Tóm tắt các thuật toán Object Detection
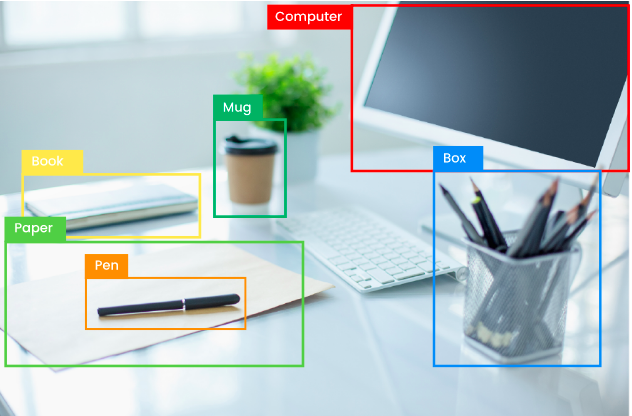
Object Detection là một trong những bài toán rất phổ biến trong lĩnh vực Computer Vision. Ngày nay, với sự giúp đỡ của các thuật toán Deep Learning, bài toán này đã được giải quyết khá tốt. Các thuật toán nối tiếng có thể kể ra ở đây là: R-CNN, Fast R-CNN, Faster R-CNN, YOLOv1, YOLOv2, YOLOv3, YOLOv4, YOLOv5, SSD, EfficientDet. Trong bài này, hãy cùng nhau tóm tắt lại các thuật toán Deep Learning đó nhé!
1. Các thuật toán Object Detection
1.1 R-CNN
Đây có thể coi là thuật toán Deep Learning đầu tiên giải quyết bài toán Computer Vision. Trước đó, cũng có một vài thuật toán khác (không phải Deep Learning), như Exhaustive Search, … Nhược điểm chung của các thuật toán này là chúng yêu cầu tài nguyên tính toán rất lớn, thời gian xử lý cũng rất lâu.
Để giải quyết những yếu điểm đó, R-CNN đề xuất sử dụng phương pháp Selective Search để trích xuất thông tin từ khoảng 2000 khu vực trên bức ảnh (mỗi khu vực được gọi là Region Proposal). Các thông tin được trích xuất sau đó sẽ được đưa qua một mạng CNN để xác định vị trí cũng như phân loại đối tượng.
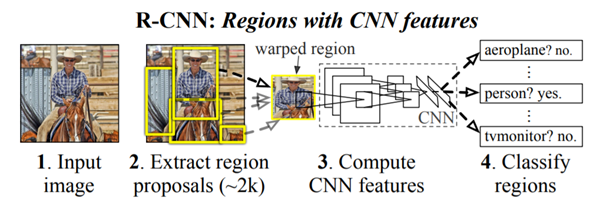
Mặc dù vậy, R-CNN vẫn cần trung bình khoảng 50s để xử lý một bức ảnh. Nếu ảnh có nhiều đối tượng thì thời gian xử lý còn lâu hơn nữa.
1.2 Fast R-CNN
Fast R-CNN ra đời để giải quyết hạn chế của R-CNN. Thay vì chia bức ảnh thành các Region Proposals và đưa chúng vào mạng CNN như R-CNN, Fast R-CNN đưa toàn bộ bức ảnh vào mạng CNN một lần để sinh ra Feature Map. Từ Feature Map này, các Region Proposals mới được nhận diện và đưa vào mạng FC. Cuối cùng, Softmax được sử dụng để dự đoán nhãn cho mỗi đối tượng và tính toán tọa độ các Bouding Boxs của chúng.
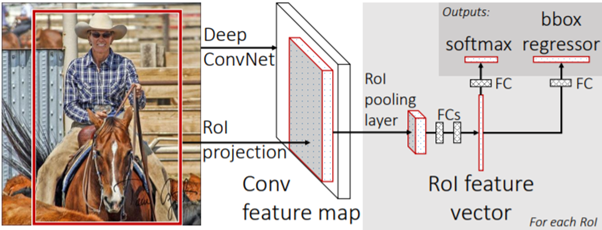
Fast R-CNN nhanh hơn R-CNN vì mạng CNN chỉ hoạt động một lần trên mỗi bức ảnh.
1.3 Faster R-CNN
Tương tự như Fast R-CNN, toàn bộ bức ảnh cũng được đi qua mạng CNN đẻ sinh ra Feature Map. Điểm khác ở đây là Faster R-CNN sử dụng một Region Proposal Network (RPN) thay vì Selective Search để sinh ra các Region Proposals. Tiếp đó, ROI Pooling nhận đầu vào là các Region Proposals đó để sinh ra nhãn dự đoán và tọa độ của Bounding Box cho mỗi đối tượng trong ảnh.

