DP4ML - Data Cleaning - Các xử lý cơ bản

Bài thứ 2 trong chuỗi các bài viết về chủ đề Data Preparation cho các mô hình ML. Trong bài này, chúng ta sẽ bàn về nhiệm vụ Data Cleaning, tiếng việt gọi là làm sạch dữ liệu.
Data Cleaning là một bước rất quan trong trong bất kỳ dự án ML nào. Trong dữ liệu dạng bảng (tabular data), có nhiều kỹ thuật phân tích thống kê và trực quan hóa dữ liệu khác nhau mà bạn có thể sử dụng để khám phá dữ liệu của mình nhằm xác định các thao tác làm sạch dữ liệu mà bạn có thể muốn thực hiện.
Trước khi chuyển sang các phương pháp phức tạp, có một số thao tác rất cơ bản mà bạn có thể nên thực hiện trên mọi dự án học máy. Những điều này cơ bản đến mức chúng thường bị các kỹ sư AI/Ml dày dạn kinh nghiệm bỏ qua, nhưng lại rất quan trọng đến mức nếu bỏ qua, các mô hình có thể hoạt động một cách thiếu chính xác hoặc không thể sử dụng được.
Chúng ta sẽ sử dụng 2 bộ dữ liệu Oil Spill Dataset và Iris Flowers Dataset để thực hành. Chúng đều là những bộ dữ liệu tiêu chuẩn cho việc học tập ML.
1. Nhận diện và xóa các features chỉ chứa 1 giá trị (tất cả giá trị trong các hàng của 1 cột đều bằng nhau)
Các features mà chỉ có một giá trị duy nhất chắc chắn không có ý nghĩa cho việc mô hình hóa. Những features như vậy được gọi là zero-variance, bởi vì nếu chúng ta đo phương sai của chúng, sẽ thu được giá trị là 0.
Hình dưới đây là ví dụ về features kiểu này:

1.1 Sử dụng Numpy
Để phát hiện ra các features này, chúng ta có thể sử dụng hàm unique() của Numpy, nó sẽ cho ta biết số lượng của các giá trị duy nhất trong mỗi cột. Ví dụ: 2 2 -> 1, 2 3 -> 2, 4 5 4 -> 2, …
# summarize the number of unique values for each column using numpy
from numpy import loadtxt
from numpy import unique
# load the dataset
data = loadtxt( ' oil-spill.csv ' , delimiter= ' , ' )
# summarize the number of unique values in each column
for i in range(data.shape[1]):
print(i, len(unique(data[:, i]))
Chạy code trên sẽ in ra kết quả như sau:
0 238
1 297
2 927
3 933
4 179
5 375
6 820
7 618
8 561
9 57
10 577
11 59
12 73
13 107
14 53
15 91
16 893
17 810
18 170
19 53
20 68
21 9
22 1
23 92
24 9
25 8
26 9
27 308
28 447
29 392
30 107
31 42
32 4
33 45
34 141
35 110
36 3
37 758
38 9
39 9
40 388
41 220
42 644
43 649
44 499
45 2
46 937
47 169
48 286
49 2
Nhìn vào đây, ta có thể thấy ngay rằng cột 22 chỉ chứa 1 giá trị duy nhất. Vì thế, nó nên được loại bỏ khỏi dataset.
1.2 Sử dụng Pandas
Một cách làm khác là sử dụng hàm nunique() của Pandas như dưới đây:
# summarize the number of unique values for each column using numpy
from pandas import read_csv
# load the dataset
df = read_csv( ' oil-spill.csv ' , header=None)
# summarize the number of unique values in each column
print(df.nunique())
Chạy code trên sẽ thu được kết quả tương tự như Numpy.
