DP4ML - Những kiến thức cơ bản

Series các bài viết tiếp theo, mình sẽ tập trung vào chủ đề chuẩn bị dữ liệu (Data Preparation) để huấn luyện các mô hình ML (DP4ML). Đây có thể coi là bước quan trọng nhất để tạo ra được một ML model có độ chính xác cao. Có rất nhiều kiến thức, thuật toán, kỹ thuật có thể được áp dụng ở phần này. Mình sẽ cùng các bạn đi từng bước, khám phá dần dần để giúp bạn dễ dàng nắm bắt và áp dụng những gì học được vào giải quyết các bài toán của bạn.
Bài đầu tiên, mình sẽ chủ yếu nhắc lại một số kiến thức, khái niệm chung về ML, cũng như công đọan Data Preparation.
1. Giới thiệu chung
1.1 Các bước xây dựng Machine Learning model
Mỗi dự án ML nói chung đều bao gồm một số bước thực hiện giống nhau (cùng chiến lược), nhưng khác nhau vì dữ liệu cụ thể của mỗi dự án. Vì thế mà các kỹ thuật xử lý tại mỗi bước cũng sẽ khác nhau đối với từng dự án (khác chiến thuật). Điều này làm cho mỗi dự án học máyMLw trở thành duy nhất. Không ai có thể cho bạn biết kết quả tốt nhất là gì hay làm thế nào để đạt được nó. Bạn phải thiết lập một giá trị hiệu suất làm điểm tham chiếu, sau đó so sánh với hiệu suất từ tất cả các mô hình mà bạn có thể xây dựng được theo các cách thức, thuật toán khác nhau. Dựa vào các kết quả so sánh đó mà bạn có thể kết luận được rằng mô hình nào là tốt nhất, tối ưu nhất trên tập dữ liệu bạn có. Tất nhiên, bạn không hề đơn độc trong quá trình làm việc của mình. Các kiến thức, kỹ thuật đã được đúc kết, bạn có thể lấy ra sử dụng rất dễ dàng. Việc của bạn chỉ là khi nào thì lấy ra kỹ thuật nào mà thôi.
Chiến lược của các dự án ML có thể được tóm tắt trong 4 bước như sau: Định nghĩa vấn đề, Chuẩn bị dữ liệu, Đánh giá mô hình và Hoàn thiện mô hình.
a, Bước 1 - Định nghĩa vấn đề
Bước này liên quan đến việc tìm hiểu đầy đủ về dự án để chọn lựa thuật toán, và chỉ tiêu đánh giá phù hợp. Ví dụ, đó là bài toán phân loại (classification) - đánh giá bằng độ chính xác hay hồi quy (regression) - đánh giá bằng chỉ số MSE? Nó cũng liên quan đến việc định hướng thu thập dữ liệu, là tiền đề cho bước tiếp theo.
b, Bước 2 - Thu thập dữ liệu
Khi đã nhận thức rõ ràng vấn đề cần giải quyết, chúng ta sẽ bắt tay vào việc tìm kiếm, thu thập dữ liệu. Dữ liệu có thể đến từ nhiều nguồn với các định dạng khác nhau. Vì thế, cần phải có kế hoạch lưu trữ, xử lý, quản lý cho phù hợp.
c, Bước 3 - Chuẩn bị dữ liệu
Bước này liên quan đến việc chuyển đổi dữ liệu thô đã được thu thập thành một dạng có thể được sử dụng trong mô hình hóa. Các kỹ thuật tiền xử lý dữ liệu thường đề cập đến việc bổ sung, xóa hoặc chuyển đổi dữ liệu thành các dạng khác nhau. Bạn cũng nên hỏi ý kiến chuyên gia tại bước này để tìm ra những thông tin hữu ích nhất trong đống dữ liệu của mình.
