Thực hành xây dựng RS bằng phương pháp Content-Based Filtering

Đây là bài thứ 2 trong chuỗi bài viết về Recommender System. Trong bài này, chúng ta sẽ thực hành xây dựng một RS sử dụng phương pháp Content-Based Filtering.
1. Đặt vấn đề
Một website bán sách muốn tăng doanh số bán hàng. Họ muốn bạn - 1 Data Scientist giúp họ xây dựng một RS để đề xuất các cuốn sách cho người dùng mỗi khi họ ghé vào website của họ. Sau khi xem xét kỹ yêu cầu bài toán và dữ liệu hiện có, bạn quyết định xây dựng RS theo phương pháp Content-Based Filtering.
Sơ đồ các bước tiến hành sẽ như sau:
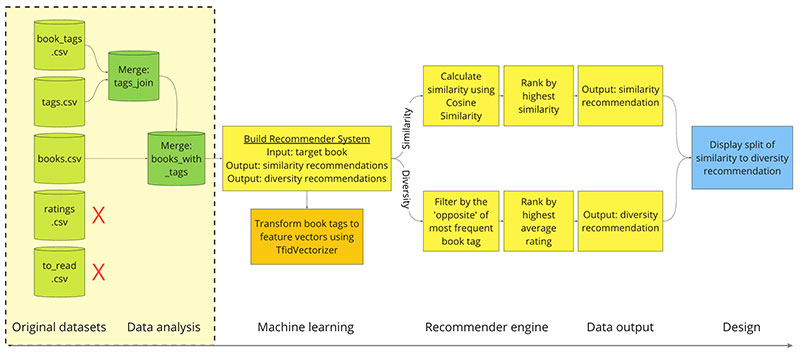
Ở đây, phần RS Engine sẽ bao gồm 2 nhiệm vụ:
- Nhiệm vụ 1: Sử dụng Cosine Similarity để tìm ra danh sách 10 cuốn sách có mức độ tương tự gần với cuốn sách mà ta đưa vào RS nhất.
- Nhiệm vụ 2: Sử dụng những hiểu biết về lĩnh vực sách để đưa ra gợi ý khi đưa vào RS một cuốn sách, làm cho kết quả mang tính đa dạng hơn.
2. Chuẩn bị dữ liệu
Download dữ liệu tại đây.
Thông tin về sách đựợc lưu trong các files: books.csv, book_tags.csv, tags.csv. Chúng ta sẽ khám phá từng file:
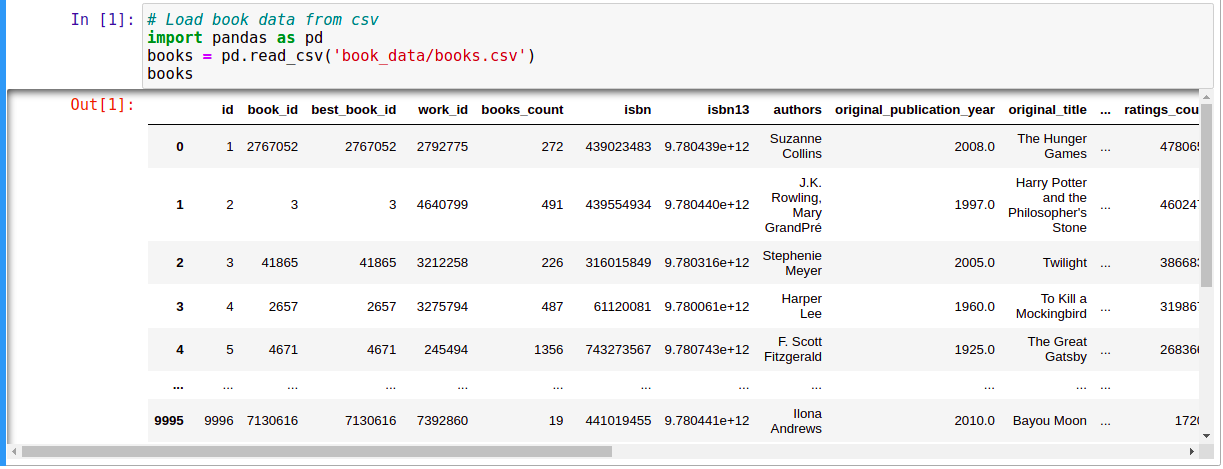

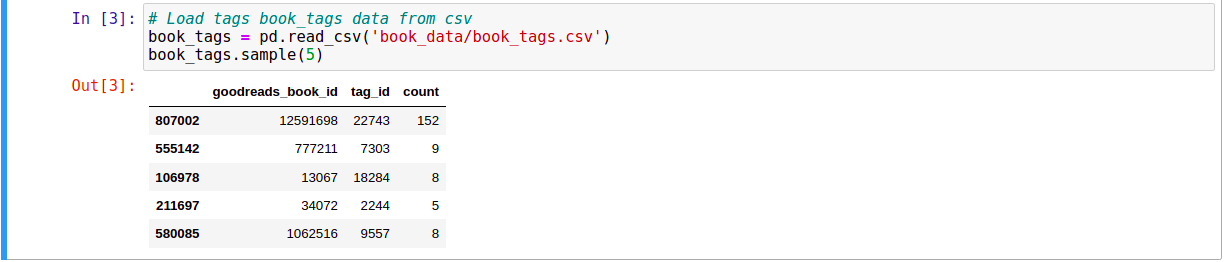

