Giới thiệu các phương pháp truyền thống xây dựng Recommender System

Chúng ta sẽ chuyển sang tìm hiểu một chủ đề mới, đó là các hệ thống khuyến nghị - Recommender System (RS).
Ngày nay, RS rất phổ biến trong cuộc sống của chúng ta. Khi xem Youtube, lướt Facebook, mua hàng trên Amazon hay Tiki, xem phim trên Netflix, chúng ta đều được đưa ra các gợi ý về những thứ mà chúng ta có thể quan tâm… Có thể nói, RS là ứng dụng quan trọng nhất của AI vào lĩnh vực giải trí và Maketing.
Trong chuỗi 3 bài tiếp theo ngay sau đây, chúng ta sẽ cùng tìm hiểu kỹ càng hơn về các thuật toán mà RS sử dụng, đồng thời sẽ thực hành một số thuật toán đó. Các bài viết bao gồm:
- Bài 1: Giới thiệu các phương pháp truyền thống xây dựng Recommender System
- bài 2: Xây dựng Recommender System bằng phương pháp Content-Based Filtering
- Bài 3: Xây dựng Recommender System sử dụng Deep Learning
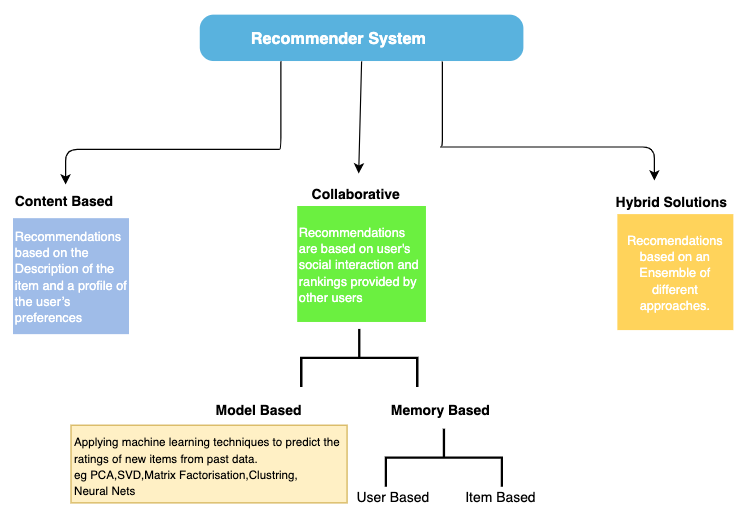
1. Phân loại thông tin sử dụng trong RS
Trong RS, có 2 đối tượng quan trọng nhất là khách hàng (Users) và sản phẩm (Items). Thông tin về 2 đối tượng này được sử dụng làm Input Data để tạo nên các RS. Dựa vào tính chất của chúng mà ta có thể phân loại như sau:
- Explicit Information: Là những thông tin được thể hiện một các rõ ràng, tường mình. Đó có thể là các thông tin về sự tương tác giữa Users-Items như hành vi click và nút Like/Dislike hoặc cho điểm (ratting) Items. Hoặc thông tin về bản thân Users/Items (User Profile - Item Profile).
- Implicit Information: Ngược lại với Explicit Information, đây là các thông tin mà không được thể hiện một các cụ thể, rõ ràng. Đó là khi User truy cập, tìm kiếm, bình luận, … và một Item cụ thể. Từ đó, hệ thống sẽ ghi nhận rằng User đang quan tâm đến Item đó.
2. Các phương pháp RS truyền thống
Hai phương pháp RS phổ biến mà có thể bạn đã biết là: Content-Based Filtering và Collaborative Filtering. Ngoài ra, có thể kết hợp 2 phương pháp này lại, tạo ra một phương pháp mới gọi là Hybrid Filtering.
2.1 Phương pháp Content-Based Filtering
Đây là phương pháp đơn giản nhất, hầu như chỉ dựa trên thông tin User Profile và Item Profile. Ý tưởng cơ bản của nó là nếu một User A đã từng quan tâm đến một Item X trong quá khứ thì khả năng cao là A cũng sẽ quan tâm đến Item Y nếu Y tương tự X.
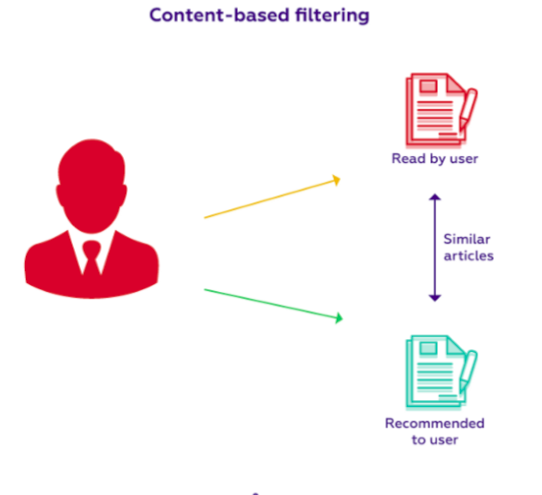
User Profile được xây dựng dần dần theo thời gian sử dụng Explicit Information.
