Thực hành xây dựng RS sử dụng Deep Learning

Đây là bài thứ 3 trong chuỗi bài viết về Recommender System. Trong bài này, chúng ta sẽ thực hành xây dựng một RS sử dụng kỹ thuật Deep Learning.
Ngày nay, Deep Learning đã đi sâu vào rất nhiều lĩnh vực, giải quyết được rất nhiều bài toán khó trong thực tế, từ Computer Vision cho đến Natual Language Processing. Recommender System cũng được hưởng lợi từ sự phát triển mạnh mẽ đó. Có thể nói rằng, với sự tham gia của Deep Learning, các RS hiện đại ngày nay như Youtube, Amazon, Netflix, Facebook, … đã đạt được State-of-Art, bỏ xa các phương pháp truyền thống trong cuộc đua mang lại lợi ich thiết thực cho các doanh nghiệp.
1. Đặt vấn đề
Một website chiếu phim muốn thu hút nhiều User hơn. Họ muốn bạn - 1 Data Scientist giúp họ xây dựng một RS để đề xuất các bộ phim phù hợp cho người dùng mỗi khi họ ghé vào website của họ. Sau khi xem xét kỹ yêu cầu bài toán và dữ liệu hiện có, bạn quyết định xây dựng RS sử dụng kỹ thuật Deep Learning.
2. Chuẩn bị dữ liệu
Download dữ liệu tại đây.
Có rất nhiều thông tin về các bộ phim được lưu rải rác trong các file khác nhau: tên, thể loại, diễn viên, đạo diễn, năm sản xuất, quốc gia sản xuất, đường dẫn xem phim, … Bộ dataset này được thu thập từ năm 1995 đến năm 2015 và được cung cấp bởi MovieLends. Ở bài này, chúng ta chỉ tập trung vào thông tin Rating trong file rating.csv.
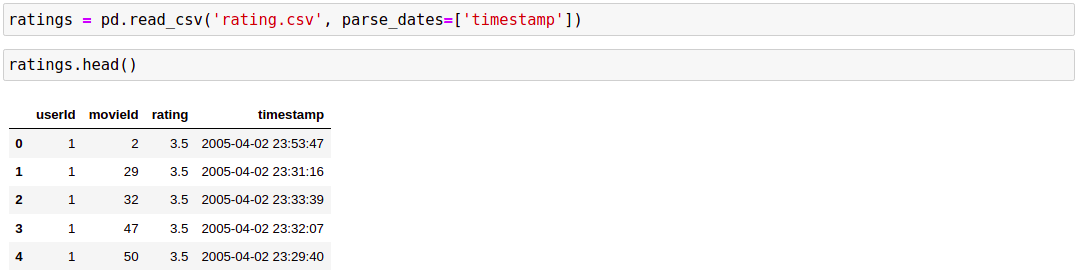
3. Data Preprocessing
Vì kích thước của bộ dữ liệu này khá lớn, nên nếu máy tính của bạn không đủ mạnh thì sẽ không thể xử lý hết được, hoặc là sẽ mất rất nhiều thời gian. Máy tính của mình là Core i7, 16GB RAM, GTX Gefore 1660i (6GB), mình đã thử chạy toàn bộ dataset nhưng không nổi. Vì thế, mình quyết định chỉ sử dụng 30% trong tổng số dữ liệu để thực hành. Nếu bạn có máy tính cấu hình mạnh hơn, bạn có thể thử với toàn bộ tập dữ liệu này.

Với 30% dữ liệu, chúng ta có 6.027.314 hàng trong DataFrame. Mỗi hàng tương ứng với một Rating tạo bởi một User đối với 1 bộ phim (item). Số lượng Users tham gia vào viêc Rating là 41.547. Nói chung thì dữ liệu như này vẫn là khá lớn.
