Xử lý dữ liệu Audio trong Python. Tìm hiểu về Mel Spectrogram
Đây là bài thứ 2 trong chuỗi 5 bài về Audio Deep Learning. Trong bài này, chúng ta sẽ tìm hiểu cách xử lý dữ liệu Audio bằng các thư viện của Python. Chúng ta cũng tìm hiểu về Mel Spectrogram, một dạng biến đổi từ Spectrogram giúp Deep Learning model học tốt hơn.
1. Audio File Formats and Python Libraries
Bắt đầu từ âm thanh chúng ta nghe được trong thực tế ở dạng tín hiệu tương tự, nó được số hóa và lưu lại theo các định dạng khác nhau: .mp3, .wav, .wma, .aac, .flac, …
Python có một số thư viện xử lý dữ liệu Audio rất tốt. Nổi bật nhất là 2 thư viện Librosa và Scipy. Nếu bạn sử dụng Pytorch thì có thư viện torchaudio, sử dụng Tensorflow thì có tư viện tf.audio. Cả 2 đều khá tiện dụng, được xây dựng để xử lý riêng cho dữ liệu Audio.
Thử đọc một file Audio bằng thư viện librosa:
# Load the audio file with librosa
import librosa
AUDIO_FILE = './7061-6-0-0.wav'
samples, sample_rate = librosa.load(AUDIO_FILE, sr=None)
Tương tự với thư viện scipy:
# Load the audio file with scipy
from scipy.io import wavfile
sample_rate, samples = wavfile.read(AUDIO_FILE)
Kết quả đọc Audio file được thể hiện trên đồ thị như sau:
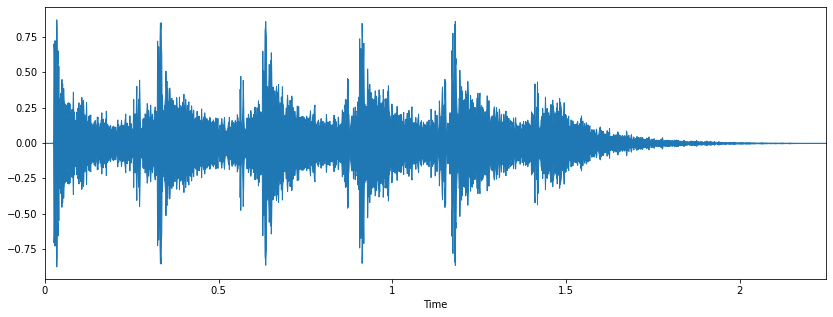
Nếu sử dụng Jupyter Notebook, chúng ta có thể nghe được file Audio đó:
from IPython.display import Audio
Audio(AUDIO_FILE)

2. Audio Signal Data
Như chúng ta đã biết từ bài trước đó, Audio Data có được bằng cách lấy mẫu từ Sound Analog Signal theo một chu kỳ thời gian và đo đặc giá trị của biên độ tại mỗi thời điểm lấy mẫu đó. Audio Data được lưu lại thành file theo một trong các định dạng nén (.mp3, .wav, …). Khi đọc lên bằng các thư viện xử lý, nó được giải nén và chuyển thành một Numpy Array. Mảng dữ liệu này là giống nhau cho dù Audio Data được lưu dưới bất kỳ định dạng nào.
Trong bộ nhớ, Audio có thể coi là một chuỗi các giá trị của biên độ theo thời gian. Ví dụ, nếu tần số lấy mẫu là 16800Hz thì cứ 1s Audio sẽ có 16800 giá trị biên độ.
print ('Example shape ', samples.shape, 'Sample rate ', sample_rate, 'Data type', type(samples))
print (samples[22400:22420])

Khoảng giá trị của biên độ được quy định bởi thông số bit-length. Ví dụ, bit-length bằng 16 có nghĩa là biên độ có thể có giá trị trong khoảng từ 0 đến $2^{16}-1$. Bit-length càng lớn thì chất lượng của Audio càng tốt.
3. Spectrograms
Dữ liệu Audio hiếm khi được đưa trực tiếp vào các Deep Learning model để huấn luyện. Thay vào đó, chúng thường được chuyển sang dạng Spectrogram như trong bài trước chúng ta đã đề cập.
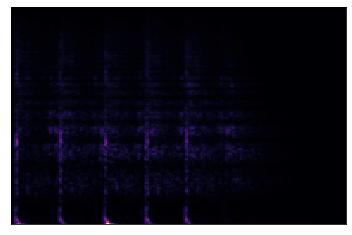
Ta sẽ vẽ Spectrogram lên đồ thị:
sgram = librosa.stft(samples)
librosa.display.specshow(sgram)

