DP4ML - Missing Data - Phần 3 - kNN Imputation

Bài thứ 6 trong chuỗi các bài viết về chủ đề Data Preparation cho các mô hình ML và là bài thứ 3 về chủ đề Missing Data. Trong bài này, chúng ta sẽ tìm hiểu phương pháp tiếp theo để giải quyết vấn đề Missing Data, đó là phương pháp kNN Imputation.
1. k-Nearest Neighbor (kNN) Imputation
Nhắc đến kNN, chắc hẳn mọi người đều biết đó là một thuật toán supervised-learning đơn giản nhất (nhưng lại có hiệu quả đối với một số trường hợp) trong Machine Learning. Khi training, thuật toán này không học một điều gì từ dữ liệu training (*đây cũng là lý do thuật toán này được xếp vào loại lazy learning, mọi tính toán được thực hiện khi nó cần dự đoán kết quả của dữ liệu mới. kNN có thể áp dụng được vào cả hai loại của bài toán Supervised Learning là Classification và Regression. Nó cũng được gọi là một thuật toán Instance-based hay Memory-based Learning.
Để giải quyết vấn đề Missing Data, một cách hiệu quả là sử dụng một mô hình để dự đoán giá trị cho Missing Data đó, dựa vào những giá trị tồn tại trong tập dữ liệu. Về lý thuyết, chúng ta có thể sử dụng bất kỳ thuật toán ML Classification/Regression nào để thực hiện việc Imputation cho Missing Data, nhưng thực tế chứng minh rằng kNN mang lại hiệu quả tốt hơn, cả về khía cạnh độ chính xác và mức độ phức tạp khi thực hiện.
Việc cấu hình cho kNN thường bao gồm việc lựa chọn 2 giá trị là loại metric đo khoảng cách giữa các mẫu dữ liệu (Euclidean, Cosine, …) và số lượng mẫu (k) lân cận với mẫu cần xác định giá trị/lớp.
2. Thực hành kNN Imputation
Chúng ta sẽ thực hành phương pháp kNN Imputation trên bộ dữ liệu Horse Colic Dataset giống như bài trước.
Thư viện Scikit-learn cung cấp lớp KNNImputer giúp chúng ta dễ dàng thực hiện kNN Imputation.
2.1 KNNImputer và Data Transform
Cũng giống như SimpleImputer, khi sử dụng KNNImputer, nó sẽ tạo ra một phiên bản khác của tập dữ liệu ban đầu mà ở đó, các Missing Data đã được thay thế bởi các giá trị sinh ra từ thuật toán kNN (Data Transform). Các bước thực hiện Data Transform sử dụng KNNImputer như sau:
a, Khai báo một Instance của KNNImputer
Khi khởi tạo Instance cho KNNImputer cần quan tâm đến 3 tham số truyền vào:
-
Số lượng mẫu dữ liệu lân cận (n_neighbors)
-
Loại khoảng cách (metric): mặc định là ‘nan_euclidean’, tức là Euclidean nhưng bỏ qua các Missing Data*)
-
Trọng số (weight): sử dụng trọng số giữa các mẫu dữ liệu lân cận khi tính khoảng cách. Giá trị mặc định là ‘uniform’, tức là tất cả trọng số đều bằng nhau. Để sát sao hơn, ta có thể sử dụng giá trị ‘distance’, tức là mẫu dữ liệu nào càng gần mẫu dữ liệu cần dự đoán thì trọng số càng cao.
...
# define imputer
imputer = KNNImputer(n_neighbors=5, weights= 'distance' , metric= 'nan_euclidean')
b, Tính toán giá trị cho Missing Data trên tập dữ liệu
...
# fit on the dataset
imputer.fit(X)
c, Tạo ra Transform Data
...
# transform the dataset
Xtrans = imputer.transform(X)
Để kiểm chứng lại hiệu quả làm việc của KNNImputer, chúng ta sẽ áp dụng lên tập dữ liệu Horse Colic Dataset, xem trước và sau khi áp dụng KNNImputer có gì thay đổi:
# knn imputation transform for the horse colic dataset
from numpy import isnan
from pandas import read_csv
from sklearn.impute import KNNImputer
# load dataset
dataframe = read_csv('horse-colic.csv' , header=None, na_values= '?')
# split into input and output elements
data = dataframe.values
ix = [i for i in range(data.shape[1]) if i != 23]
X, y = data[:, ix], data[:, 23]
# summarize total missing
print('Missing: %d' % sum(isnan(X).flatten()))
# define imputer
imputer = KNNImputer()
# fit on the dataset
imputer.fit(X)
# transform the dataset
Xtrans = imputer.transform(X)
# summarize total missing
print('Missing: %d' % sum(isnan(Xtrans).flatten()))
Kết quả:
Missing: 1605
Missing: 0
Ban đầu có 1605 Missing Data. Sau khi áp dụng KNNImputer, số lượng Missing Data giảm về 0, chứng tỏ rằng nó đã thành công trong việc xóa bỏ Missing Data.
