Giới thiệu Human Pose Estimation và Detectron2 platform

1. Giới thiệu Human Pose Estimation (HPE)
1.1 Định nghĩa Human Pose
Human Pose là sự thể hiện định hướng của một người ở định dạng đồ họa (khung xương). Về cơ bản, nó là một tập hợp các tọa độ có thể được kết nối để mô tả tư thế của một người. Mỗi phối hợp trong khung xương được gọi là một bộ phận (hoặc một khớp - joint, một điểm chính - keypoint). Một kết nối hợp lệ giữa hai phần được gọi là một cặp (hoặc một chi - limb). Lưu ý rằng, không phải tất cả các kết hợp bộ phận đều tạo ra các cặp hợp lệ. Dưới đây là một ví dụ:
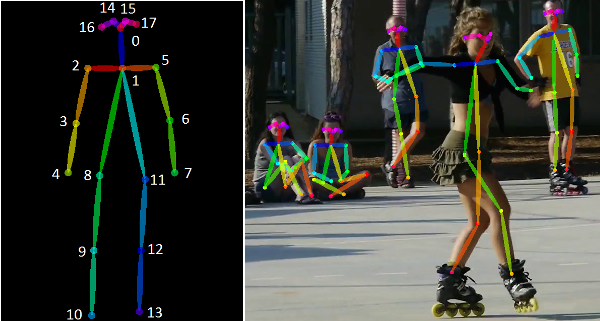
1.2 Ứng dụng của Human Pose Estimation
Biết được định hướng của một người sẽ mở ra con đường cho một số ứng dụng trong thực tế:
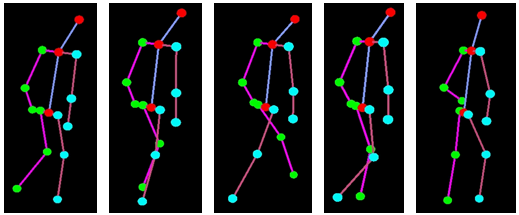
- Nhận diện hành động của người.
Theo dõi các tư thế khác nhau của một người trong một khoảng thời gian để nhận dạng hoạt động.
- Motion Capture and Augmented Reality
Đây là ứng dụng liên quan đến lĩnh vực đồ họa. Bằng việc biết được Pose của của một người, hệ thống có thể sinh ra các đạo cụ, trang phục vừa vặn với người trong video.

- Huấn luyện Robots
Bằng việc xác định Human Pose, Robots có thể hiểu được những chỉ dẫn của con người và thực hiện các hành động theo chỉ dẫn đó.
- Motion Tracking for Consoles
Đây cũng là ứng dụng trong lĩnh vực đồ họa. Tư thế, hành động của người có thể được nhận diện, sau đó được mô phỏng lại bằng một nhân vật ảo trong game, phim, …
1.3 Multi-Person Pose Estimation
Multi-Person Pose Estimation sẽ khó hơn nhiều so với Single-Person Pose Estimation, bởi vì chúng ta không biết vị trí của mỗi người dẫn đến việc nhẫm lẫn giữa các bộ phận của mỗi người với nhau. Gọi là râu ông nọ cắm cằm bà kia. Để giải quyết vấn đề này, có thể tiếp cận 1 trong 2 cách sau:
- Top-Down: Đầu tiên, sử dụng kỹ thuật Object Detection để xác định vị trí của từng người trước, sau đó mới thực hiện Pose Estimation cho mỗi người trong từng vị trí cụ thể đó. Ưu điểm của cách này là đơn giản, dễ thực hiện. Còn độ chính xác thì còn tùy vào từng ngữ cảnh.
- Down-Top: Ngược lại với cách trên, cách này sẽ phát hiện toàn bộ các bộ phận của mọi người trong ảnh trước, sau đó mới liên kết lại với nhau để xác định Pose của mỗi người.

1.4 Một số phương pháp thực hiện Human Pose Estimation
a, OpenPose
OpenPose có lẽ là phương thức phổ biến nhất dành cho HPE bởi vì tài liệu hướng dẫn của nó được tổ chức khá chi tiết, rõ ràng trên github. Sử dụng cách tiếp cận bottom-up, đầu tiên, OpenPose sẽ phát hiện tất cả các keypoints của mọi người trong ảnh, sau đó mới phân chia mỗi keypoint về từng người cụ thể.
