Các phương pháp Video Classification
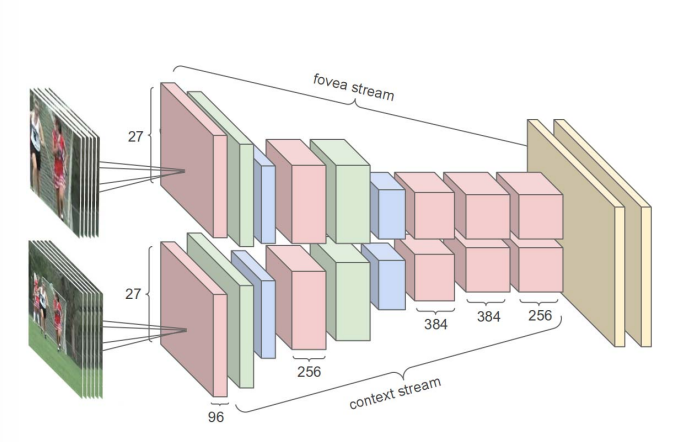
Trong bài viết này, chúng ta cùng tìm hiểu về Video Classification. Chúng ta sẽ điểm danh sơ lược một số phương pháp tiếp cận để giải quyết bài toán này.
1. Video Classification là gì?
Nếu nói đến Image Classification thì chắc các bạn đều biết, còn Video Classification thì có thể nhiều người chưa nghe qua. Về bản chất, video là tập hợp các frame ảnh được hiển thị liên tiếp nhau với tốc độ khoảng 24 ảnh/giây. Điều này làm cho mắt người có cảm giác sự việc diễn ra trong video là liên tục. Video Classification tức là phân loại, dự đoán xem đối tượng, sự vật, sự việc trong một đoạn video là gì.
Nếu bạn sử dụng những kỹ thuật của Image Classification vào bài toán Video Classification thì … cũng có thể đúng trong 1 số trường hợp, khi mà cái cần phân lại trong video tương đối rõ ràng, ko có sự nhập nhằng, liên kết giữa các frames với nhau. Ví dụ, phân biệt hành vi đứng và ngồi của người trong video.
Tuy nhiên, với những bài toán mà thông tin cần xác định trải dài qua nhiều frames, nếu chúng ta chỉ sử dụng một frame để nhận biết thì sẽ dẫn đến kết quả sai lầm. Ví dụ, phân biệt hành vi đang đứng, đang ngồi của người trong video. Hay phân biệt hành vi lấy hàng, trả hàng lên kệ trong siêu thị, …

Đối với những tình huống kiểu như vậy, chúng ta phải kết hợp nhiều frames lại với nhau, đồng thời có tính đến thứ tự theo thời gian xuất hiện của chúng mới có thể giải quyết được.
2. Các phương pháp Video Classification
2.1 Phương pháp Single-Frame CNN

Đây chính xác là cách tiếp cận sử dụng kỹ thuật của bài toán Image Classification. Chúng ta cho lần lượt từng frame của video chạy qua mô hình Image Classification. Kết quả cuối cùng là trung bình của tất các kết quả dự đoán trên mỗi frame. Tất nhiên, chúng ta có thể chỉ dùng 1 số lượng frames nhất định chứ không cần toàn bộ frames trong video. Giá trị này gọi là window_size.