d, Bước 4 - Lựa chọn và đánh giá mô hình
Bước này liên quan đến việc lựa chọn và đánh giá các mô hình học máy trên tập dữ liệu của bạn. Có rất nhiều thuật toán ML, và bạn thường không thể biết chính xác thuật toán nào sẽ giải quyết tốt cho bài toán của bạn. Các thông thường là xây dựng một mô hình làm cơ sở (base model) tham chiếu cho các mô hình khác. Các mô hình sau đó phải có giá trị metrics lớn hơn Base Model mới được xem xét sử dụng. Đối với những tập dữ liệu lớn, có thể chia nhỏ ra thành nhiều phần, sử dụng chiến thuật k_Folds để có thể nhanh chóng đạt được kết quả đánh giá.
e, Bước 5- Hoàn thiện mô hình
Sau khi có kết quả đánh giá và lựa chọn được mô hình phù hợp nhất với bài toán, ta tiến hành huấn luyện mô hình đó trên toàn bộ tập dữ liệu lớn. Model được huấn luyện xong và đáp ứng được các yêu cầu cụ thể đặt ra có thể được mang đi tích hợp vào các hệ thống khác để sử dụng. Quá trình này có thể được chia ra thành nhiều công đoạn nhỏ hơn như Giám sát, Cập nhật, …
Tiếp theo, mình sẽ đi chi tiết vào bước 3.
1.2 Chuẩn bị dữ liệu - Data Preparation là gì?
Như chúng ta đã biết, các ML model không thể sử dụng trực tiếp dữ liệu thô sau khi được thu thập. Một số lý do là:
- Các thuật toán ML yêu cầu dữ liệu phải ở dạng số - Numbers
- Dữ liệu thô có thể chứa các loại nhiễu, lỗi có thể gây ra ảnh hưởng tiêu cực đến quá trình học của các mô hình ML
Do đó, dữ liệu thô cần phải trải qua một bước tinh chỉnh trước khi đưa vào mô hình để huấn luyện. Quá trình này thường được gọi tên là Data Preparation. Một số tên khác cũng có thể được sử dụng là Data Wrangling, Data Cleaning, Data Preprocessing, Feature Engineering, … mặc dù những cái tên này chính xác hơn là để chỉ các công việc cần hoàn thành trong quá trình Data Preparation.
Đi vào chi tiết hơn, các công việc cần phải thực hiện trong quá trình Data Preparation là:
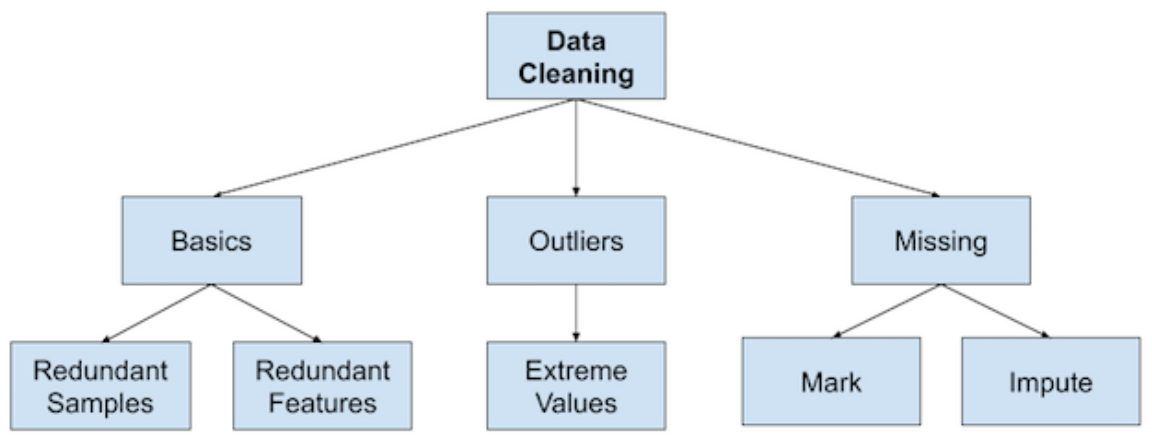
a, Data Cleaning
Nhận diện và sửa các lỗi như thiếu hụt (missing) dữ liệu, dữ liệu bất thường (outlier), dữ liệu trùng lặp (dupplicate), …
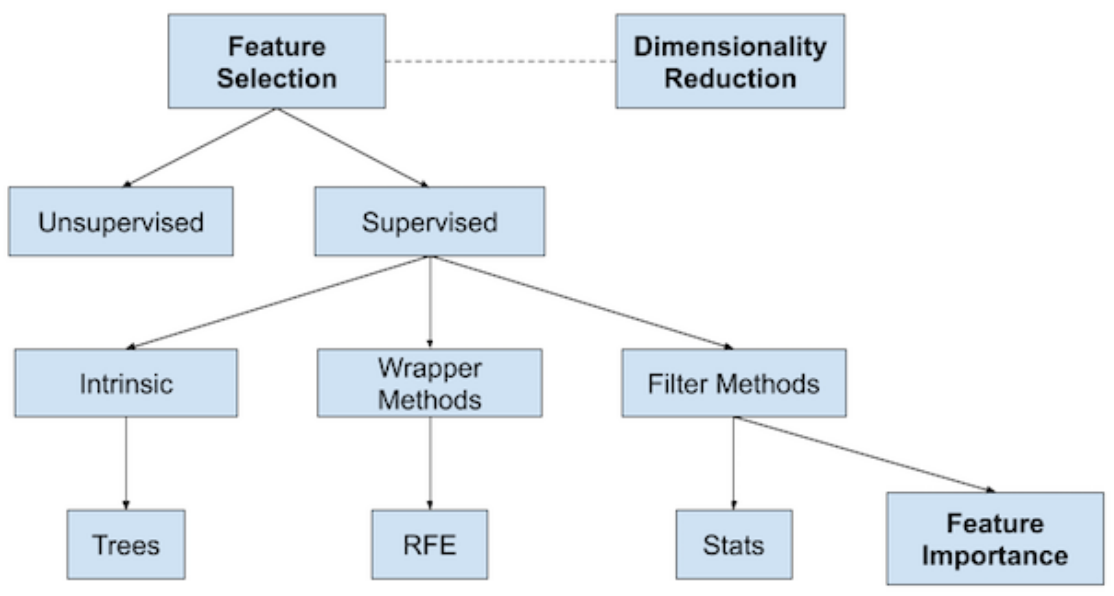
b, Feature Selection
Tìm ra mỗi liên hệ giữa các features và nhãn cần dự đoán của bài toán. Từ đó bỏ đi các features có sự liên quan ít đi để mô hình có thể tập trung vào những features có giá trị.
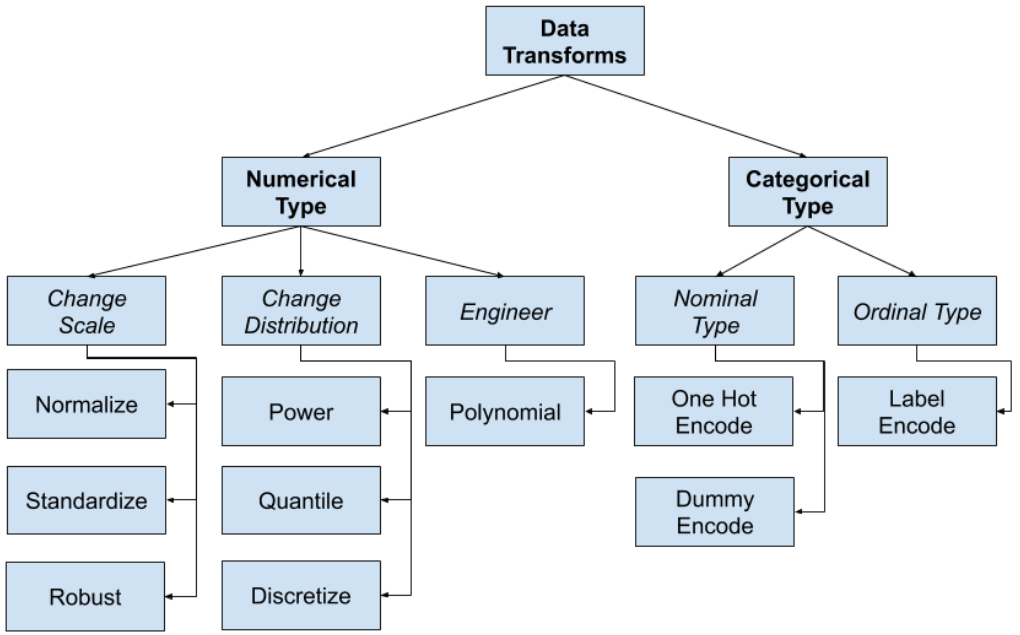
c, Data Transforms
Thay đổi kiểu, phạm vi và phân phối của dữ liệu.