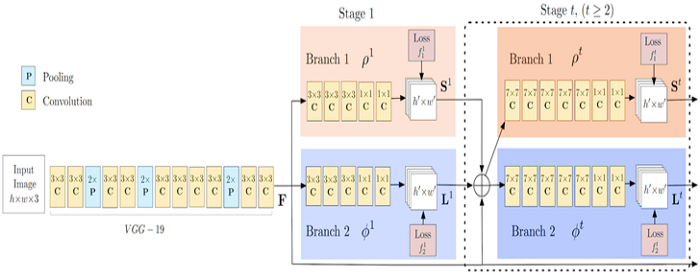
VGG19 trong OpenPose chịu trách nhiệm trích xuất các đặc trưng từ hình ảnh. Các đặc trưng này sau đó được đưa vào hai nhánh song song của các lớp Conv. Nhánh đầu tiên dự đoán 18 phần của bộ xương tư thế người. Nhánh thứ hai dự đoán một tập hợp 38 Part Affinity Fields (PAFs) thể hiện mức độ liên kết giữa các bộ phận đó.
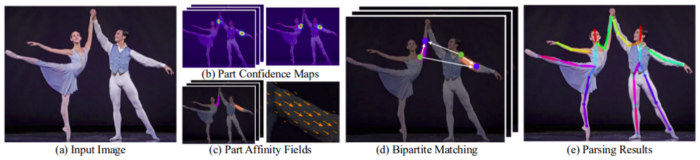
Các giai đoạn kế tiếp được sử dụng để tinh chỉnh các dự đoán được thực hiện bởi mỗi nhánh. Để được giải thích kỹ hơn về thuật toán, bạn có thể tham khảo bài báo của họ và bài đăng trên blog này.
b, DeepCut
DeepCut cũng sử dụng chiến lược bottom-up đối với trường hợp Multi-Person Pose Estimation.

c, RMPE (AlphaPose)
RMPE là một đại diện phổ biến của HPE theo chiến lược top-bottom. Phương pháp thường phụ thuộc vào độ chính xác của thuật toán phát hiện người trước đó. Nếu việc phát hiện đối tượng người không chính xác thì hiệu quả của HPE cũng theo đó mà giảm xuống.

d, Mask RCNN
Mask RCNN là một kiến trúc phổ biến để thực Semantic và Instance Segmantation. Mô hình này dự đoán song song cả vị trí của các đối tượng khác nhau trong hình ảnh và Mask của đối tượng về mặt ngữ nghĩa. Kiến trúc cơ bản có thể được mở rộng khá dễ dàng để ước tính tư thế của con người.
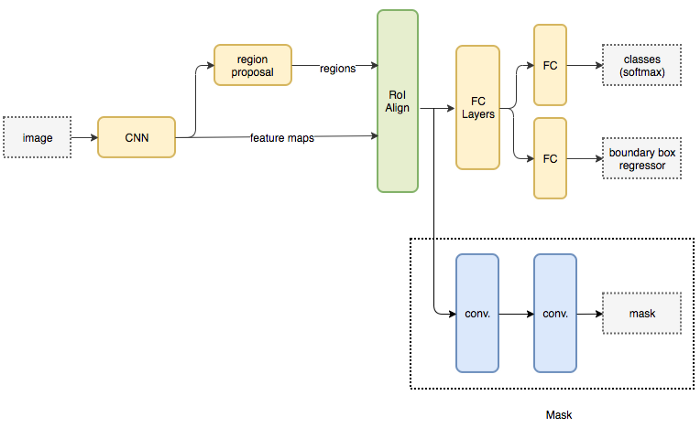
Mask RCNN hiện tại đã được tích hợp vào Detectron2 platform của Facebook, giúp các nhà phát triển dễ dàng sử dụng nó.
2. Detectron2 platform
2.1 Giới thiệu
Detectron2 là một platform của Facebook AI Research (FAIR) dành cho các tác vụ Object Detection, Human Pose, Segmentation,… Platform này được phát triển bằng Pytorch và cung cấp dưới dạng mã nguồn mở cho các nhà phát triển. Phiên bản trước đó, Detectron được xây dựng bằng Caffe2 framework.