So sánh về mặt thời gian xử lý giữa 3 thuật toán trong hộ R-CNN, có sự giảm dần từ R-CNN -> Fast R-CNN -> Faster R-CNN.

1.4 YOLO - You Look Only Once
Các thuật toán trong họ R-CNN có thể được phân loại là nhóm Two Stages Detector, bởi vì cách làm việc của chúng bao gồm 2 bước (2 stages). Đầu tiên, chúng lựa chọn ROI (Region of Interest) trong bức ảnh. Sau đó, chúng phân loại các ROI đó sử dụng mạng CNN. Đó chính là nguyên nhân làm cho tốc độ thực thi của những thuật toán đó tương đối chậm.
YOLO là một thuật toán Single Stage Detecto (Single Shot Detector), nghĩa là chúng sẽ dự đóan nhãn và vị trí của đối tượng trong toàn bộ bức ảnh chỉ với một lần chạy thuật toán duy nhất. Và tất nhiên, cách làm việc này giúp cho thời gian xử lý của YOLO rất nhanh, phù hợp với các ứng dụng cần chạy Realtime.
Cách làm viêc của YOLO có thể tóm tắt như sau:
- Chia bức ảnh thành các Cells. Ví dụ: 19x19, 13x13, …
- Mỗi Cell chịu trách nhiệm dự đoán ra b Bounding Box. b = 3, 5, 7, …
- Ouput của việc dự đoán bao gồm:
- Tọa độ trung tâm của Bounding Box ($b_x, b_y$)
- Chiều rộng của Bounding Box ($b_w$)
- Chiều cao của Bounding Box ($b_h$)
- Nhãn của đối tượng (nếu có) trong Bounding Box (c)
- Xác suất có đối tượng trong Bounding Box ($p_c$)
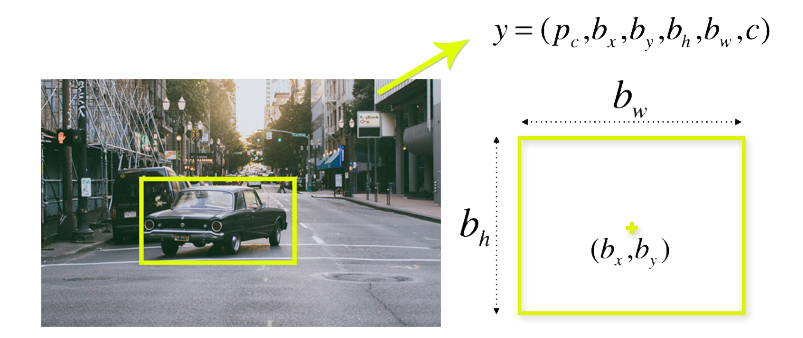
Hầu hết các Cell và Bounding Box không chứa đối tượng. Quy định một giá trị ngưỡng cho $p_c$ để loại bỏ bớt những Bounding Box này. Cách này gọi là NMS (Non-Max Suppression).

Darknet github phổ biến nhất của YOLO. Bạn có thể sử dụng nó cho các dự án của mình.
Tiếp sau thành công của YOLOv1, các phiên bản tiếp theo YOLOv2, YOLOv3, YOLOv4, YOLOv5 lần lượt ra đời, phiên bản sau kế thừa ưu điểm và hạn chế nhược điểm của phiên bản trước đó.
-
YOLOv1:
- 24 Conv layers, 2 FC layers -> tổng cộng có 26 layers.
- Nhược điểm chính là khả năng phát hiện những đối tượng kích thước nhỏ rất kém.
- Chi tiết xem tại đây
-
YOLOv2:
- Thêm BN layers -> tổng cộng có 30 layers.
- Có thêm 3 Anchor Boxes.
- Không có FC layers.
- Kích thước của Training Image được Scale trong khoảng 320-608.
- Mỗi đối tượng có thể có nhiều nhãn.
- Vẫn gặp khó khăn khi phát hiện những đối tượng có kích thước nhỏ.
- Chi tiết xem tại đây
-
YOLOv3:
- Tổng cộng 106 layers.
- Thay đối cách tính Loss Function.
- Sử dụng 9 Anchor Boxes.
- Phát hiện đối tượng kích thước nhỏ khá tốt.
- Chi tiết xem tại đây
-
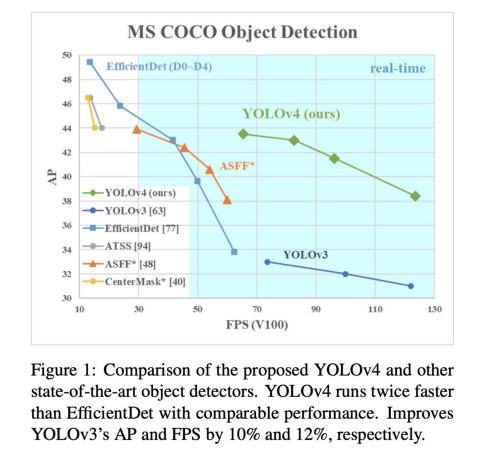
YOLOv4:
- Sử dụng CSPDARKNET53 model làm Backbone.
- Neck — Spatial pyramid pooling and Path Aggregation Network
- Head — Class subnet and Box subnet, as well as in YOLOv3
- Hỗ trợ rất nhiều Frameworks: TensorFlow, OpenCV, OpenVINO, PyTorch, TensorRT, ONNX, CoreML, etc.
- So với YOLOv3,mAP và FPS của YOLOv4 tăng tương ứng 10% và 12%.
- So với EfficientDet, YOLOv4 nhanh hơn khoảng 2 lần.
- Chi tiết xem tại đây