Đây là dạng nguyên thủy của Spectrogram. Rõ ràng, chúng ta không thể thấy rõ được các thông tin về tần số, biên độ mà Spectrogram thể hiện. Điều này được giải thích là do khả năng nhận thức âm thanh của con người. Hầu hết những âm thanh mà chúng ta nghe được đều tập trung xung quanh một dải tần số và biên độ khá hẹp.
4. Mel Spectrogram
Để giải quyết vấn đề này, Spectrogram được chuyển sang một dạng mới, gọi là Mel Spectrogram mà ở đó:
- Tần số được thay thế bằng giá trị Logarithmic của nó, gọi là Mel Scale.
- Biên độ được thay thế bằng giá trị Logarithmic của nó, gọi là Decibel Scale.
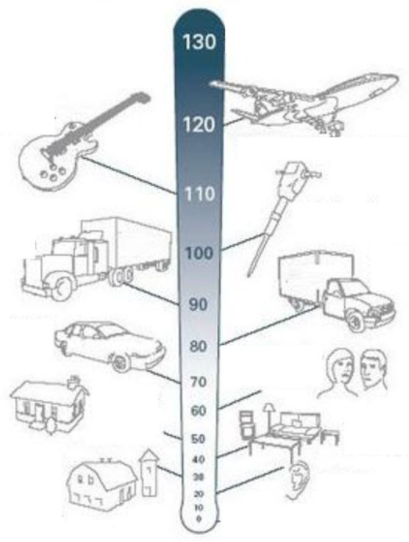
Hình dưới đây cho ta biết các giá trị Decibel Scale của một số loại âm thanh khác nhau.
Chúng ta thử vẽ lại Spectrogram ở trên, thay thế tần số bằng Mel Scale:
# use the mel-scale instead of raw frequency
sgram_mag, _ = librosa.magphase(sgram)
mel_scale_sgram = librosa.feature.melspectrogram(S=sgram_mag, sr=sample_rate)
librosa.display.specshow(mel_scale_sgram)
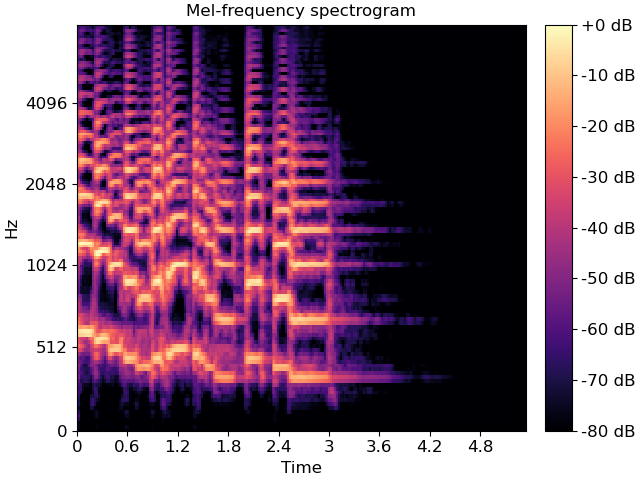
Ta thấy thông tin đã xuất hiện rõ ràng hơn. Tiếp tục sử dụng Decibel Scale thay cho biên độ để tạo thành Mel Spectrogram:
# use the decibel scale to get the final Mel Spectrogram
mel_sgram = librosa.amplitude_to_db(mel_scale_sgram, ref=np.min)
librosa.display.specshow(mel_sgram, sr=sample_rate, x_axis='time', y_axis='mel')
plt.colorbar(format='%+2.0f dB')
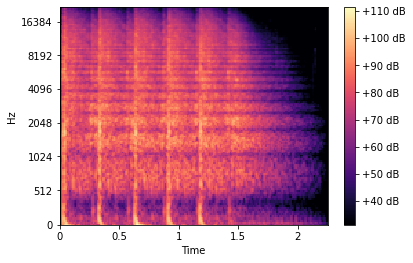
Đến đây thì thông tin của Audio đã được thể hiện rất rõ ràng trên hình ảnh của Mel Spectrogram.
5. Kết luận
Bài thứ hai trong chuỗi các bài viết về Audio Deep Learning này, chúng ta học cách sử dụng một số thư viện của Python để xử lý Audio Data. Chúng ta cũng tìm hiểu về Mel Spectrogram và cách tạo ra nó. Sử dụng Mel Spectrogram thay thế cho Spectrogram thông thường sẽ mang lại hiệu quả hơn khi đưa vào các Deep Learning model để huấn luyện.
Source code bài này mình để ở đây.
Ở bài tiếp theo, chúng ta sẽ tìm hiểu một số kỹ thuật nâng cao, cải thiện Audio Data để giúp Deep Learning models học tốt hơn. Mời các bạn đón đọc.
6. Tham khảo
[1] Ketan Doshi, “Audio Deep Learning Made Simple (Part 2): Why Mel Spectrograms perform better”, Available online: https://towardsdatascience.com/audio-deep-learning-made-simple-part-2-why-mel-spectrograms-perform-better-aad889a93505 (Accessed on 25 May 2021).
[2] Wikipedia, “Mel-frequency cepstrum”, Available online: https://en.wikipedia.org/wiki/Mel-frequency_cepstrum (Accessed on 25 May 2021).