2.2 Phương pháp Late Fusion
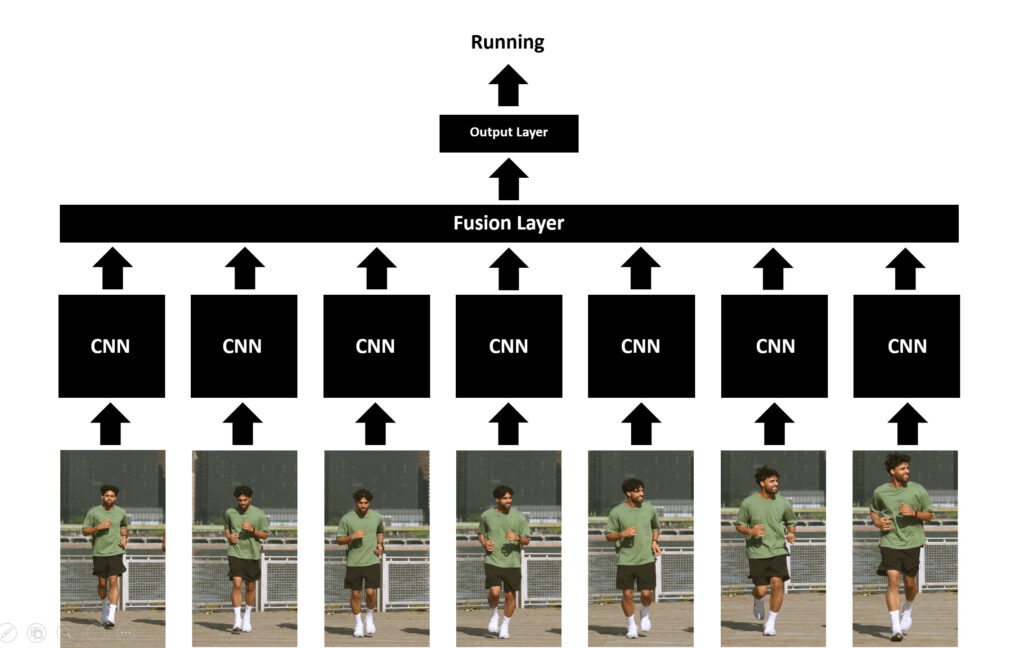
Về cơ bản, phương pháp Late Fusion rất giống với phương pháp Single-Frame CNN nhưng phức tạp hơn một chút. Sự khác biệt ở đây là trong phương pháp Single-Frame CNN, việc tính trung bình trên tất cả các xác suất dự đoán được thực hiện sau khi mô hình đã hoàn thành công việc của nó, nhưng trong phương pháp Late Fusion, quá trình lấy trung bình (hoặc một số kỹ thuật Fusion khác) được tích hợp luôn vào kiến trúc mạng của chính nó. Do đó, cấu trúc thời gian của chuỗi frame được duy trì.
Cụ thể, một Fusion layer được sử dụng để hợp nhất các kết quả đầu ra của của các mạng riêng biệt, những cái hoạt động trên các frames khác nhau. Layer này thường được xây dựng bằng một số kỹ thuật như Max Pooling, Average Pooling, hay Flattening.
Phương pháp Late Fusion được cho là có thể học được các thông tin về không gian và thời gian của những đối tượng, hành động xuất hiện trong video. Do đó, độ chính xác cũng cao hơn phương pháp Single-Frame CNN.
2.3 Phương pháp Early Fusion

Cách tiếp cận của phương pháp này ngược với phương pháp Late Fusion. Thông tin về thời gian và không gian của các frames được hợp nhất trước khi chuyển đến cho mô hình. Mô hình sẽ học để xác định sự chuyển động của các pixels giữa các frames liền kề nhau.
Một video có kích thước T x 3 x H x W, trong đó T à khoảng thời gian, 3 kênh RGB, chiều dài H và chiều rộng W, sau khi được Early Fusion sẽ trở thành một Tensor có kích thước 3T x H x W.
2.4 Phương pháp CRNN
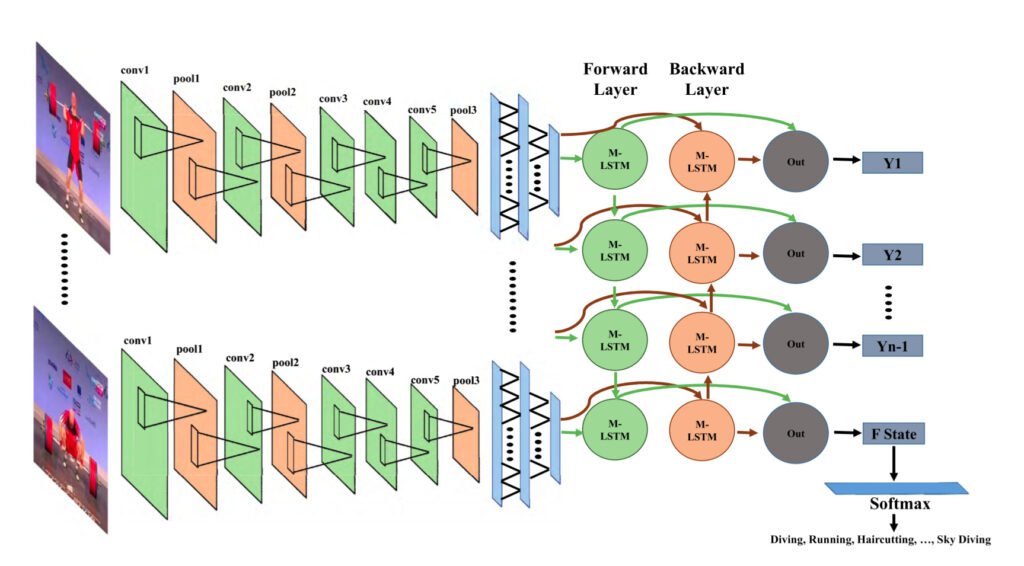
Ý tưởng của phương pháp này là sử dụng một mạng CNN để trích xuất các đặc trưng của mỗi frame. Đầu ra của các mạng này sau đó được cung cấp cho một mạng LSTM đa lớp Many-to-One để kết hợp và đưa ra kết quả dự đoán. LSTM là kiến trúc mạng lý tưởng cho việc xử lý dữ liệu dạng chuỗi, có liên quan đến yếu tố thời gian.