FAIR tuyên bố như sau:
“We builtDetectron2 to meet the research needs of Facebook AI and to provide the foundation for object detection in production use cases at Facebook. We are now using Detectron2 to rapidly design and train the next-generation pose detection models that power Smart Camera, the AI camera system in Facebook’s Portal video-calling devices. By relying on Detectron2 as the unified library for object detection across research and production use cases, we are able to rapidly move research ideas into production models that are deployed at scale.”

Bạn có thể tìm thấy các pre-trained model của mà Detectron2 cung cấp tại Detectron2 Model Zoo.
Bên cạnh đó, FAIR cũng mới phát hành Detectron2go với sự bổ sung thêm một số tính năng giúp triển khai các model dễ dàng hơn trong sản phẩm thực tế.
2.2 Thực hành với Detectron2
a, Giới thiệu Wrapper Detectron2 project
Detectron2 có thể được sử dụng trực tiếp từ code trên github của nó. Tuy nhiên, ở đây mình hướng dẫn các bạn sử dụng thông qua một wrapper-detectron2-project tên là detectron2-pipeline. Project này có những ưu điểm sau:
- Dễ dàng tích hợp với các model khác nhau từ Detectron2 Model Zoo.
- Tăng tốc độ xử lý video, hình ảnh bằng việc chia xử lý ra nhiều threads khác nhau.
- Tối ưu hóa tốc độ train/inference bằng việc tận dụng tối đa sức mạnh của GPU/CPU.
$ git clone git://github.com/jagin/detectron2-pipeline.git
$ cd detectron2-pipeline
Cấu trúc của project này như sau:
├── assets
├── configs
├── environment.yml
├── LICENSE
├── output
├── pipeline
│ ├── annotate_image.py
│ ├── annotate_video.py
│ ├── async_predict.py
│ ├── capture_image.py
│ ├── capture_images.py
│ ├── capture_video.py
│ ├── display_video.py
│ ├── __init__.py
│ ├── libs
│ │ ├── async_predictor.py
│ │ ├── file_video_capture.py
│ │ ├── __init__.py
│ │ └── webcam_video_capture.py
│ ├── pipeline.py
│ ├── predict.py
│ ├── save_image.py
│ ├── save_video.py
│ ├── separate_background.py
│ └── utils
│ ├── colors.py
│ ├── detectron.py
│ ├── fs.py
│ ├── __init__.py
│ ├── text.py
│ └── timeme.py
├── process_images.py
├── process_video.py
├── pytest.ini
├── README.md
└── tests
Các folders/files dùng chung:
- utils/: common utility scripts,
- pipeline/lib/file_video_capture.py: video file capturing helper class utilizing threading and the queue to obtain FPS speedup,
- pipeline/lib/webcam_video_capture.py: helper class for capturing webcam in a separate thread,
- pipeline/capture_image.py: pipeline task to capture single image file,
- pipeline/capture_images.py: pipeline task to capture images from a directory,
- pipeline/capture_video.py: pipeline task to capture video stream from file or webcam using a faster, threaded method for reading video frames.
- pipeline/display_video.py: pipeline task to display images as a video,
- pipeline/pipeline.py: common pipeline class fo all pipeline tasks,
- pipeline/save_image.py: pipeline task to save images,
- pipeline/save_video.py: pipeline task to save a video.
Các files dưới đây là nơi chúng ta sẽ sử dụng, chỉnh sửa để áp dụng vào bài toán cụ thể:
- pipeline/annotate_image.py: pipeline task for image annotation,
- pipeline/annotate_video.py: pipeline task for video annotation,
- pipeline/lib/async_predictor.py: asynchronous predictor utilizing multiprocessing to run the inferences in parallel in separate processes,
- pipeline/predict.py: pipeline task to perform a prediction,
- pipeline/async_predict.py: pipeline task to perform prediction asynchronously using multiprocessing,
- pipeline/separate_background.py: custom pipeline task to separate the background from foreground instances as an example use of the semantic segmentation model from Detectron2.
Các files cấu hình models:
├── configs
│ ├── COCO-Detection
│ │ ├── faster_rcnn_R_50_FPN_3x.yaml
│ │ └── retinanet_R_50_FPN_3x.yaml
│ ├── COCO-InstanceSegmentation
│ │ └── mask_rcnn_R_50_FPN_3x.yaml
│ ├── COCO-Keypoints
│ │ └── keypoint_rcnn_R_50_FPN_3x.yaml
│ └── COCO-PanopticSegmentation
│ └── panoptic_fpn_R_50_3x.yaml
b, Tạo môi trường ảo bằng Conda
$ conda env create -f environment.yml
$ conda activate detectron2-pipeline
c, Cài đặt Detectron2
$ cd ..
