3/10 Important Features.
b, Random Forest Classification Feature Importance
# random forest for feature importance on a classification problem
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from matplotlib import pyplot
# define dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1)
# define the model
model = RandomForestClassifier()
# fit the model
model.fit(X, y)
# get importance
importance = model.feature_importances_
# summarize feature importance
for i,v in enumerate(importance):
print('Feature: %0d, Score: %.5f' % (i,v))
# plot feature importance
pyplot.bar([x for x in range(len(importance))], importance)
pyplot.show()
Kết quả thực hiện:
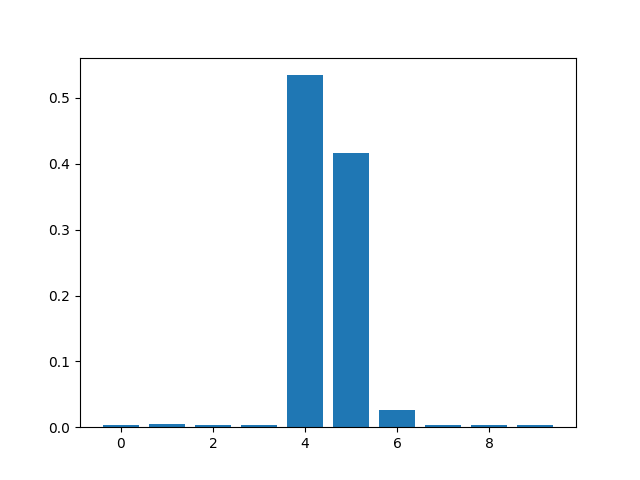
Feature: 0, Score: 0.05545
Feature: 1, Score: 0.11714
Feature: 2, Score: 0.14782
Feature: 3, Score: 0.17944
Feature: 4, Score: 0.08900
Feature: 5, Score: 0.11283
Feature: 6, Score: 0.11459
Feature: 7, Score: 0.04678
Feature: 8, Score: 0.09017
Feature: 9, Score: 0.04678
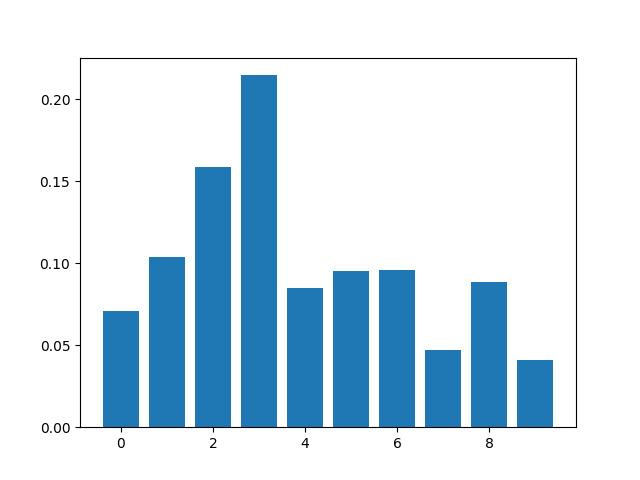
Kết quả chỉ ra có 4-5/10 Important Features.
5. Permutation Feature Importance
5.1 Permutation Feature Importance for Regression
# permutation feature importance with knn for regression
from sklearn.datasets import make_regression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.inspection import permutation_importance
from matplotlib import pyplot
# define dataset
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1)
# define the model
model = KNeighborsRegressor()
# fit the model
model.fit(X, y)
# perform permutation importance
results = permutation_importance(model, X, y, scoring='neg_mean_squared_error')
# get importance
importance = results.importances_mean
# summarize feature importance
for i,v in enumerate(importance):
print('Feature: %0d, Score: %.5f' % (i,v))
# plot feature importance
pyplot.bar([x for x in range(len(importance))], importance)
pyplot.show()
Kết quả thực hiện:
Feature: 0, Score: 203.08837
Feature: 1, Score: 299.90705
Feature: 2, Score: 155.87319
Feature: 3, Score: 31.30704
Feature: 4, Score: 9642.31128
Feature: 5, Score: 8482.24184
Feature: 6, Score: 869.35524
Feature: 7, Score: 148.71948
Feature: 8, Score: 86.35811
Feature: 9, Score: 85.22271
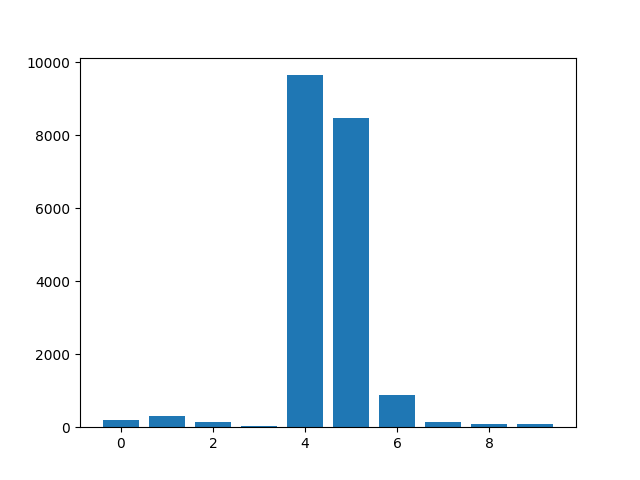
Kết quả chỉ ra có 2-3/10 Important Features.