- YOLOv5:
- Ra đời chỉ vài ngày sau YOLOv4
- Có 4 phiên bản khác nhau: YOLOv5s, YOLOv5m, YOLOv5l, YOLOv5x. Độ chính xác tăng dần và tốc độ giảm dần theo thứ tự đó.
- So sánh với YOLOv4:
- “If you’re a developer looking to incorporate near realtime object detection into your project quickly, YOLOv5 is a great choice. If you’re a computer vision engineer in pursuit of state-of-the-art and not afraid of a little more custom configuration, YOLOv4 in Darknet continues to be most accurate.”
- CSPDarknet53s-YOSPP gets 19.5% faster model inference speed and 1.3% higher AP than YOLOv5l.
1.5 SSD - Single Shot Detector
SSD cũng là một thuật toán thuộc nhóm Single Stage Detector. Ảnh đầu vào được cho đi qua mạng VGG-16 để trích xuất Feature Maps với các hệ số Scale khác nhau. Tiếp theo, nó dự đoán nhãn và vị trí của đối tượng sử dụng Conv layers. Output là một tập các Bounding Box và xác suất có đối tượng bên trong đó. Cuối cùng áp dụng NMS để loại bỏ đi những Bounding Box không phù hợp.
Chi tiết về SSD, bạn có thể tham khảo ở đây

Khá ngạc nhiên là mặc dù ra đời từ năm 2015 nhưng đến nay vẫn không có thêm phiên bản mới nào của SSD, trong khi YOLO thì ra phiên bản mới liên tục.
Về tốc độ xử lý và độ chính xác thì nói chung SSD ngang ngửa với YOLOv3 và chỉ chịu thua YOLOv4. Các bạn có thể xem so sánh chi tiết ở đây, và ở đây nữa
Ngoài các thuật toán kể trên, còn có 1 số thuật toán Object Detection khác như EfficientDet, RatinaNet, … Bạn có thể đọc thêm về những thuật toán này từ các nguồn trên Internet. Đến thời điểm hiện tại, ý kiến của cá nhân mình thì YOLOv4 đang là State-of-Art cho bài toán Object Detection, cả về tốc độ và độ chính xác. Mình luôn áp dụng YOLOv4 đầu tiên trong các dự án về Object Detection của mình, nếu có vấn đề gì thì mới chuyển qua thuật toán khác.
2. Metrics đánh giá Object Detection model
Để đánh giá một Classification model, ta thường sử dụng các Metrics: Precision, Recall, F1-Score, Accuracy.
Để đánh giá một Regression model, ta thường sử dụng các Metrics: Root Mean Square (RMS), Mean Square Error (MSE), Mean Absoluate Error (MAE), … Nhược
Để đánh giá một Object Detection model, ta dùng Metrics nào?
Để trả lời câu hỏi này, hãy nhớ lại 2 mục đích của một Object Detection model là:
- Classification: Phân loại đối tượng trong bức ảnh thuộc vào lớp nào?
- Localization: Xác định chính xác vị trí của đối tượng trong bức ảnh.
Vì vậy, Metrics đánh giá một Object Detection model cần phải kết hợp cả 2 mục tiêu này. Hiện nay, Mean Average Precision (mAP) được sử dụng rộng rãi để đánh giá các Object Detection model. Về bản chất, mỗi một lớp (class - nhãn) trong bài Object Detection model có một giá trị AP riêng, mAP là trung bình của các giá trị AP đó. Vì AP được tính cho mỗi lớp nên trong cách tính AP dưới đây, bạn có thể thấy rằng ta chỉ sử dụng kết quả dự đoán Bounding Box mà không sử dụng kết quả dự đoán nhãn của model.
2.1 Intersection over Union - IoU
Trước tiên, cần hiểu khái niệm IoU. Như cái tên của nó đã gợi nhớ, IoU là tỉ số giữa phần giao nhau và phần hợp nhau của 2 Bounding Box. Ground Trust(GT - Bounding Box mà ta vẽ bằng tay khi đánh nhãn đối tượng) Bounding Box và Bounding Box mà model dự đoán ra được.