$ git clone https://github.com/facebookresearch/detectron2.git
$ cd detectron2
$ git checkout 3def12bdeaacd35c6f7b3b6c0097b7bc31f31ba4
$ python setup.py build develop
Commit 3def12bdeaacd35c6f7b3b6c0097b7bc31f31ba4 là phiên bản ổn định để sử dụng.
d, Image Processing
- Các options:
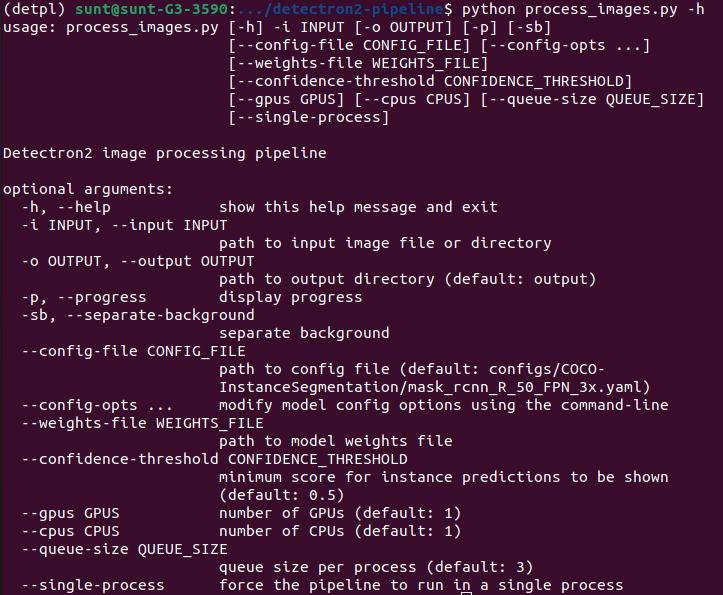
- Ví dụ với InstanceSegmentation model (mặc định):
$ python process_images.py -i assets/images/others -p

- Ví dụ với Human Pose Estimation model:
$ python process_images.py -i assets/images/others/couple.jpg -p --config-file configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml

e, Video Processing
- Các options:
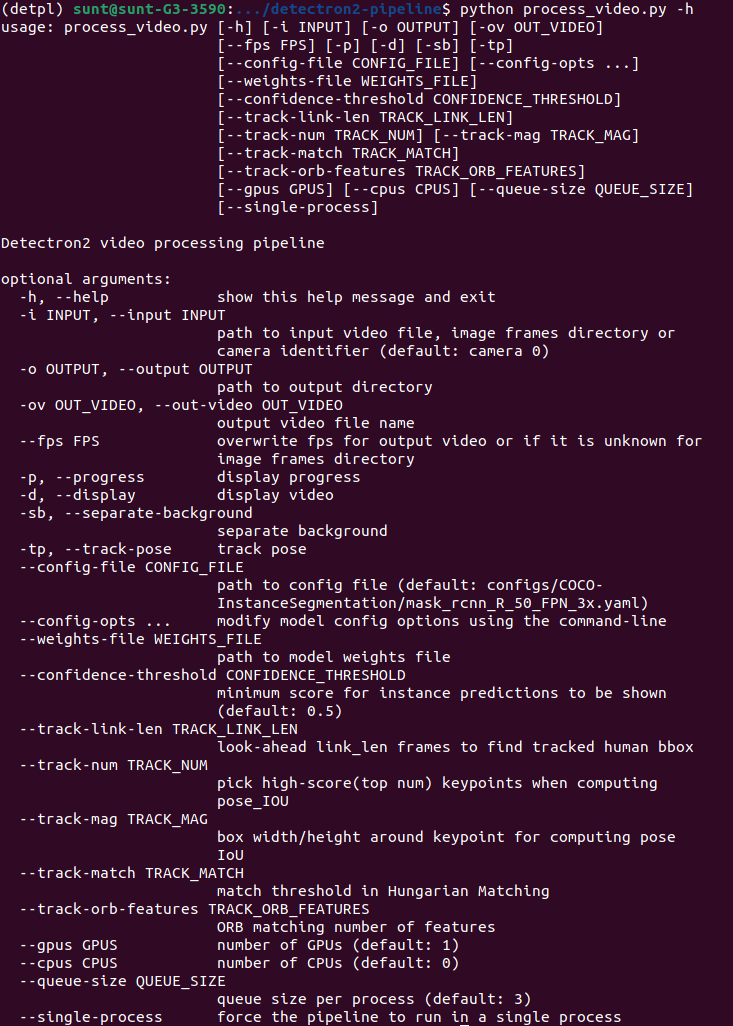
- Ví dụ với InstanceSegmentation model (mặc định) sử dụng webcam/camera:
$ python process_video.py -i 0 -d -p
- Ví dụ với InstanceSegmentation model (mặc định) sử dụng video file:
$ python process_video.py -i assets/videos/walk.small.mp4 -p -d -ov walk.avi

- Ví dụ với PanopticSegmentation model sử dụng video file:
$ python process_video.py -i assets/videos/traffic.small.mp4 -p -d -ov traffic.avi --config-file configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml

- Ví dụ với Human Pose Estimation model sử dụng video file:
$ python process_video.py -i assets/videos/walk.small.mp4 -p -d --config-file configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml
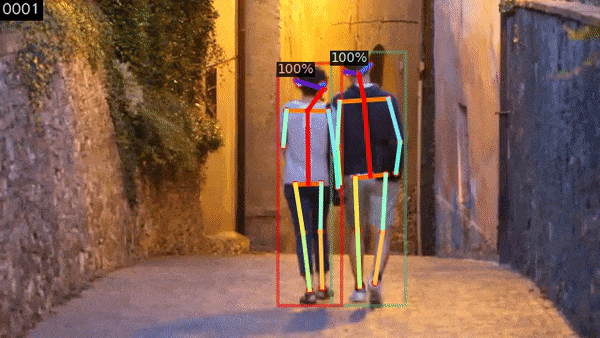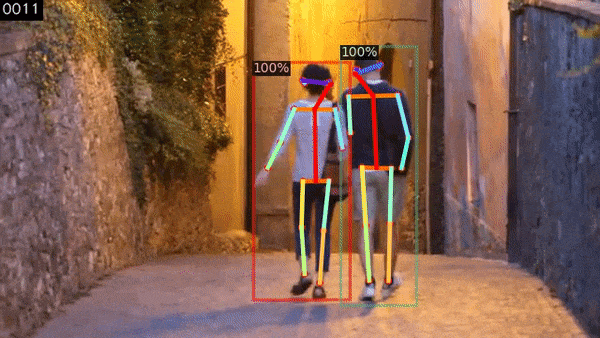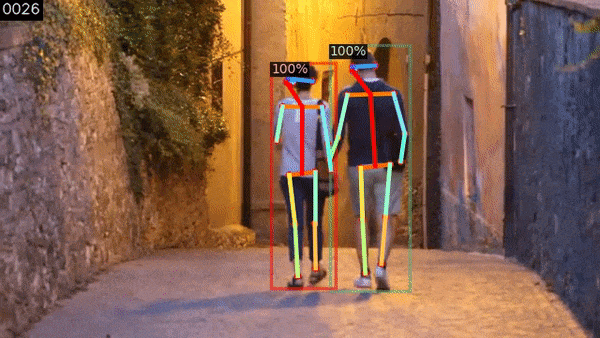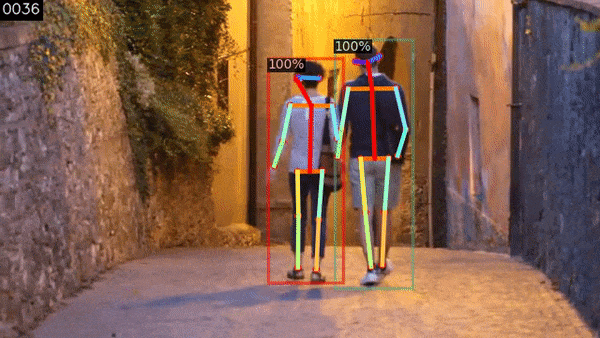
f, Human Pose Tracking
PoseFlow là một phương pháp tracking cho Human Pose rất hiệu quả. Nó được mô tả trong bài báo PoseFlow: Efficient Online Pose Tracking của Yuliang Xiu, Jiefeng Li, Haoyu Wang, Yinghong Fang, Cewu Lu.