Ta thấy rằng có tổng cộng 10.000 cuốn sách, và trường book_tags của mỗi cuốn sách chứa đựng nhiều về cuốn sách đó. Vì thế, chúng ta sẽ sử dụng thông tin này đề xây dựng RS.
Vì các thông tin book_id, tag_id, tag_name, … nằm rải rác ở các file csv khác nhau nên ta sẽ tiến hành gom chúng lại với nhau.
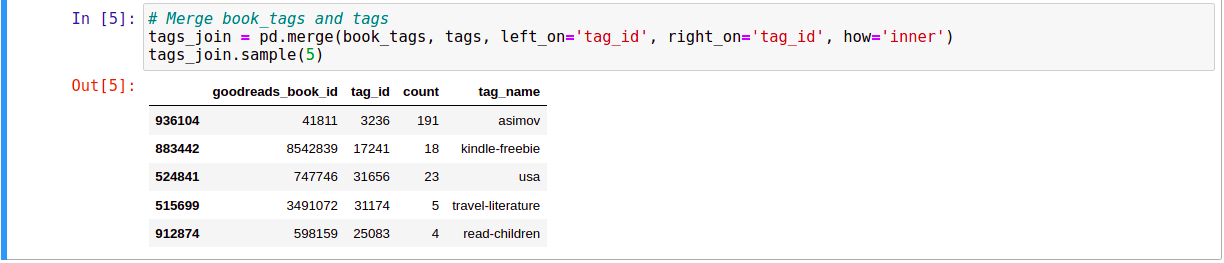
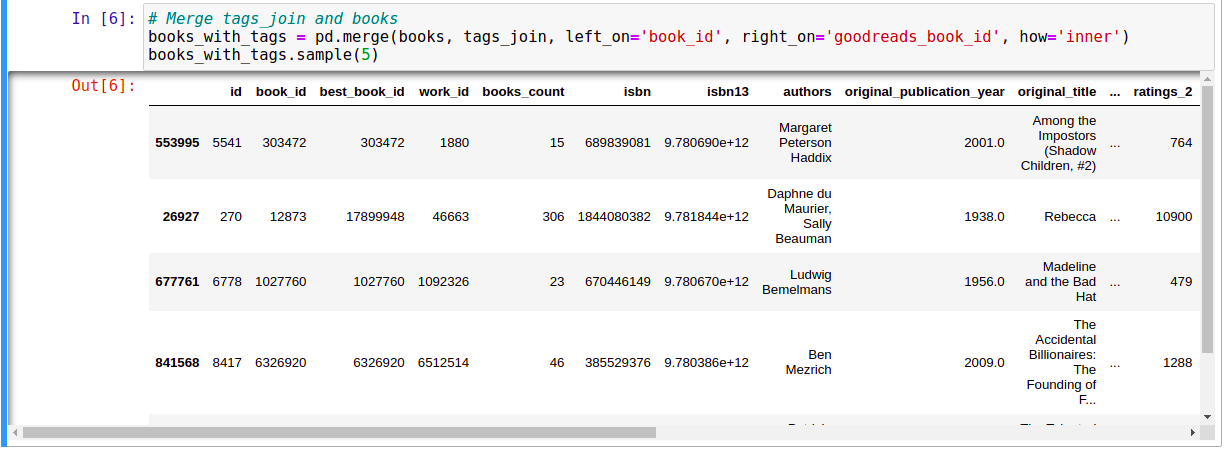

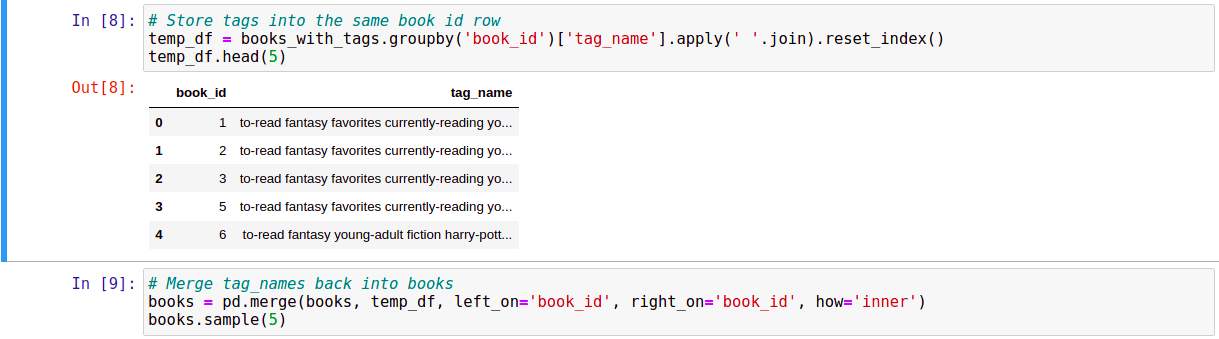
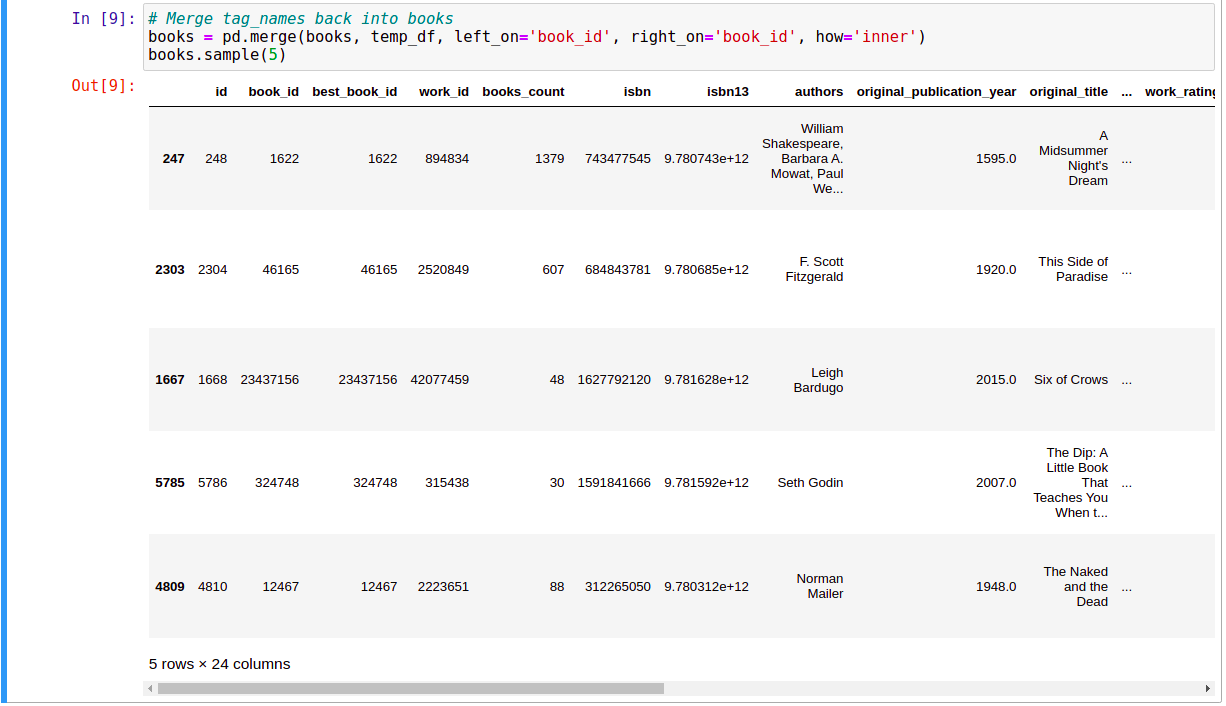
Đến đây, chúng ta đã có đầy đủ thông tin cần thiết về các cuốn sách trong một DataFrame là books.