Để xóa những cột chỉ chứa 1 giá trị duy nhất, ta thực hiện như sau:
# delete columns with a single unique value
from pandas import read_csv
# load the dataset
df = read_csv( ' oil-spill.csv ' , header=None)
print(df.shape)
# get number of unique values for each column
counts = df.nunique()
# record columns to delete
to_del = [i for i,v in enumerate(counts) if v == 1]
print(to_del)
# drop useless columns
df.drop(to_del, axis=1, inplace=True)
print(df.shape)
Kết quả thực hiện:
(937, 50)
[22]
(937, 49)
1.3 Sử dụng Scikit-learn
Thư viện Sckit-learn cung cấp lớp VarianceThreshold giúp ta nhận ra các cột chỉ có 1 giá trị dựa vào tính chất của phương sai. Nếu tất cả các giá trị trong một cột đều bằng nhau thì phương sai của chúng bằng 0. Cách sử dụng như sau:
# example of applying the variance threshold for feature selection
from pandas import read_csv
from sklearn.feature_selection import VarianceThreshold
# load the dataset
df = read_csv( 'oil-spill.csv' , header=None)
# split data into inputs and outputs
data = df.values
X = data[:, :-1]
y = data[:, -1]
print(X.shape, y.shape)
# define the transform
transform = VarianceThreshold(threshold=0)
# transform the input data
X_sel = transform.fit_transform(X)
print(X_sel.shape)
Một instance của lớp VarianceThreshold được tạo với tham số threshold=0 được cung cấp (đây là giá trị mặc định, bạn có thể bỏ qua không cần chỉ ra nếu muốn sử dụng giá trị mặc định này). Sau đó, nó dược fit và áp dụng vào tập dữ liệu thông qua hàm fit_transform() để tạo ra một phiên bản đã biến đổi của dữ liệu mà ở đó, các cột có phương sai không lớn hơn giá trị threshold sẽ bị xóa bỏ.
Kết quả chạy code trên như sau:
(937, 49) (937,)
(937, 48)
Trước, 50 cột. Sau khi biến đổi còn lại 49 cột.
Ban đầu, dataset có 50 cột, cột số 22 chỉ chứa 1 giá trị duy nhất nên bị xóa, còn lại 49 cột trong dataset.
2. Xem xét các cột có rất ít giá trị (rất nhiều giá trị trong các hàng của 1 cột trùng nhau)
Quan sát lại kết quả từ phần 1, ta thấy rằng có những cột có rất ít giá trị. Ví dụ, các cột 45, 32, và 38 chỉ có 2,4, và 9 giá trị không trùng nhau, tương ứng theo thứ tự. Những cột mà có ít giá trị như thế này, theo lý thuyết nên có dạng Ordinal hoặc Categorical. Tuy nhiên, trong trường hợp này, Oil Spill Dataset chỉ chứa giá trị dạng số nên hiện tượng này có thể coi là bất thường. Near-zero là tên gọi được đặt cho chúng bởi vì nếu tính toán thì giá trị phương sai của chúng rất gần 0.
2.1 Sử dung Numpy
Để có cái nhìn rõ hơn, chúng ta sẽ tính phần trăm số lượng giá trị không trùng của mỗi cột theo tổng số hàng và in ra những cột có phần trăm nhỏ hơn 1:
# summarize the percentage of unique values for each column using numpy
from numpy import loadtxt
from numpy import unique
# load the dataset
data = loadtxt( ' oil-spill.csv ' , delimiter= ' , ' )
# summarize the number of unique values in each column
for i in range(data.shape[1]):
num = len(unique(data[:, i]))
percentage = float(num) / data.shape[0] * 100
if percentage < 1:
print( ' %d, %d, %.1f%% ' % (i, num, percentage))
Kết quả:
21, 9, 1.0%
22, 1, 0.1%
24, 9, 1.0%
25, 8, 0.9%
26, 9, 1.0%
32, 4, 0.4%
36, 3, 0.3%
38, 9, 1.0%
39, 9, 1.0%
45, 2, 0.2%
49, 2, 0.2%
11 cột trong tổng số 50 cột có giá trị phần trăm không lớn hơn 1. Điều này, ko có nghĩa là chúng ta nên xóa bỏ chúng ngay lập tức như đối với các cột chỉ có 1 giá trị, mà chúng ta nên xem xét thực hiện các lựa chọn sau:
- Chuyển sang dạng Ordinal
- Chuyển sang dạng Categorical
- Xóa bỏ
Hai lựa chọn đầu có thể căn cứ vào thông tin về dataset để quyết định có thực hiện hay không? Thực hiện các lựa chọn một cách độc lập và so sánh kết quả của model trong mỗi trường hợp với nhau xem lựa chọn nào mang lại kết quả tốt nhất.