Giá trị IoU nằm trong khoảng [0;1]. IoU = 0 ngụ ý rằng model dự đoán sai hoàn toàn, IoU = 1 ngụ ý rằng model dự đoán chính xác hoàn toàn.
Thông thường, sẽ có một giá trị ngưỡng (threshold) của IoU để xác định Bounding Box dự đoán ra có được chấp nhận hay không? Threshold thường là 0.5 hoặc 0.75. Nếu IoU > Threshold, Bounding Box là hợp lệ và ngược lại.
2.2 Precision và Recall
Precision và Recall được xác định thông qua công thức:
$Precision = \frac{TP}{TP + FP}$
$Recall = \frac{TP}{TP + FN}$
Sử dụng IoU và Threshold, ta có thể xác định được TP, FP, TN, FN như sau:
- Nếu IoU >= Threshold, Bounding Box được coi là TP - True Positive.
- Nếu IoU < Threshold, Bounding Box được coi là FP - False Positive.
- Nếu có đối tượng trong bức ảnh nhưng model không phát hiện được (không dự đoán được Bounding Box) –> FN - False Negative.
- Mọi phần trong bức ảnh mà không có đối tượng và model cũng dự đoán là không có đối tượng –> TN - True Negative.
Precision and Recall được tính cho mỗi đối tượng trong bức ảnh. Chúng ta cũng cần xem xét đến giá trị Confidence Score trả ra từ model. Các Bounding Box có Confidence lớn hơn một giá trị ngưỡng được coi là Positive và ngược lại.
2.3 Tính toán mAP
- Bước 1 - Vẽ đồ thị Precision - Recall
Thể hiện 2 giá trị Precision và Recall trên đồ thị PR, Precision trên trục y, Recall trên trục x.

Mong đợi rằng đồ thị PR (đường màu xanh) sẽ có dạng đơn điệu giảm dần từ trái sang phải theo giá trị của Precision. Nếu không, chúng ta sẽ phải sử dụng giá trị interpolation - nội suy của Pricsion (đường màu đỏ) - $p_{interp}$. Giá trị $interp_p$ tại mỗi vị trí bằng giá trị lớn nhất của Precision ở bên phải của vị trí đó. Vì AP được tính bằng trung bình của 11 điểm $p_{interp}$ nên ta thể hiện 11 điểm trên đồ thị PR, tương ứng với Recall từ 0.0, 0.1, …, 1.0
-
Bước 2 - Tính AP
$AP = \frac{1}{11}\sum_{r \in {0,0.1,0.2,...,1}}p_{interp}(r) = \frac{1}{11} (1 + 0.8 + 0.6 + 0.5 + 0.5 + 0.5 + 0.45 + 0.48 + 0.48 + 0.35 + 0.2) = 0.53$
-
Bước 3 - Tính mAP mAP được tính bằng trung bình của tất cả các AP của mỗi class.
$mAP = \frac{1}{n}\sum_{i=1}^n AP_i$
Trong đó, $n$ là số class mà model có thể phát hiện.
3. Kết luận
Bài này, mình đã giới thiệu đến các bạn những kiến thức khái quát về các thuật toán Object Detection và một Metrics mAP để đánh giá các thuật toán đó. Hi vọng các bạn sẽ có được cái nhìn toàn diện để có thể lựa chọn được thuật toán phù hợp với bài toán của mình. Để hiểu sâu hơn về mỗi thuật toán đó, mình khuyên các bạn nên đọc kỹ bài báo gốc của nó và bắt tay vào train/test lại chúng trên bộ dữ liệu của mình. Có rất nhiều hướng dẫn trên Internet giúp các bạn làm điều này.
Ở bài tiếp theo, chúng ta sẽ chuyển qua tìm hiểu về bài toán Sematics Segmentation. Mời các bạn đón đọc.
4. Tham khảo
[1] Renu Khandewal, “Evaluating performance of an object detection model”, Available online: https://towardsdatascience.com/evaluating-performance-of-an-object-detection-model-137a349c517b (Accessed on 12 May 2021).
[2] Jędrzej Świeżewski, “YOLO Algorithm and YOLO Object Detection: An Introduction”, Available online: https://appsilon.com/object-detection-yolo-algorithm/ (Accessed on 12 May 2021).
[3] Analytics Vidhya, “A Review of Object Detection Models”, Available online: https://medium.com/analytics-vidhya/a-review-of-object-detection-models-f575c515655cl (Accessed on 12 May 2021).