d, Feature Engineering
Tạo ra các features mới từ dữ liệu hiện có.
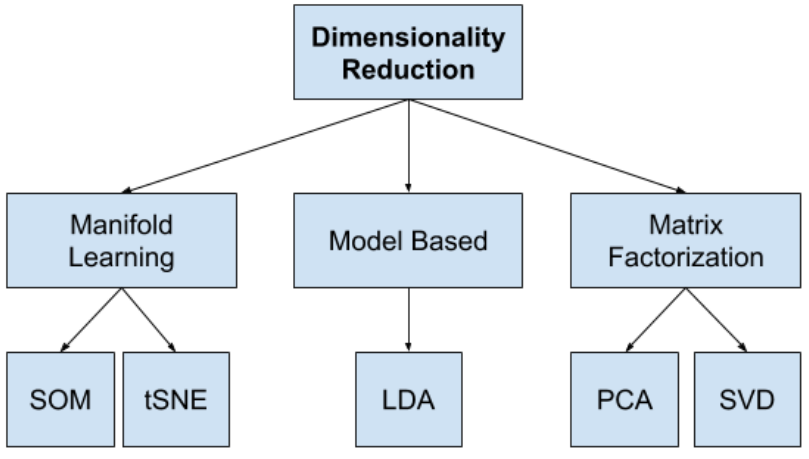
e, Dimensionality Reduction
Ánh xạ dữ liệu lên một không gian mới để giảm kích thước của dữ liệu.
Mỗi công việc này đều đòi hỏi những kỹ năng cụ thể, hiểu biết về công cụ, kỹ thuật áp dụng để có thể cho ra kết quả tốt nhất. Chúng ta sẽ đi chi tiết trong các bài sau.
1.3 Làm thế nào để biết nên áp dụng kỹ thụật Data Preparation nào?
Đứng trước một tập dữ liệu thô vừa được thu thập, bạn phân vân không biết nên làm như thế nào? bắt đầu từ đâu? Dưới đây là một vài gợi ý:
- Tìm hiễu kỹ càng yêu cầu bài toán và thông tin về dữ liệu thô
Việc này là bước khởi đầu để bạn có cái nhìn tổng thể về dữ liệu, giúp bạn trả lời các câu hỏi: dữ liệu có đúng/đủ không? liệu có sai sót gì trong quá trình thu thập không? … Từ đó, giúp bạn loại đi được những dữ liệu không phù hợp và ý niệm về việc cần phải có dữ liệu tinh ở dạng như thế nào?
- Sử dụng phương pháp thống kê, phân tích
Các công cụ thống kê như Mean, Standard Deviation, Sum, Count, … có thể giúp bạn nhận ra dữ liệu có bị thiếu hay không? Đang được phân phối như thế nào? Ở dạng Numbers hay Categories, … Biết được những điều này rồi, bạn chỉ cần chọn kỹ thuật xử lý tương ứng.
- Sử dụng phương pháp trực quan hóa dữ liệu
Biểu diễn lên đồ thị cũng là 1 cách hiệu quả để hiểu hơn về dữ liệu. Các vấn đề như mức độ tương quan giữa các features, có tồn tại hay không dữ liệu Outlier, … đều có thể nhận biết được thông qua đồ thị.