Bạn có thể đọc chi tiết về phương pháp này trong bài báo Action Recognition in Video Sequences using Deep Bi-Directional LSTM With CNN Features của Amin Ullah (IEEE 2017).
2.5 Phương pháp Pose Detection + LSTM
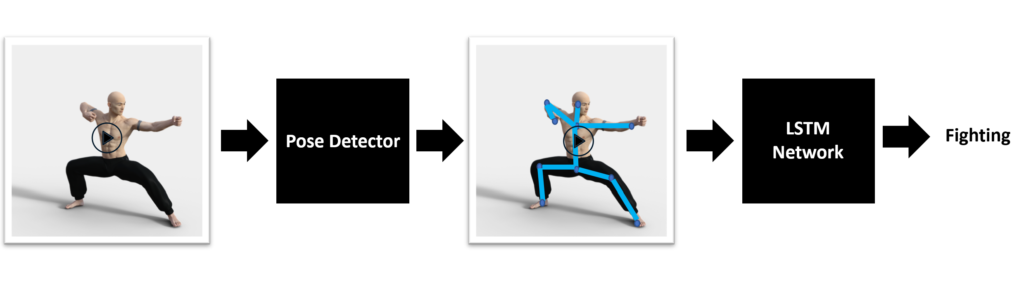
Một ý tưởng thú vị khác là sử dụng một mô hình Pose Detection để nhận về các Key Points từ cơ thể con người trong mỗi frame. Sau đó, đưa các Key Points này đi qua mạng LSTM đề quyết định hành vi của người đó trong video. Một số mô hình Pose Detection nổi tiếng có thể sử dụng là Open Pose, Detectron2, …Trong bài tiếp theo, chúng ta sẽ sử dụng phương pháp này đề nhận diện các hành vi của con người.
2.6 Phương pháp Optical Flow + CNN
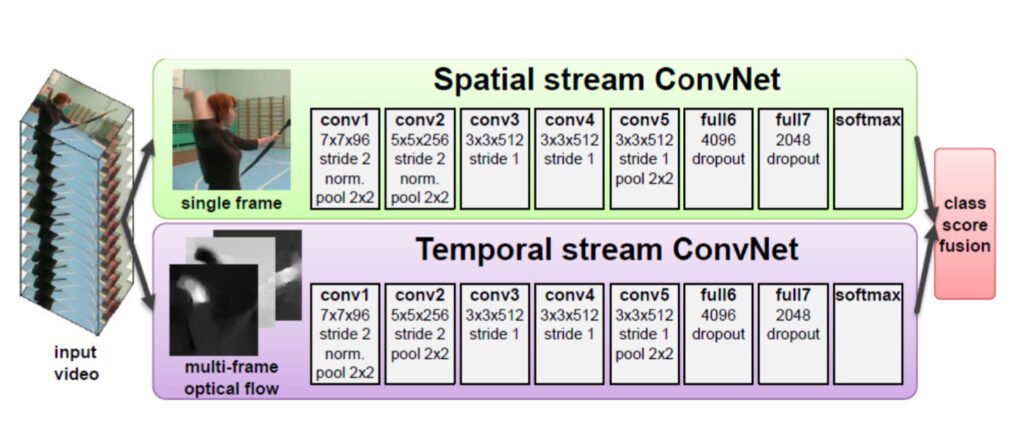
Optical Flow là một mô hình mô tả sự chuyển động có thể nhìn thấy được của các đối tượng trong các frames của video. Sự chuyển động này được thể hiện thông qua một vector chuyển động. Optical Flow được sử dụng rất hiệu quả trong các ứng dụng theo dõi chuyển động. Sẽ là một ý tưởng không tồi nếu kết hợp Optical Flow với mạng CNN để lấy được các thông tin về sự chuyển động (thông tin thời gian) và thông tin về không gian của các đối tượng trong video. Bài báo A Comprehensive Review on Handcrafted and Learning-Based Action Representation Approaches for Human Activity Recognition của Allah Bux Sargano (2017) đề cập chi tiết đến phương pháp này.
Mô tả qua về cách thức hoạt động. Sẽ có 2 CNN Networks hoạt động đồng thời.