3. Train-Test Split
Cùng với Rating, trong file rating.csv còn có cột timestamp chứa thông tin về thời gian thực hiện Rating của User. Dựa vào thông tin này, chúng ta sẽ tiến hành chia tập dữ liệu của chúng ta thành 2 phần Train và Test theo chiến lược leave-one-out. Nếu bạn chưa biết thì leave-one-out là cách chia dữ liệu theo thời gian, tức là sử dụng những dữ liệu ở thời điểm gần hiện tại làm tập Test, còn lại làm tập Train. Xem ví dụ dưới đây:
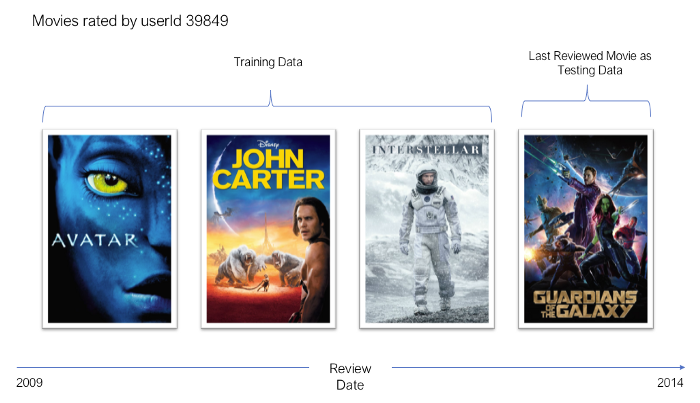
Cách chia này thường được sử dụng cho các bài toán RS và Time Series. Nếu thực hiện như cách truyền thống là xáo trộn ngẫu nhiên rồi chia thì sẽ không công bằng vì chúng ta có thể đang sử dụng những dữ liệu gần đây để huấn luyện và những dữ liệu trước đó để kiểm tra. Điều này dẫn đến rò rỉ dữ liệu với xu hướng nhìn trước và hiệu suất của mô hình được đào tạo sẽ không thể tổng quát hóa thành hiệu suất trong thế giới thực.
Code dưới đây thực hiện leave-one-out:

4. Convert Dataset into Implicit Dataset
Các bài toán RS trong thực tế thường được giải quyết sử dụng dữ liệu dạng Implicit vì dữ liệu dạng này dễ dàng thu thập được từ người dùng thông qua Log hoạt động của hệ thống. Trong bài này, chúng ta cung sẽ sử dụng Implicit Dataset để huấn luyện model.