Một số Metrics đo độ Tương tự (Similarity) giữa 2 Items
Để đánh giá mức độ Similarity giữa 2 Items, chúng ta có thể sử dụng một trong các Metrics sau:
- Cosin Similarity:
Công thức tính Cosin Similarity giữa 2 vector A và B như sau:
$sim(A,B) = cos(\theta) = \frac{A.B}{\begin{Vmatrix}A\end{Vmatrix} \begin{Vmatrix}B\end{Vmatrix}}$
Trong đó, $A$ và $B$ là 2 Profile Vector của 2 Items, $\theta$ là góc giữa chúng.
Cosin Similarity có giá trị nằm trong khoảng [-1,1]. Càng gần 1 thì 2 Items càng giống nhau. Chúng ta có thể chọn n-Items từ danh sách giảm dần mức độ Similarity hoặc lấy các Items mà mức độ Similarity lớn hơn giá trị ngưỡng.
- Euclidean Distance:
Công thức tính Euclidean Distance giữa 2 vector $A(x_1, x_2, …, x_n)$ và $B(y_1, y_2, …, y_n)$ như sau:
$ED(A,B) = \sqrt{(x_1 - y_1)^2 + (x_2 - y_2)^2 + ... + (x_n - y_n)^2}$
Euclidean Distance có giá trị > 0 và càng nhỏ thì 2 vectors càng giống nhau. So với Cosin Similarity, việc tính toán Euclidean Distance khá chậm, đặc biệt là trong trường hợp số chiều của các vectors lớn.
2.2 Phương pháp Collaborative Filtering
Phương pháp này sử dụng mối quan hệ giữa User-User, Item-Item và User-Item để đưa ra các đề xuất.
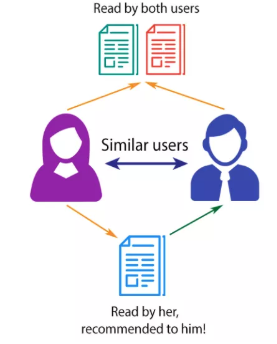
Collaborative Filtering được chia thành 2 phương pháp:
-
Memory-based: Phương pháp này còn được gọi là thuật toán Collaborative Filtering dựa trên vùng lân cận. Các vùng lân cận này có thể được xác định theo một trong hai cách:
- User-based Collaborative Filtering: Ý tưởng là phân chia các Users tương tự nhau vào chung một nhóm. Nếu một User bất kỳ trong nhóm thích một Item nào đó thì Item đó sẽ được đề xuất cho toàn bộ các Users khác trong nhóm đó.
- Item-Item Collaborative Filtering: Ý tưởng là phân chia Items tương tự nhau vào chung một nhóm. Nếu một User thích bất kỳ một Item nào trong nhóm đó thì tất cả các Item còn lại trong cùng nhóm sẽ được đề xuất cho User đó. Nghe qua ý tưởng thì có vẻ Item-Item Collaborative Filtering rất giống với ý tưởng của phương pháp Content-Based Filtering. Và quả thực đúng là như vậy. Tuy nhiên, sự khác nhau ở đây là cách thức để tìm ra các Items tương tự nhau. Đối với Content-Based Filtering, ta sử dụng chính đặc điểm (Profile) của các Items để tính toán mức độ Similarity giữa chúng. Còn đối với Item-Item Collaborative Filtering, độ Similarity được tính dựa trên Utility Matrix mà sẽ được đề cập dưới đây.
-
Model-based: Phương pháp này sử dụng các thuật toán ML như PCA, Clustering, SVD, Matrix Factorisation, … để dự đoán các giá trị Rating còn thiếu của User đối với Item.
Tất cả các cách/phương pháp của Collaborative Filtering đề phải sử dụng Utility Matrix, được tạo thành từ bảng dữ liệu User-Item Ratings như dưới đây.
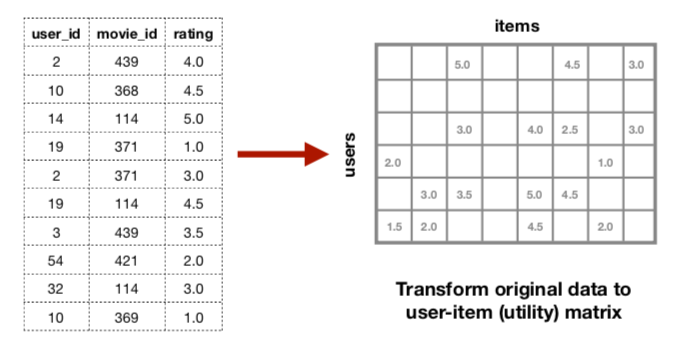
Bảng User-Item Ratings chỉ chứa các Users và Items mà có sự tương tác với nhau, còn Utility Matrix thì chứa tất các các Users, Items trong hệ thống. Mỗi Cell trong Utility Matrix thể hiện giá trị Rating của User và Item tương ứng. Vấn đề lớn nhất của Collaborative Filtering là số lượng Rating thường nhỏ hơn rất nhiều so với số lượng User và Item. Điều này dẫn đến Utility Matrix bị thiếu rất nhiều gíá trị trong các Cells. Vì lẽ đó mà Utility Matrix còn được gọi là ma trận thưa (Sparsity Matrix).