2.2 KNNImputer và Model Evaluation
Phần này chúng ta sẽ áp dụng kNN Imputation vào việc mô hình hóa thuật toán RandomForest trên tập dữ liệu Horse Colic Dataset. k-Fold Cross-validation và Pipleline cũng sẽ được sử dụng tương tự như bài trước.
# evaluate knn imputation and random forest for the horse colic dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import KNNImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# load dataset
dataframe = read_csv('horse-colic.csv', header=None, na_values='?')
# split into input and output elements
data = dataframe.values
ix = [i for i in range(data.shape[1]) if i != 23]
X, y = data[:, ix], data[:, 23]
# define modeling pipeline
model = RandomForestClassifier()
imputer = KNNImputer(n_neighbors=5, weights= 'distance' , metric= 'nan_euclidean')
pipeline = Pipeline(steps=[('i', imputer), ('m', model)])
# define model evaluation
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate model
scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
Kết quả thực hiện:
Mean Accuracy: 0.871 (0.051)
2.3 Tuning n_neighbors parameter
Như đã trình bày ở phần trên, n_neighbors là một tham số quan trọng ảnh hưởng đến độ chính xác của kNN. Chúng ta không thể biết chính xác giá trị phù hợp nhất của nó đối với mỗi bộ dữ liệu. Cách dễ nhất để tìm ra nó là thử-sai, tức là chọn một khoảng giá trị của nó và thử lần lượt từng giá trị trong khoảng đó xem giá trị nào tốt nhất. Code dưới đây đánh giá độ chính xác trung bình của kNN cho mỗi trường hợp giá trị của n_neighbors thay đôi từ 1 đến 21.
# compare knn imputation strategies for the horse colic dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import KNNImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataset
dataframe = read_csv('horse-colic.csv', header=None, na_values='?')
# split into input and output elements
data = dataframe.values
ix = [i for i in range(data.shape[1]) if i != 23]
X, y = data[:, ix], data[:, 23]
# evaluate each strategy on the dataset
results = list()
strategies = [str(i) for i in range(21):
for s in strategies:
# create the modeling pipeline
pipeline = Pipeline(steps=[('i', KNNImputer(n_neighbors=int(s))), ('m', RandomForestClassifier())])
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# store results
results.append(scores)
print('>%s %.3f (%.3f)' % (s, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()
Kết quả chạy:
- Độ chính xác trung bình và độ lệch chuẩn.
>1 0.868 (0.048)
>2 0.861 (0.047)
>3 0.859 (0.051)
>4 0.863 (0.052)
>5 0.864 (0.056)
>6 0.866 (0.060)
>7 0.872 (0.056)
>8 0.864 (0.056)
>9 0.868 (0.053)
>10 0.868 (0.053)
>11 0.864 (0.053)
>12 0.862 (0.051)