5.2 Permutation Feature Importance for Classification
# permutation feature importance with knn for classification
from sklearn.datasets import make_classification
from sklearn.neighbors import KNeighborsClassifier
from sklearn.inspection import permutation_importance
from matplotlib import pyplot
# define dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1)
# define the model
model = KNeighborsClassifier()
# fit the model
model.fit(X, y)
# perform permutation importance
results = permutation_importance(model, X, y, scoring='accuracy')
# get importance
importance = results.importances_mean
# summarize feature importance
for i,v in enumerate(importance):
print('Feature: %0d, Score: %.5f' % (i,v))
# plot feature importance
pyplot.bar([x for x in range(len(importance))], importance)
pyplot.show()
Kết quả thực hiện:
Feature: 0, Score: 0.04860
Feature: 1, Score: 0.06240
Feature: 2, Score: 0.05600
Feature: 3, Score: 0.09520
Feature: 4, Score: 0.05200
Feature: 5, Score: 0.05840
Feature: 6, Score: 0.07580
Feature: 7, Score: 0.05880
Feature: 8, Score: 0.06000
Feature: 9, Score: 0.03020

Kết quả chỉ ra có 2-3/10 Important Features.
6. Feature Selection with Importance
Phần này, chúng ta sẽ sử dụng FIS để thực hiện Feature Selection, sau đó sẽ tiến hành mô hình hóa dữ liệu theo các features đã được chọn.
6.1 Base model
Base model sử dụng tất cả features:
# evaluation of a model using all features
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# define the dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1)
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# fit the model
model = LogisticRegression(solver='liblinear')
model.fit(X_train, y_train)
# evaluate the model
yhat = model.predict(X_test)
# evaluate predictions
accuracy = accuracy_score(y_test, yhat)
print('Accuracy: %.2f' % (accuracy*100))
Kết quả thực hiện:
Accuracy: 84.55
6.2 Model with Selected Features
Ta có thể sử dụng bấy kì phương pháp tính FIS bên trên để lựa chọn features. Ở đây, mình sẽ dùng FIS cung cấp bởi Random Forest. Lớp SelectFromModel định nghĩa cả model mà ta muốn sử dụng để tính FIS (RandomForestClassifier) và số lượng tối đa features chúng ta muốn chọn.
# evaluation of a model using 5 features chosen with random forest importance
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# feature selection
def select_features(X_train, y_train, X_test):
# configure to select a subset of features
fs = SelectFromModel(RandomForestClassifier(n_estimators=1000), max_features=5)
# learn relationship from training data
fs.fit(X_train, y_train)
# transform train input data
X_train_fs = fs.transform(X_train)
# transform test input data
X_test_fs = fs.transform(X_test)
return X_train_fs, X_test_fs, fs
# define the dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1)
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# feature selection
X_train_fs, X_test_fs, fs = select_features(X_train, y_train, X_test)
# fit the model
model = LogisticRegression(solver='liblinear')
model.fit(X_train_fs, y_train)
# evaluate the model
yhat = model.predict(X_test_fs)
# evaluate predictions
accuracy = accuracy_score(y_test, yhat)
print('Accuracy: %.2f' % (accuracy*100))
Kết quả thực hiện:
Accuracy: 84.55
Trong trường hợp này thì độc chính xác đạt được khi sử dụng các features từ FIS đúng bằng độ chính xác của Base model.
7. Kết luận
Bài thứ 6 về chủ đề Feature Selection, mình đã giới thiệu cách sử dụng Feature Importance Score trong việc Feature Selection. Toàn bộ code của bài này, các bạn có thể tham khảo tại đây.
Bài tiếp theo chúng ta sẽ chuyển sang nhiệm vụ mới của Data Preparation, đó là Data Transforms. Mời các bạn đón đọc.
8. Tham khảo
[1] Jason Brownlee, “Data Preparation for Machine Learning”, Book: https://machinelearningmastery.com/data-preparation-for-machine-learning/.