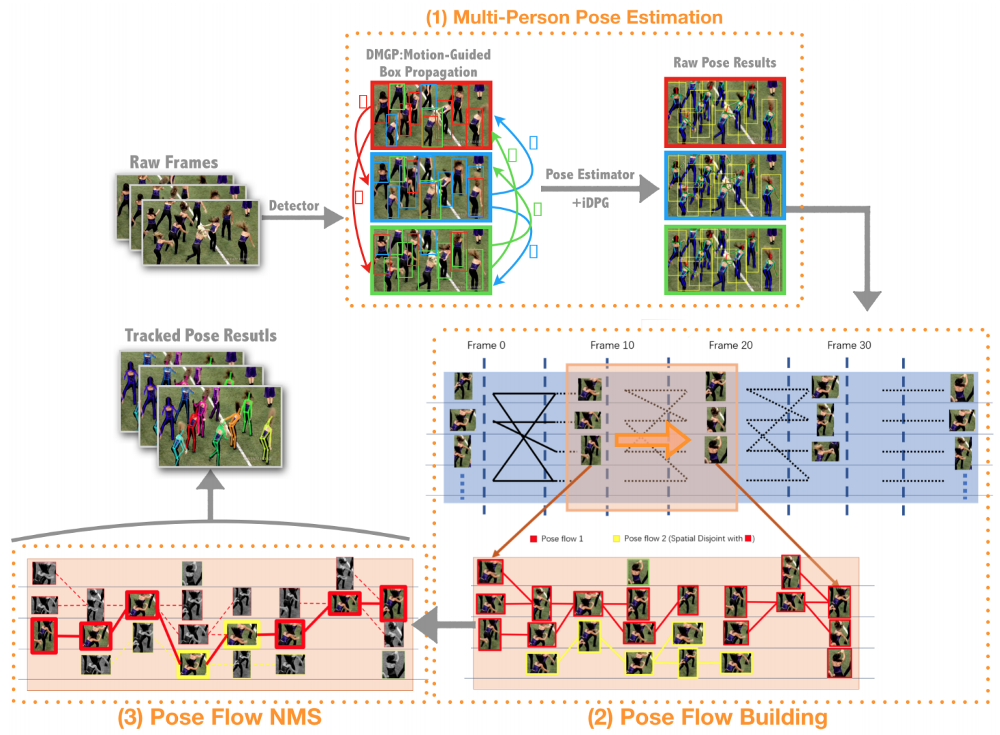
Mình cảm thấy bài báo hơi khó đọc 1 chút. Tuy nhiên mình không đi quá chi tiết vào thuật toán mà đơn giản chỉ muốn sử dụng nó.
PoseFlow cũng đã được tích hợp vào AlphaPose, bạn có thể thử. Còn ở đây mình sẽ áp dụng nó với Mask RCNN trong Detectron2.
$ process_video.py -i assets/videos/walk.small.mp4 -p -d --config-file configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml -tp

Kết quả cuối cùng sẽ phụ thuộc vào một số yếu tố:
- ĐỘ chính xác của model phát hiện người.
- Độ chính xác của model Pose Estimation.
- Chất lượng của hình ảnh.