Ta có công thức tính độ thưa như sau:
$Sparsity = \frac{No of Ratings}{No of Cells}$
Nếu giá trị của Sparsity > 0.5 thì chúng ta không nên sử dụng Collaborative Filtering mà nên xem xét sử dụng các phương pháp khác.
Chi tiết hơn về 2 phương pháp Content-Based Filtering và Collaborative Filtering, các bạn có thể đọc thêm tại đây và đây.
2.3 Phương pháp Hybrid
Phương pháp này có tên gọi khác là Ensemble, tức là kết hợp 2 phương pháp Content-Based Filtering và Collaborative Filtering.
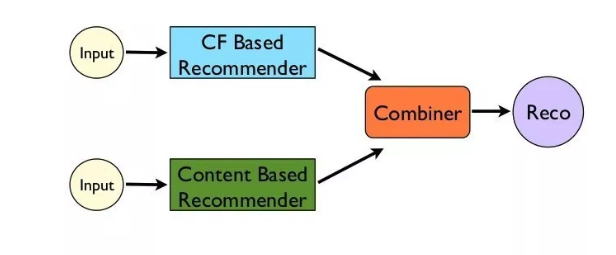
Content-Based Filtering và Collaborative Filtering, mỗi phương pháp đều có ưu/nhược điểm riêng của mỗi loại. Và trong một số trường hợp, việc kết hợp chúng lại sẽ mang đến hiệu quả tốt hơn. Netflix chính là một ví dụ sử dụng phương pháp Hybrid này.
3. Đánh giá Recommender System
Các ML model thường sử dụng Accuracy metric (đối với bài toán Classification) và RMSE metric (đối với bài toán Regression) để đánh giá model. Tuy nhiên, đối với RS model, các metrics này đều tỏ ra không hiệu quả.
Để đưa ra được một metric phù hợp hơn, đầu tiên chúng ta hãy xem thử Netflix và Amazon đang đề xuất cho User những gì?

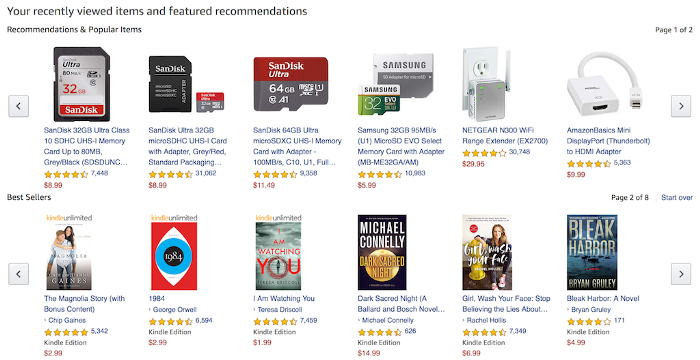
Dễ nhận thấy, điểm mấu chốt ở đây là User không cần tương tác với tất cả các Items trong danh sách đề xuất mà chỉ cần tương tác với ít nhất một Item trong số đó. Và khi điều này xảy ra, tức là RS model đã làm việc đúng (hitted).
Do vậy, các xây dựng metric đánh giá RS model sẽ như sau:
- Đối với mỗi User, chọn ngẫu nhiên 99 Items mà User đó không tương tác.
- Kết hợp 99 Items đó với một Test Item (Item mà User đã tương tác). Ta có 100 Items.
- Chạy RS model trên 100 Items đó rồi sắp xếp theo thứ tự giảm dần xác suất mà User đó có tương tác với mỗi Item.
- Lựa chọn 10 Items có xác suất lớn nhất trong danh sách đã sắp xếp. Nếu Test Item nằm trong số 10 Items đã chọn thì ta nói RS model đã làm việc đúng (tính là một Hit).
- Lặp lại quá trình trên cho toàn bộ Users. Ta định nghĩa giá trị Hit Ratio @10 như sau:
$Hit Ration @10= \frac{No Of Hits}{No Of Users}$
Hit Ration @10 chính là metric đánh giá RS model của chúng ta.
4. Kết luận
Như vậy là chúng ta đã kết thúc bài đầu tiên trong chuỗi 4 bài tìm hiểu về Recommender System. Qua bài này, chúng ta đã hiểu được phần nào rõ hơn về bài toán RS, cũng như một số phương pháp truyền thống để xây dựng RS.
Trong bài tiếp theo, chúng ta sẽ thực hành xây dựng một RS bằng phương pháp Content-Based Filtering. Mời các bạn đón đọc.
5. Tham khảo
[1] Parul Pandey, “The Remarkable World of Recommender Systems”, Available online: https://www.topbots.com/overview-of-recommender-systems/ (Accessed on 25 Jun 2021).
[2] James Loy, “Deep Learning based Recommender Systems”, Available online: https://towardsdatascience.com/deep-learning-based-recommender-systems-3d120201db7e (Accessed on 25 Jun 2021).