Tuy nhiên, tập MovieLends chỉ có dữ liệu dạng Explicit (chính là Rating của User đối với Item). Để chuyển sang dạng Implicit, chúng ta sẽ tiến hành chuyển đổi các giá trị Rating thành “1” (positive class), ngụ ý rằng User có tương tác với Item đó. Thay vì cố gắng dự đoán giá trị của Rating, ta sẽ dự đoán liệu User có tương tác với Item đó hay không? Tương tác ở đây có thể hiểu là hành vi Click vào nút Like của Item, mua Item, hay xem Item. Những Items này sẽ được đề xuất cho User, làm tăng khả năng mua hàng của User.
Sau khi thực hiện việc chuyển đổi Rating thành “1” thì chúng ta mới chỉ có Positive class, cần phải có thêm Negative class nữa mới có thể huấn luyện được model. Negative class (0) ở đây được giả định là User không tương tác, không quan tâm đến Item. Mặc dù điều giả định này không hoàn toàn đúng, vì có thể User chưa biết đến Item đó, nhưng nó vẫn tỏ ra khá hiệu quả trong thực tế.
Code dưới đây sinh ra 4 Negative Samples tương ứng với mỗi hàng trong DataFrame. Tỉ lệ Positive : Negative là 1:4 được chọn tùy ý. Bạn có thể thử theo ý bạn, nhưng cá nhân mình thấy thì tỉ lệ này làm cho model hoạt động khá ổn trong thực tế.
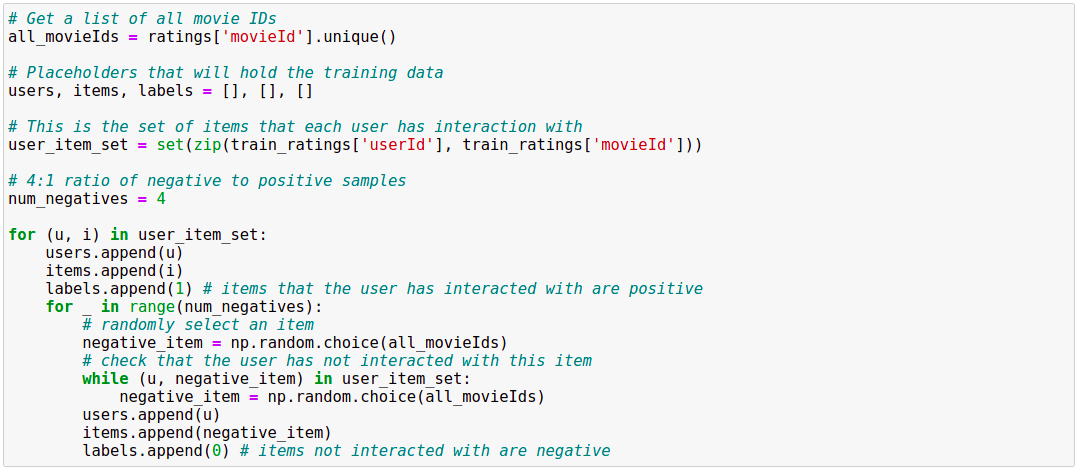
Sử dụng Pytorch, ta viết lại đoạn code trên vào class Dataset để thuận tiện cho việc huấn luyện model như sau:
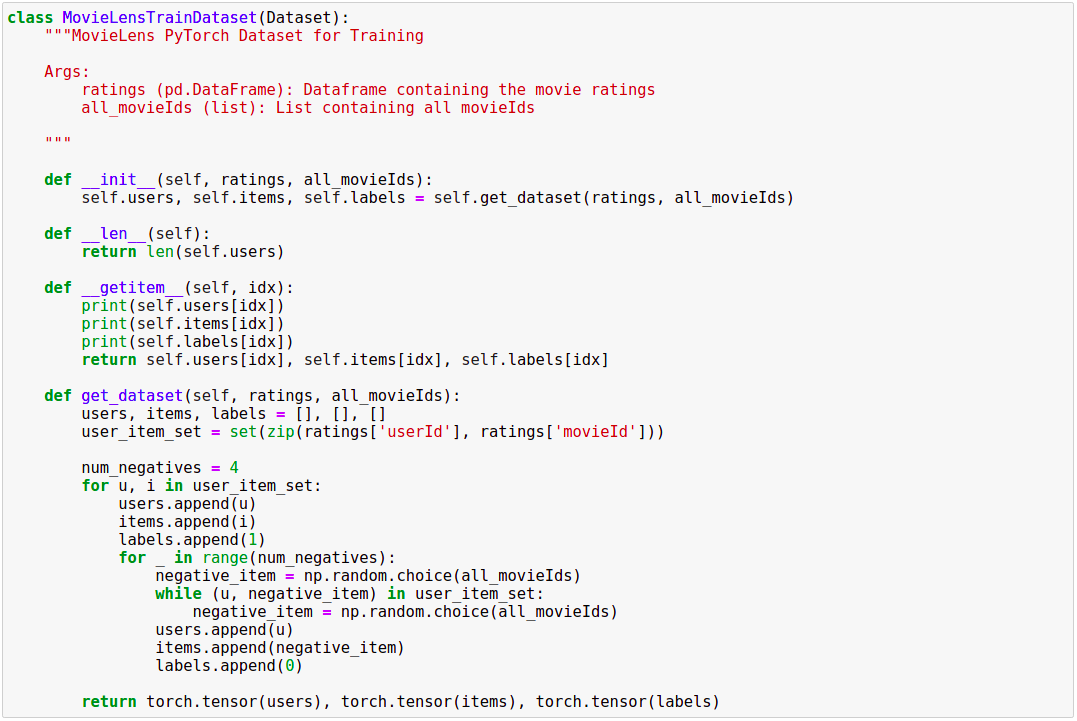
5. Định nghĩa Deep Learning model
Đã có một số kiến trúc Deep Learning model được đề xuất cho bài toán RS. Trong số đó, đề xuất của He và cộng sự có tên là Neural Collaborative Filtering (NFC) được sử dụng phổ biến hơn cả bởi tính đơn giản của nó. Chúng ta cũng sẽ sử dụng nó trong bài này.