2.2 Sử dụng Pandas
Code dưới đây sử dụng Pandas để tính toán và xóa bỏ 11 cột có phần trăm không lớn hơn 1:
# delete columns where number of unique values is less than 1% of the rows
from pandas import read_csv
# load the dataset
df = read_csv( ' oil-spill.csv ' , header=None)
print(df.shape)
# get number of unique values for each column
counts = df.nunique()
# record columns to delete
to_del = [i for i,v in enumerate(counts) if (float(v)/df.shape[0]*100) < 1]
print(to_del)
# drop useless columns
df.drop(to_del, axis=1, inplace=True)
print(df.shape)
Kết quả thực hiện:
(937, 50)
[21, 22, 24, 25, 26, 32, 36, 38, 39, 45, 49]
(937, 39)
Trước, 50 cột. Xóa các cột [21, 22, 24, 25, 26, 32, 36, 38, 39, 45, 49]. Còn lại, 39 cột.
2.3 Sử dụng Scikit-learn
Vẫn theo tính chất của phương sai, ta biết rằng, những cột mà có rất ít giá trị thì phương sai của chúng rất nhỏ, chỉ lớn hơn 0.0 một chút xíu. Vì thế, tương tự như mục 1.3, ta có thể sử dụng lớp VarianceThreshold() với giá trị threshold > 0.0 để loại bỏ những cột đó.
# explore the effect of the variance thresholds on the number of selected features
from numpy import arange
from pandas import read_csv
from sklearn.feature_selection import VarianceThreshold
from matplotlib import pyplot
# load the dataset
df = read_csv( ' oil-spill.csv ' , header=None)
# split data into inputs and outputs
data = df.values
X = data[:, :-1]
y = data[:, -1]
print(X.shape, y.shape)
# define thresholds to check
thresholds = arange(0.0, 0.55, 0.05)
# apply transform with each threshold
results = list()
for t in thresholds:
# define the transform
transform = VarianceThreshold(threshold=t)
# transform the input data
X_sel = transform.fit_transform(X)
# determine the number of input features
n_features = X_sel.shape[1]
print( ' >Threshold=%.2f, Features=%d ' % (t, n_features))
# store the result
results.append(n_features)
# plot the threshold vs the number of selected features
pyplot.plot(thresholds, results)
pyplot.show()
Trong ví dụ trên, ta cho threshold nhận giá trị thay đổi từ 0.0 đến 0.55, với bước nhảy 0.05. Kết quả thực hiện:
(937, 49) (937,)
>Threshold=0.00, Features=48
>Threshold=0.05, Features=37
>Threshold=0.10, Features=36
>Threshold=0.15, Features=35
>Threshold=0.20, Features=35
>Threshold=0.25, Features=35
>Threshold=0.30, Features=35
>Threshold=0.35, Features=35
>Threshold=0.40, Features=35
>Threshold=0.45, Features=33
>Threshold=0.50, Features=31
Ta thấy, ban đầu có 50 cột, và số lượng cột giảm dần khi tăng giá trị của threshold. Đồ thị sau thể hiện mối quan hệ giữa threshold và số lượng cột còn lại trong dataset sau khi biến đổi.