- Các options khác nhau của tracking (xem trong file processing_video.py, dòng 51-60)
f, Background Separation
Một ứng dụng thú vị khác của Detectron2 là Background Separation, giống như viêc chụp ảnh làm mờ hậu cảnh, chỉ tập trung vào tượng chính. Thuật toán được diễn giải như sơ đồ dưới đây:
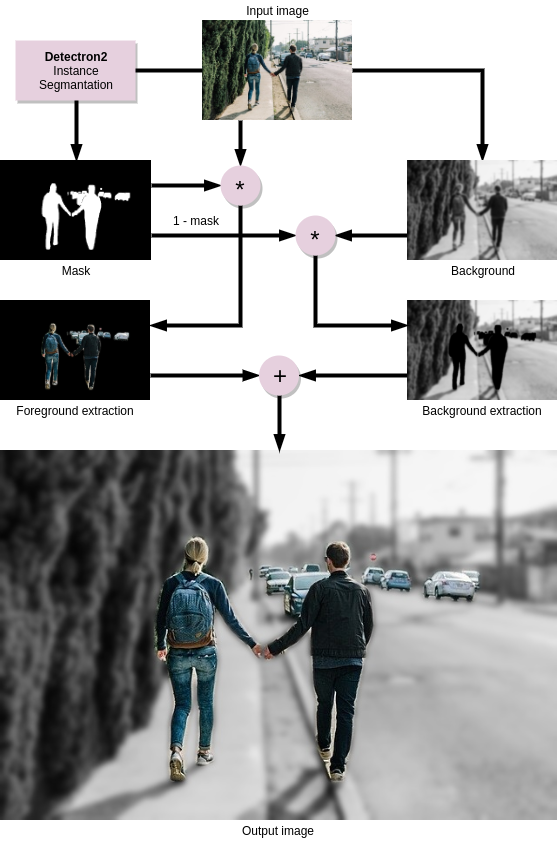
- Ví dụ với hình ảnh:
$ python process_images.py -i assets/images/others/couple.jpg -sb
- Ví dụ với video:
python process_video.py -i assets/videos/walk.small.mp4 -sb -d

3. Kết luận
Nếu xét riêng về Human Pose Estimation, các model trong Detectron2 có thể không phải là tốt nhất, xem bảng so sánh sau:
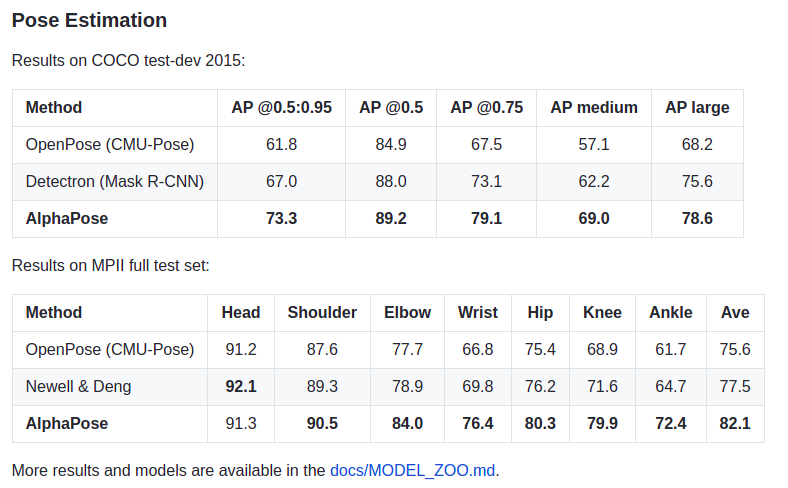
Từ bảng trên, có thể thấy AlphaPose cho kết quả tốt hơn so với 2 phương pháp OpenPose (CMU-Pose) và Detectron2 (Mask RCNN). Tuy nhiên, bù lại thì Detectron2 (Mask RCNN) lại dễ dàng sử dụng hơn. Tùy vào yêu cầu bài toán cụ thể mà bạn có thể chọn lựa phương pháp phù hợp cho mình.
Như vậy, bài này mình đã giới thiệu qua cho các bạn về Human Pose Estimation và cách sử dụng Detectron2 platform. Bài tiếp theo, chúng ta sẽ thực hành phân loại một số hành động của con người trong video sử dụng những kiến thức đã đề cập trong bài hôm nay.
Mời các bạn đón đọc.!
4. Tham khảo
[1] Bharath Raj, “An Overview of Human Pose Estimation with Deep Learning”, Available online: https://medium.com/beyondminds/an-overview-of-human-pose-estimation-with-deep-learning-d49eb656739b (Accessed on 31 Jul 2021).
[2] Jarosław Gilewski, “How to embed Detectron2 in your computer vision project”, Available online:https://medium.com/deepvisionguru/how-to-embed-detectron2-in-your-computer-vision-project-817f29149461 (Accessed on 31 Jul 2021).
[3] Jarosław Gilewski, “PoseFlow — real-time pose tracking”, Available online: https://medium.com/deepvisionguru/poseflow-real-time-pose-tracking-7f8062a7c996 (Accessed on 31 Jul 2021).