3. Transform Data
Như đã phân tích ở trên, chúng ta sẽ sử dụng thông tin tag_name làm cơ sở cho việc tính toán mức độ tương tự giữa các cuốn sách.
Hãy xem thử, tag_name đang như thế nào?
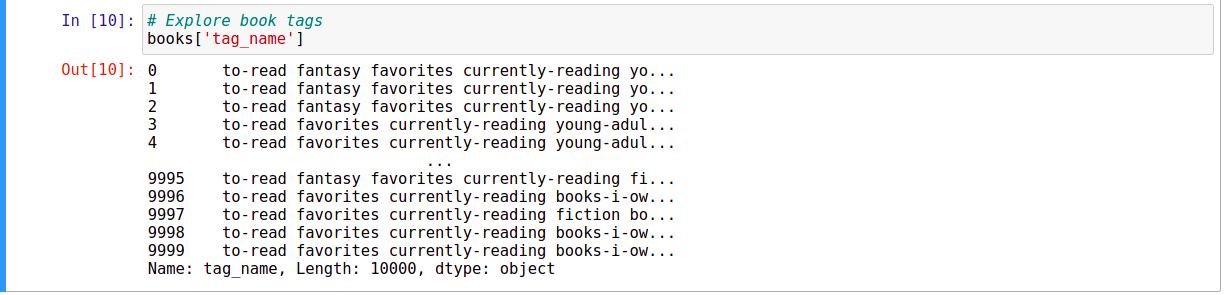
Chúng ta cần phải chuyển đổi các thông tin này từ dạng Text sang dạng Number để làm Input cho việc tính toán. Việc này được gọi là Word Embedding. Mỗi cuốn sách sẽ được chuyển đổi tương ứng thành một Vector, gọi là Vector Embedding. Có rất nhiều thuật toán giúp chúng ta thực hiện nhiệm vụ này: CountVectorizing, TF-IDF, Glove, Word2Vec, BERT, … Trong bài này, chúng ta sẽ sử dụng TF-IDF trong thư viện Scikit-learn như dưới đây:
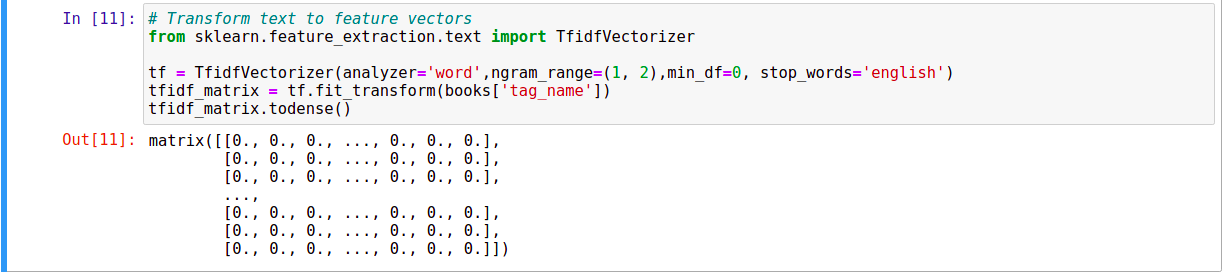
TFIDF (Term Frequency - Inverse Document Frequency) tính toán mức độ quan trọng của mỗi từ dưạ trên tần suất xuất hiện và mối liên hệ với các từ khác trong toàn bộ đoạn văn bản. Vector Embedding của mỗi cuốn sách là một hàng trong TF-IDF vector.