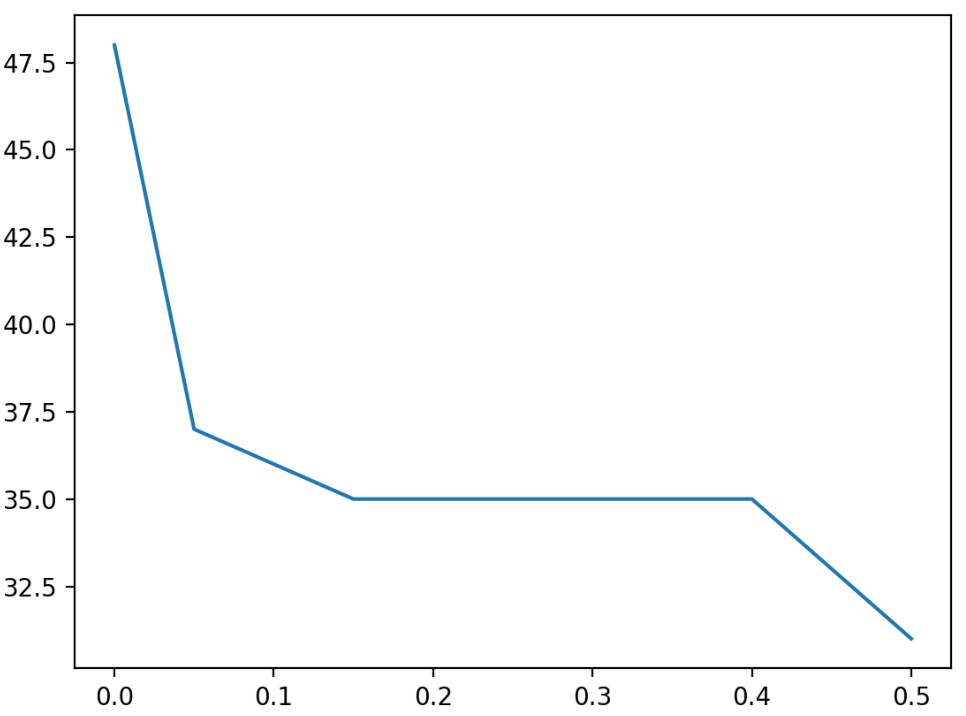
3. Nhận diện và xóa các hàng trùng nhau
Các hàng có dữ liệu giống hệt nhau gần như là vô nghĩa đối với quá trình mô hình hóa, thậm chí là gây ra những tác động tiêu cực trong quá trình đánh giá mô hình. Bởi vì, cùng một dữ liệu nhưng có thể xuất hiện trong cả 2 tập Train và Test. Về mặt xác suất, chúng ta có thể coi sự trùng lặp như là 1 sự điều chỉnh phân phối dữ liệu và nó có thể có 1 chút lợi ích nếu bạn muốn mô hình của mình thiên vị theo hướng có lợi cho bạn (purposefully bias). Tuy nhiên, trong hầu hết trường hợp, ML model được mong đợi hoạt động một cách minh bạch, chính xác nhất có thể. Vì thế, một cách hiển nhiên, chúng ta cần tìm ra và xóa bỏ chúng khỏi tập dữ liệu trước khi tiến hành huấn luyện mô hình.
Để kiểm tra dữ liệu trùng lặp trong các hàng, ta có thể sử dụng dung hàm dupplicate() của Pandas như sau:
# locate rows of duplicate data
from pandas import read_csv
# load the dataset
df = read_csv( 'iris.csv' , header=None)
# calculate duplicates
dups = df.duplicated()
# report if there are any duplicates
print(dups.any())
# list all duplicate rows
print(df[dups])
Kết quả thực hiện:
True
0 1 2 3 4
34 4.9 3.1 1.5 0.1 Iris-setosa
37 4.9 3.1 1.5 0.1 Iris-setosa
142 5.8 2.7 5.1 1.9 Iris-virginica
Đầu tiên, kết quả kiểm tra xem có dự trùng lặp dữ liệu hay không được báo cáo. Trong trường hợp này là có (True). Tiếp theo sau là danh sách các hàng bị trùng dữ liệu với 1 hàng nào đó phía trên. Cụ thể, dữ liệu ở hàng 34 bị trùng với 1 hàng nào đó từ 0->33, hàng 37 bị trùng với 1 hàng nào đó từ 0->36, hàng 142 bị trùng với 1 hàng nào đó từ 0->141.
Biết được kết quả kiểm tra trùng lặp dữ liệu rồi, chúng ta sẽ tiến hành xóa chúng đi, sử dụng hàm drop_duplicates() của Pandas như sau:
# delete rows of duplicate data from the dataset
from pandas import read_csv
# load the dataset
df = read_csv( 'iris.csv' , header=None)
print(df.shape)
# delete duplicate rows
df.drop_duplicates(inplace=True)
print(df.shape)
Kết quả thực hiện:
(150, 5)
(147, 5)
Ban đầu, 150 hàng. Sau khi xóa các hàng trùng nhau, còn lại 147 hàng.
4. Kết luận
Mình sẽ kết thúc bài này tại đây. Trong bài này, chúng ta đã khám phá một số lỗi cơ bản của dữ liệu và phương pháp xử lý chúng.
Toàn bộ code của bài này, các bạn có thể tham khảo tại đây.
Trong bài tiếp theo, chúng ta sẽ tiếp tục tìm hiểu về một vấn đề khác của Data Cleaning, đó là nhận diện và xử lý dữ liệu Outlier . Mời các bạn đón đọc.
5. Tham khảo
[1] Jason Brownlee, “Data Preparation for Machine Learning”, Book: https://machinelearningmastery.com/data-preparation-for-machine-learning/.