Kiến trúc của NFC được mô tả như sau:
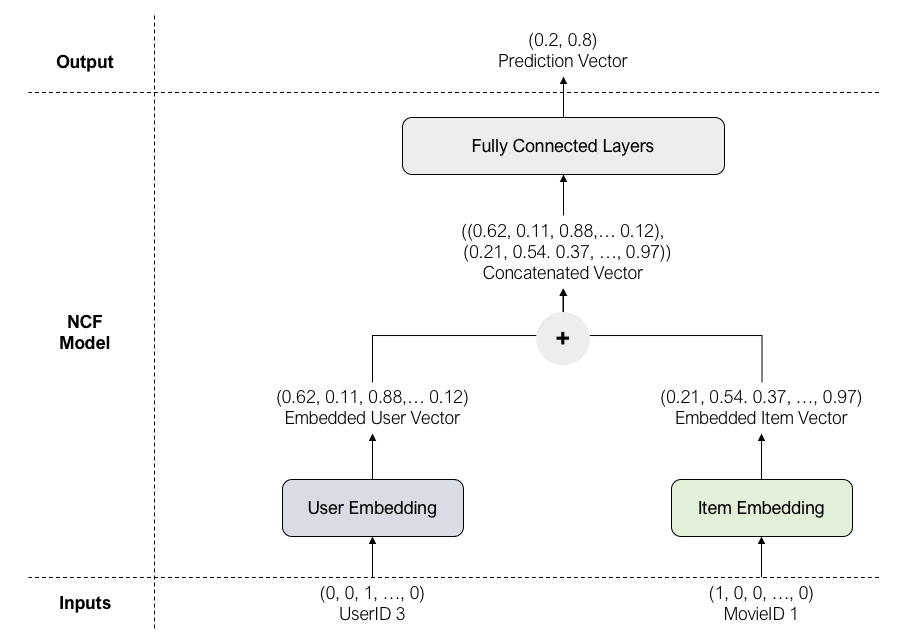
Inputs của NFC model là các vectors dạng One-hot Encoded của User và Item. Các vectors này được đưa qua các lớp Embeddings để sinh ra các Embedded vectors tương ứng. Embedded vectors sau đó được kết hợp lại với nhau trước khi đi qua một vài lớp Fully Connected, chuyển thành vector dự đoán (output vector). Hàm Sigmoid được áp dụng cho Ouput vector sinh ra xác suất của mỗi class: Positive và Negative. Như ví dụ trong sơ đồ kiến trúc NFC model thì xác suất mỗi class Positive : Negative tương ứng là 0.8:0.2. Từ đó có thể kết luận là User được dự đoán là có tương tác với Item đó vì 0.8 > 0.2.
Sử dụng Pytorch Lightning, ta định nghĩa NFC model như sau:
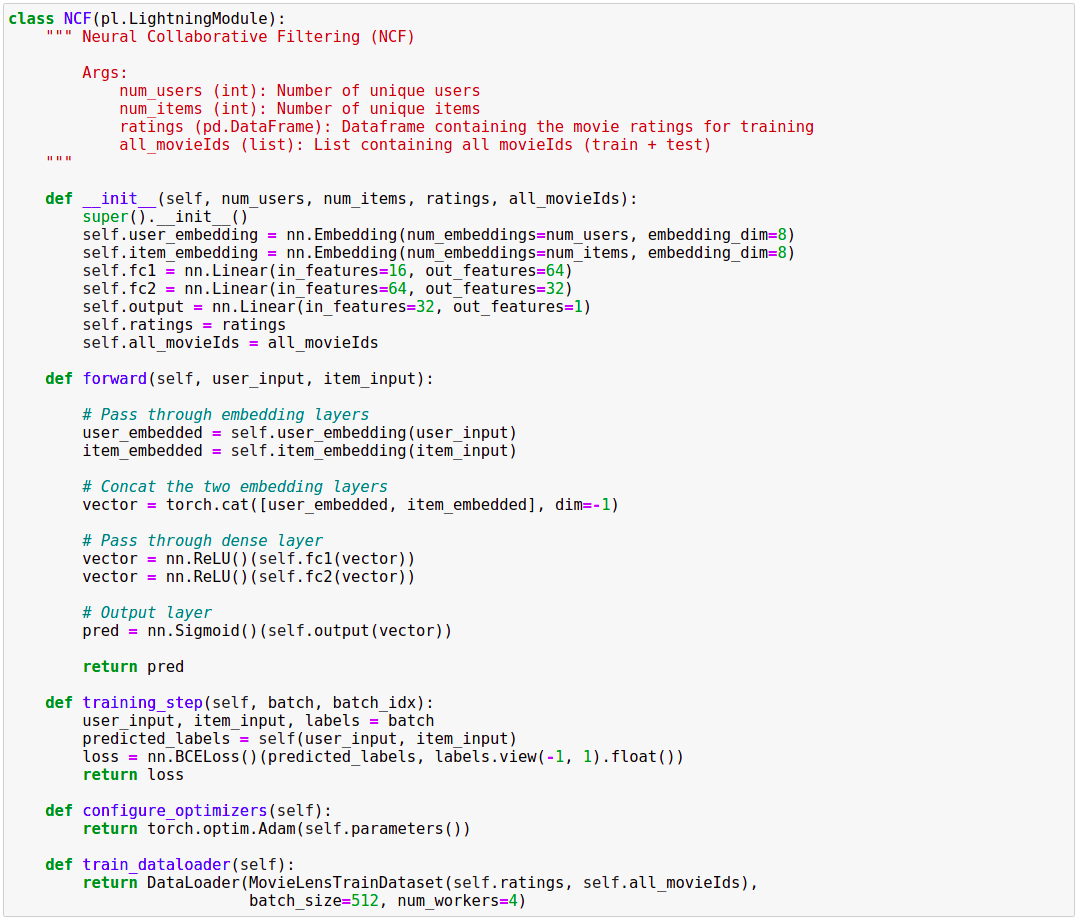
Pytorch Lightning là một dạng lightweight của Pytorch, nó đóng gói các hàm của Pytorch ở mức high-level, giúp đơn giản hóa code và tăng tốc độ xử lý. Chi tiết hơn vê Pytorch Lightning, bạn có thể tham khảo trong link mình để bên trên.