4. Xây dựng RS Engine
Như đã nói ở bên trên, sẽ có 2 nhiệm vụ trong bước này:
- Nhiệm vụ 1:
Chúng ta cần tính mức độ tương tự nhau giữa các Vector Embedding của các cuốn sách. Như đã giới thiệu ở bài trước, chúng ta có thể sử dụng Cosine Similarity hoặc Euclidean Distance. Mình sẽ chọn Cosine Similarity để thực hiện. Thư viện Scikit-learn đã hỗ trợ chúng ta việc này.
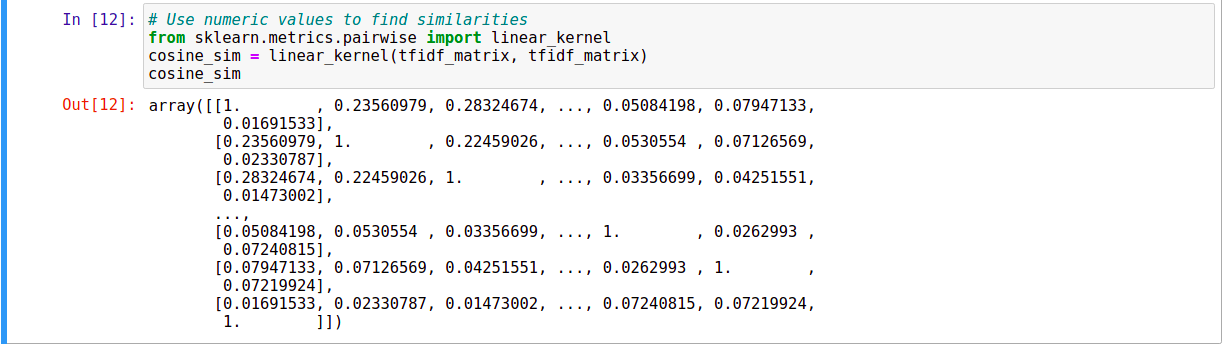
Nếu zoom to lên một phần của ma trân Cosine Similarity ta sẽ thấy như sau:
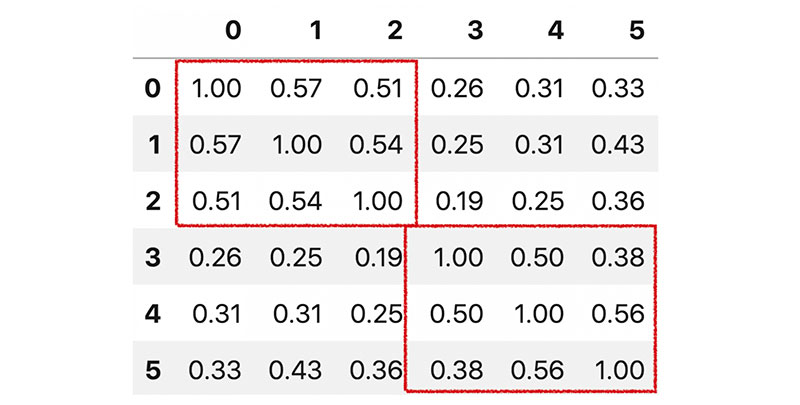
Giá trị tại điểm giao nhau giữa hàng và cột trong ma trận này chính là thể hiện mức độ tương tự nhau của 2 cuốn sách nằm trên hàng và cột đó.
Tiếp theo, chúng ta sẽ viết code để lấy ra được danh sách các cuốn sách được đề xuất khi đưa vào RS tên một cuốn sách:


Chúng ta sẽ kiểm tra luôn kết quả của nhiệm vụ 1. Ta đưa vào RS một cuốn sách có tên The Fellowship of the Ring (The Lord of the Rings, #1), kết quả nhận được như sau:

Chúng ta nhận đuọc một danh sách gồm 10 cuốn sách có mức độ tương tự lớn nhất với cuốn sách mà ta đưa vào cho RS. Mình cũng thử lên Amazon, thử chọn mua cuốn sách cùng tên thì thật thú vị là Amazon cũng gọi ý cho mình 10 cuốn sách gần giống như kết quả của RS mà ta vừa xây dựng. Chứng tỏ rằng RS của chúng ta hoạt động khá hiệu quả.