- Network thứ nhất là Spatial ConvNet. Nó nhận một frame đơn lẻ để xử lý và sinh ra kết quả dự đoán dựa trên thông tin không gian.
- Network thứ hai là Temporal ConvNet. Nó nhận vào một chuỗi các frame liên tiếp để tính toán vector chuyển động của đối tượng. Sử dụng vector này để sinh ra kết quả dự đoán.
Trung bình dự đoán của 2 Networks được sử dụng làm kết quả cuối cùng.
3.7 Phương pháp SlowFast
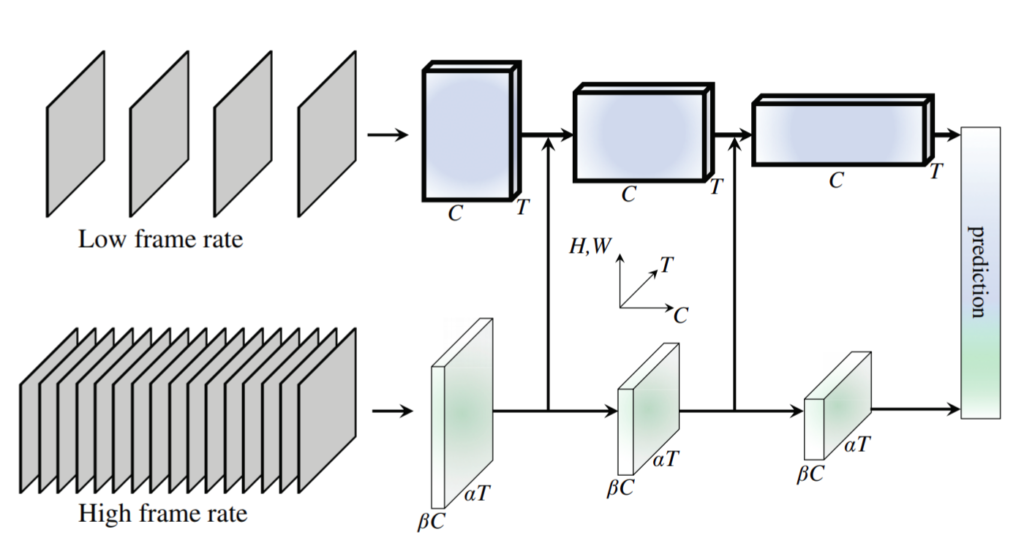
Tương tự như phương pháp Optical Flow + CNN, phương pháp này cũng sử dụng song song 2 Networks. Một Network hoạt động trên luồng video có độ phân giải thấp gọi là Slow branch, một Network hoạt động trên video có độ phân giải cao hơn gọi là Fast branch. Đầu ra của mỗi branch được kết hợp lại để sinh ra kết quả dự đoán cuối cùng.
Chi tiết về phương pháp này có thể tham khảo ở bài báo SlowFast Networks for Video Recognition của Christoph Feichtenhofer ( ICCV 2019).
2.8 Phương pháp 3D CNN ( Slow Fusion)

Phương pháp này sử dụng 3D CNN để xử lý đồng thời cả thông tin không gian và thời gian trong cùng 1 mạng duy nhất. Tên khác của nó là Slow Fusion. Không giống như Late/Early Fusion, nó kết hợp luôn thông tin thời gian và không gian tại mỗi lớp Conv xuyên suốt toàn mạng 3D CNN. Dữ liệu đầu vào, do đó cũng phải có 4 chiều T x C x W x H.
Nhược điểm của phương pháp này là nó yêu cầu tài nguyên tính toán lớn bởi vì nó làm việc với dữ liệu 4 chiều. Chi tiết hơn, các bạn có thể xem tại bài báo 3D Convolutional Neural Networks for Human Action Recognition.
Một paper khác so sánh toàn bộ các phương pháp mình vừa nêu tên ở đây là Large-scale Video Classification with Convolutional Neural Networks. Bài báo này của tác giả Andrej Karpathy và đựơc trình bày tại hội nghị CVPR năm 2014.
3. Kết luận
Bài này mình đã giới thiệu qua cho các bạn một số phương pháp để giải quyết bài toán Video Classification. Bài tiếp theo, chúng ta sẽ thực hành phân loại một số hành động của con người trong video sử dụng một trong các phương pháp đó!
Mời các bạn đón đọc.!
4. Tham khảo
[1] Taha Anwar, “Introduction to Video Classification and Human Activity Recognition”, Available online: https://learnopencv.com/introduction-to-video-classification-and-human-activity-recognition/ (Accessed on 27 Jul 2021).