>13 0.861 (0.049)
>14 0.868 (0.051)
>15 0.862 (0.054)
>16 0.863 (0.048)
>17 0.863 (0.054)
>18 0.862 (0.057)
>19 0.866 (0.051)
>20 0.869 (0.055)
>21 0.866 (0.057)
Theo kết quả này, độ chính xác khi n_neighbors = 7 cao nhất, nhưng độ lệch chuẩn cũng khá cao. n_neighbors = 1 cho ra độ chính xác tương đối cao, độ lệch chuẩn gần nhỏ nhất.
- Phân phối kết quả
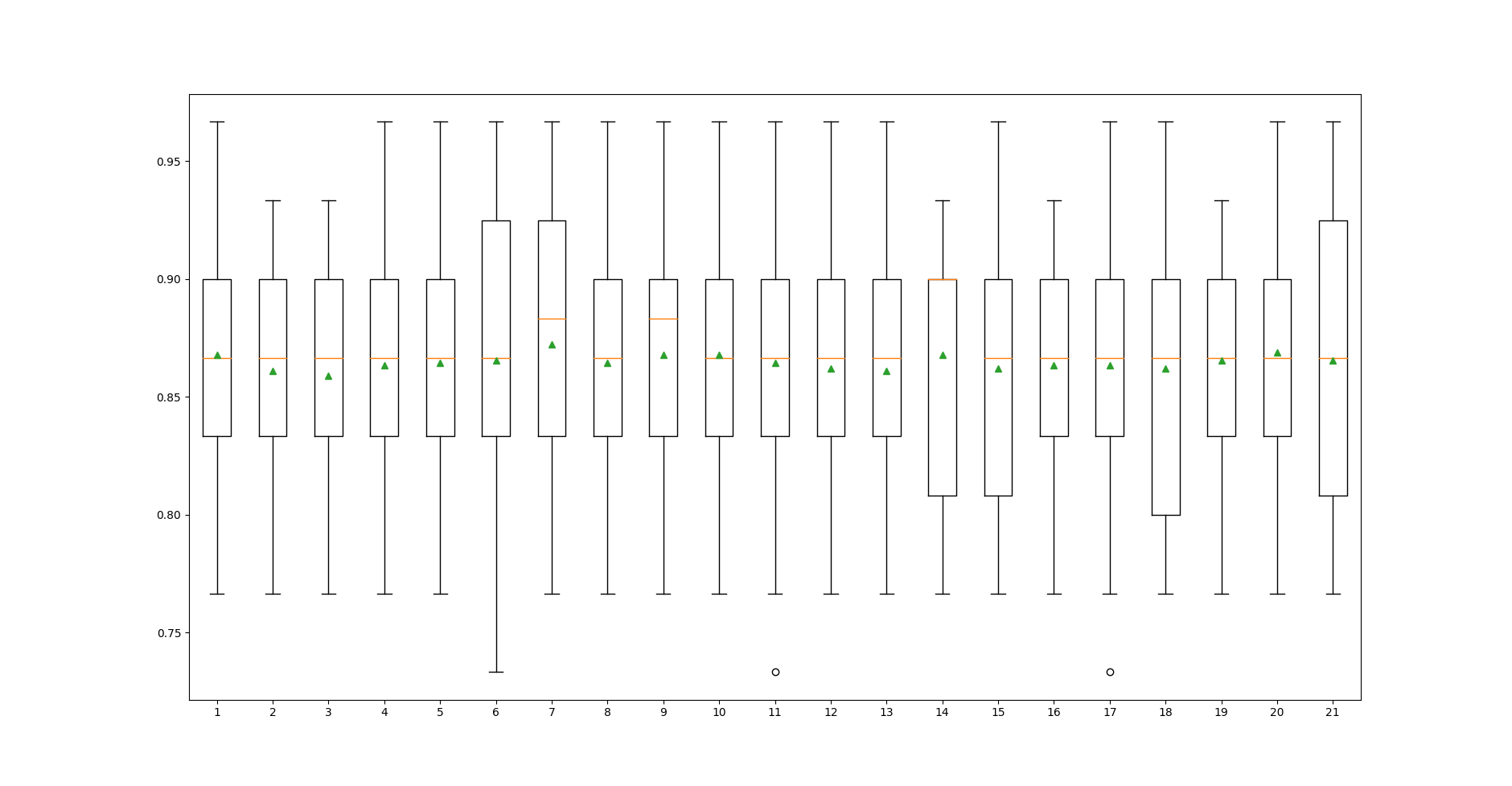
Mức độ phân phối trong trường hợp n_neighbors = 1 là nhỏ nhất.
Kết hợp các nhận xét trên, có thể nhận định n_neighbors = 1 là giá trị tối ưu của bài toán này.
2.4 Sử dụng KNNImputer Transform khi dự đoán dữ liệu mới.
Chúng ta sẽ sử dụng các kết quả phân tích từ phần trên để tạo ra model, sau đó dự dự đoán trên một mẫu dữ liệu mới. Code hoàn chỉnh như sau:
# knn imputation strategy and prediction for the horse colic dataset
from numpy import nan
import joblib
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import KNNImputer
from sklearn.pipeline import Pipeline
# load dataset
dataframe = read_csv('horse-colic.csv', header=None, na_values='?')
# split into input and output elements
data = dataframe.values
ix = [i for i in range(data.shape[1]) if i != 23]
X, y = data[:, ix], data[:, 23]
# create the modeling pipeline
pipeline = Pipeline(steps=[('i', KNNImputer(n_neighbors=1, weights='distance')), ('m', RandomForestClassifier())])
# fit the model
pipeline.fit(X, y)
# save pipeline as model file
joblib.dump(pipeline, 'model.mod')
# load model from file
model = joblib.load('model.mod')
# define new data
row = [2, 1, 530101, 38.50, 66, 28, 3, 3, nan, 2, 5, 4, 4, nan, nan, nan, 3, 5, 45.00, 8.40, nan, nan, 2, 11300, 00000, 00000, 2]
# make a prediction
yhat = model.predict([row])
# summarize prediction
print('Predicted Class: %d' % yhat[0])
Kết quả thực hiện:
Predicted Class: 2
Chú ý quan trọng là Missing Data trong mẫu dữ liệu mới phải được đánh dấu là nan thì model mới có thể hiểu được.
3. Kết luận
Hôm nay, chúng ta đã tìm hiểu về phương pháp kNN Imputation trong việc giải quyết vấn đề Missing Data. Đây là một phương pháp đơn giản vì nó chỉ dựa trên các mẫu dữ liệu lân cận để tìm ra giá trị mới thay thế cho Missing Data. Cũng giống như Statistical Imputation, kNN Imputation tỏ ra hiệu quả cao trong một số trường hợp cụ thể.
Toàn bộ code của bài này, các bạn có thể tham khảo tại đây.
Trong bài tiếp theo, chúng ta sẽ tìm hiểu về phương pháp tiếp theo trong việc xử lý Missing Data, đó là Iteratove Imputation. Mời các bạn đón đọc.
4. Tham khảo
[1] Jason Brownlee, “Data Preparation for Machine Learning”, Book: https://machinelearningmastery.com/data-preparation-for-machine-learning/.