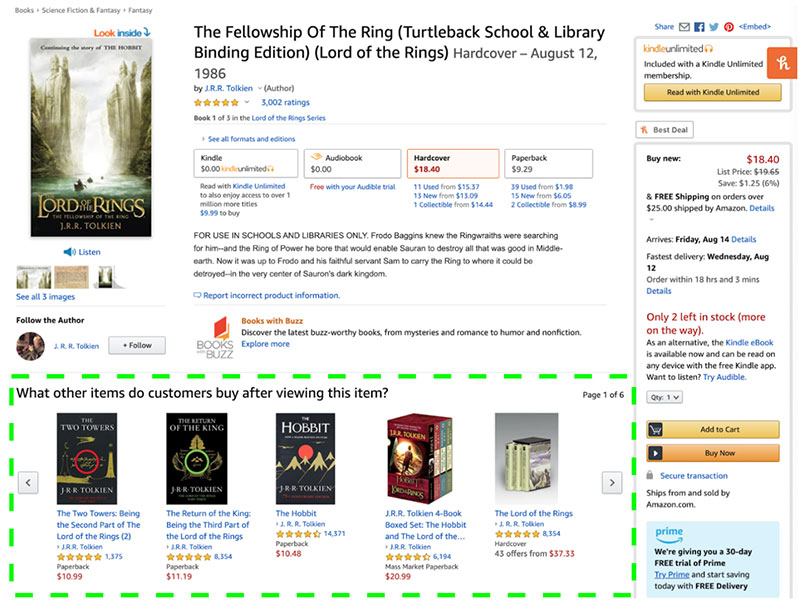
- Nhiệm vụ 2:
Nếu có hiểu biết về lĩnh vực sách, chúng ta sẽ thấy rằng những người mà quan tâm đến thể loại Fantasy cũng thường quan tâm đến một số thể loại khác như Science Fiction, Technology, Entrpreneurship, Biograpies, … Như vậy, để cho đa dạng hơn trong kết quả của RS, chúng ta có thể xử lý như sau: Lọc ra 10 cuốn sách có mức độ tương tự với cuốn sách đưa vào cao nhất để gơi ý, nhưng các cuốn sách đó nằm trên các Tags(Categories) khác nhau.
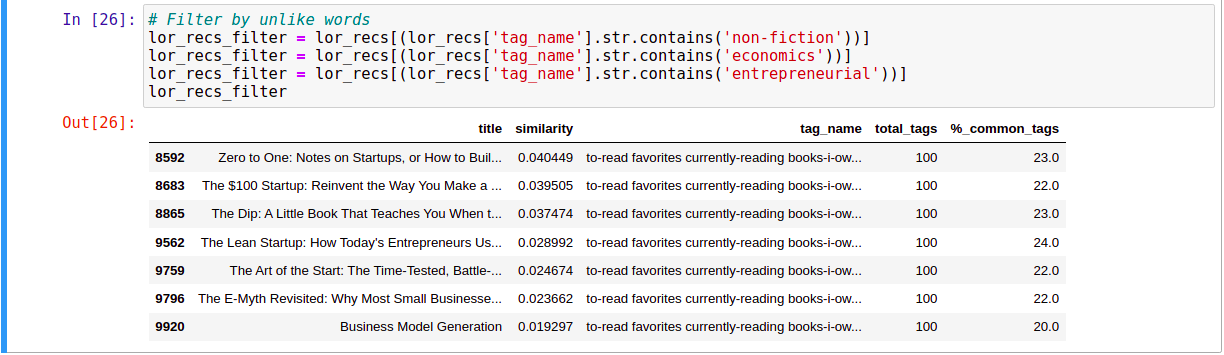
Giả sử chúng ta lấy ra các cuốn sách có Tag là Non-Fiction, Economics, Entrepreneurial từ danh sách các cuốn sách sắp xếp giảm dần theo mức độ tương tự với cuốn sách The Fellowship of the Ring (The Lord of the Rings, #1), code như sau:
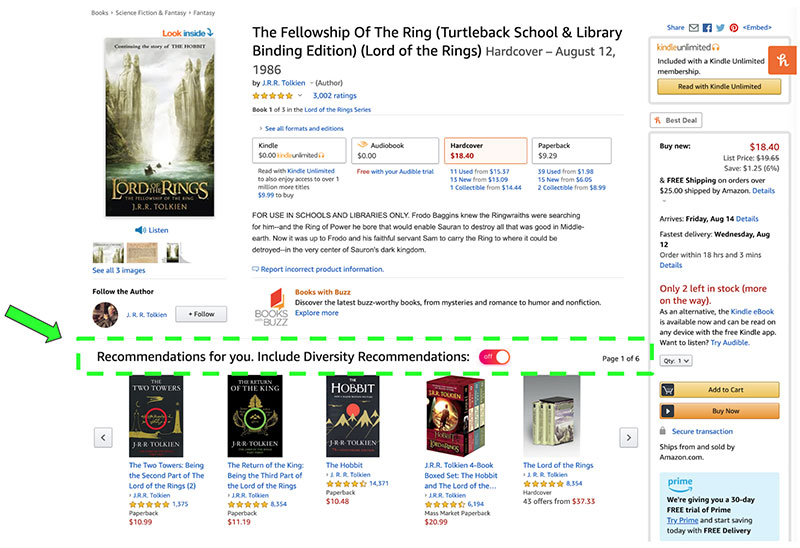
Amazon cũng thi thoảng đưa thêm tính chất Diversiry (đa dạng) này vào trong RS của họ, thậm chí còn cho phép User bật/tắt tính năng này. Ví dụ dưới đây là kết quả gợi ý nếu người dùng tắt tính năng Diversity:
Nếu User bật tính năng Diversity lên thì kết quả sẽ thay đổi như sau:
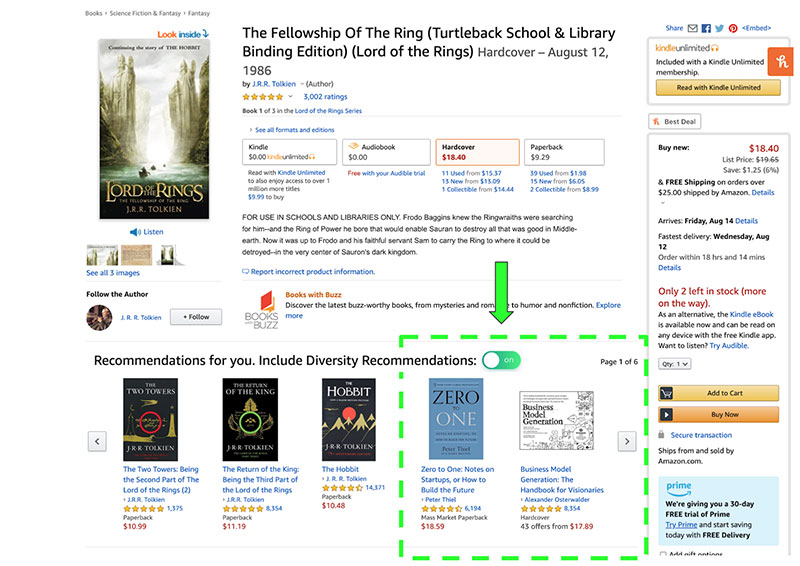
Trong 5 cuốn sách được gợi ý thì có 3 cuốn giữ nguyên như khi tắt Diversity, còn 2 cuốn mới xúât hiện, khác Category. Đó chính là kết quả của Diversity.
5. Kết luận
Như vậy là chúng ta đã cùng nhau thực hành code một RS theo phương pháp Content-Based Filtering, sử dụng bộ dataset về sách. Toàn bộ code của bài này, các bạn có thể tham khảo tại đây.
Trong bài tiếp theo, chúng ta sẽ tìm hiểu cách xây dựng RS bằng phương pháp sử dụng Deep Learning. Mời các bạn đón đọc.
6. Tham khảo
[1] Parul Pandey, “The Remarkable World of Recommender Systems”, Available online: https://www.topbots.com/diversity-through-recommendation-systems/ (Accessed on 05 Jul 2021).
[2] James Loy, “Deep Learning based Recommender Systems”, Available online: https://towardsdatascience.com/deep-learning-based-recommender-systems-3d120201db7e (Accessed on 05 Jul 2021).