5. Huấn luyện Deep Learning model
NFC model được huấn luyện như sau:


Thời gian huấn luyện khá lâu, mình phải chờ gần một ngày mới hoàn thành.
6. Đánh giá Deep Learning model
Để đánh giá các RS model, chúng ta sẽ sử dụng metric Hit Ration @10 như đã đề cập trong bài trước.
Code thực hiện như sau:
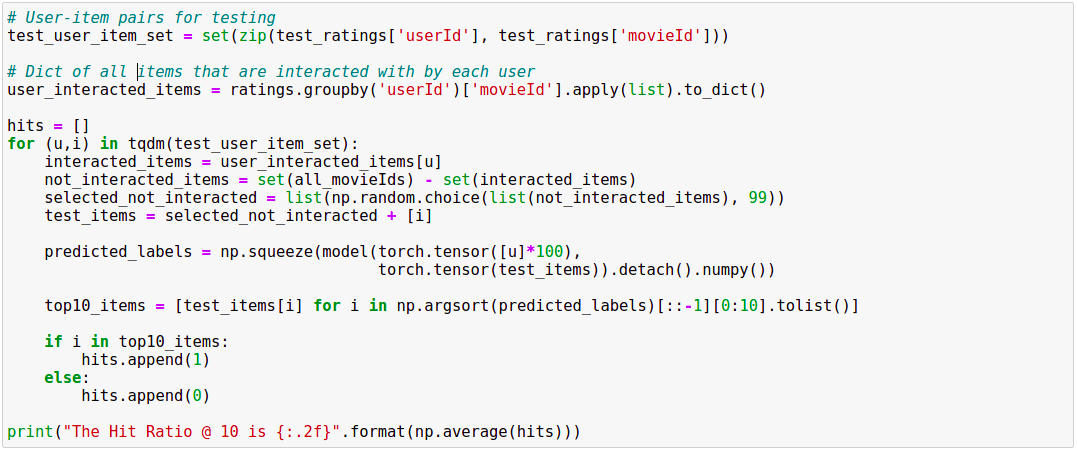
Kết quả cuối cùng:
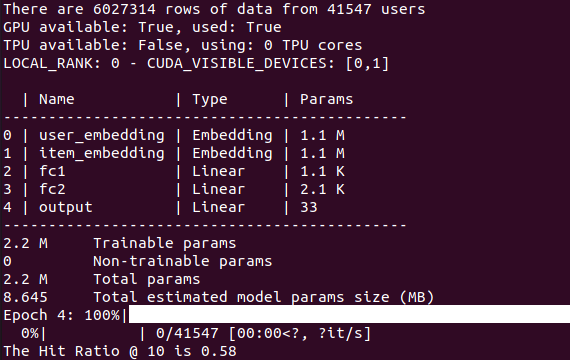
Hit Ration @10 mới chỉ đạt 0.58, vẫn còn khá khiêm tốn. Có lẽ model cần phải được huấn luyện thêm nhiều epochs nữa. Con số 0.58 có nghĩa là nếu đề xuất một Item nào đó cho 100 Users thì 58 người có tương tác với Item đó.
7. Kết luận
Như vậy là chúng ta đã kết thúc chuỗi bài viết về Recommender System tại đây. Hi vọng từ những điều mình chia sẻ sẽ giúp ích cho các bạn trong quá trình học tập và công tác của mình.
Toàn bộ code của bài này, các bạn có thể tham khảo tại đây.
Trong bài tiếp theo, chúng ta sẽ chuyển sang một chủ đề hoàn toàn mới, Data Preparation for Machine Learning. Mời các bạn đón đọc.
8. Tham khảo
[1] james Loy, “Deep Learning based Recommender Systems”, Available online: https://towardsdatascience.com/deep-learning-based-recommender-systems-3d120201db7e (Accessed on 10 Jul 2021).
[2] Abhijit Roy, “Introduction To Recommender Systems- 2: Deep Neural Network Based Recommendation Systems”, Available online: https://towardsdatascience.com/introduction-to-recommender-systems-2-deep-neural-network-based-recommendation-systems-4e4484e64746 (Accessed on 05 Jul 2021).