2. Phân tích các chiến lược cho Data Preparation
2.1 Naive Approach
Data Preparation là quá trình chuyển đổi dữ liệu thô thành một dạng thích hợp để mô hình hóa. Một cách tiếp cận đơn giản (Naive Approach) là áp dụng biến đổi trên toàn bộ tập dữ liệu trước khi phân chia thành tập Train và Test để huấn luyện và đánh giá hiệu suất của mô hình. Điều này có thể dẫn đến một vấn đề gọi là rò rỉ dữ liệu (Data Leakage), trong đó thông tin của dữ liệu trong tập Test bị rò rỉ vào tập Train. Việc đó làm cho sự ước tính độ chính xác về hiệu suất của mô hình khi đưa ra dự đoán trên dữ liệu mới sẽ không còn đáng tin cậy nữa.
Code ví dụ cho chiến lược này như sau:
# naive approach to normalizing the data before splitting the data and evaluating the model
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# standardize the dataset
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# fit the model
model = LogisticRegression()
model.fit(X_train, y_train)
# evaluate the model
yhat = model.predict(X_test)
# evaluate predictions
accuracy = accuracy_score(y_test, yhat)
print( 'Accuracy: %.3f ' % (accuracy*100))
Đoạn code trên thực hiện các việc: tạo dữ liệu giả, chuẩn hóa dữ liệu, chia dữ liệu thành 2 tập Train và Test, huấn luyện và đánh giá mô hình.
Kết quả chạy thu được độ chính xác là 84.848%. Khá cao, nhưng ta biết rằng cách tiếp cận này tiềm ẩn nguy cơ như đã phân tích nên ta không nên sử dụng kết quả này.
2.2 Standard Approach
Chiến lược chuẩn của Data Preparation sẽ như sau:
- Chia dữ liệu thành 2 tập Train và Test
- Huấn luyện (Fit) các thuật toán của Data Preparation chỉ trên tập Train
- Áp dụng các thuật toán của Data Preparation đã huấn luyện vào cả 2 tập Train và Test
- Huấn luyện model trên tập Train
- Đánh giá model trên tập Test
Code ví dụ:
# correct approach for normalizing the data after the data is split before the model is
evaluated
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# define the scaler
scaler = MinMaxScaler()
# fit on the training dataset
scaler.fit(X_train)
# scale the training dataset
X_train = scaler.transform(X_train)
# scale the test dataset
X_test = scaler.transform(X_test)
# fit the model
model = LogisticRegression()
model.fit(X_train, y_train)
# evaluate the model
yhat = model.predict(X_test)
# evaluate predictions
accuracy = accuracy_score(y_test, yhat)
print( 'Accuracy: %.3f ' % (accuracy*100))
Đọan code này thực hiện các công việc: tạo dữ liệu giả, chia dữ liệu thành 2 tập Train và Test, chuẩn hóa dữ liệu, huấn luyện và đánh giá mô hình. Kết quả chạy code cho ra Accuracy: 84.455.
Chú ý: Đối với cách phân chia dữ liệu theo kiểu k-Fold, những phân tích về 2 chiến lược trên vẫn đúng. Mình có cả code ví dụ cho phần này, bạn có thể xem trên github của mình.
3. Kết luận
Kết thúc bài đầu tiên về chủ đề Data Preparation cho các ML model. Chúng ta đã được ôn lại các bước để thực hiện huấn luyện một mô hình ML, chi tiết các công việc cần thực hiện và các chiến lược cho phần Data Preparation.
Toàn bộ code của bài này, các bạn có thể tham khảo tại đây.
Trong bài tiếp theo, chúng ta sẽ đi sâu vào các kỹ thuật giải quyết công việc Data Cleaning . Mời các bạn đón đọc.
4. Tham khảo
[1] Jason Brownlee, “Data Preparation for Machine Learning”, Book: https://machinelearningmastery.com/data-preparation-for-machine-learning/.