Text Detection với EAST

Trước khi có sự ra đời của học sâu trong bài toán Text Detection, hầu hết các phương pháp đều khó thực hiện trong các tình huống phức tạp của dữ liệu thực tế. Các phương pháp này sử dụng những kỹ thuật xử lý ảnh truyền thống và thủ công, chúng thường có nhiều giai đoạn và kết thúc với hiệu suất tổng thể không thực sự thuyết phục. Trong bài viết này, chúng ta sẽ tìm hiểu một thuật toán dựa trên học sâu (EAST) để phát hiện văn bản bằng một mạng nơron duy nhất.
1. Giới thiệu EAST
EAST - pipeline được giới thiệu trong bài báo EAST: An Efficient and Accurate Scene Text Detector vào năm 2017. Nó có thể phát hiện Text theo cả 2 cấp độ: Words và Line. Nó cũng không hạn chế quá nhiều điều kiện của ảnh đầu vào, ảnh có thể xoay, mờ, nhiễu (nói vậy không có nghĩa là ta có thể bỏ qua bước Pre-processing Image); Text trên ảnh có thể thuộc một trong 2 loại: Structure và Unstructure. Tại thời điểm ra đời, EAST vượt trội hơn hẳn so với các phương pháp trước đó.
2. Kiến trúc của EAST
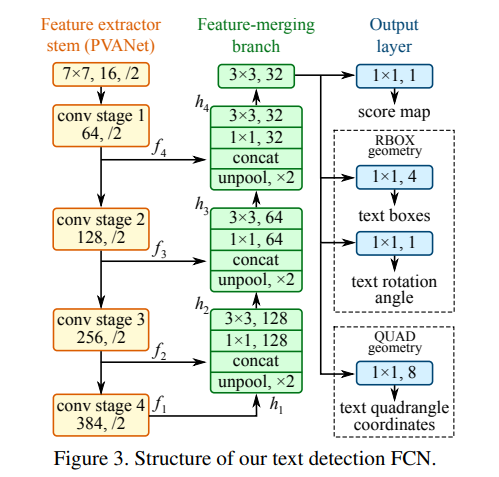
Kiến trúc tổng thể của EAST gồm 3 phần:
-
Feature Extractor Stem - Phần này làm nhiệm vụ trích xuất đặc trưng từ ảnh đầu vào theo 4 cấp độ, từ $f_1$ đến $f_4$. Trong bài báo, tác giả sử dụng 2 Pre-trained model là VGG16 và PVANet cho thí nghiệm của mình.
-
Feature Merging Branch - Các Features từ phần trên được cho đi qua các lớp Unpool, sau đó được tập hợp lại, cuối cùng là đi qua lần lượt các lớp 1x1 Conv, 3x3 Conv. Mục đích của việc làm này là để EAST có thể dự đoán được Text ở những khu vực nhỏ.
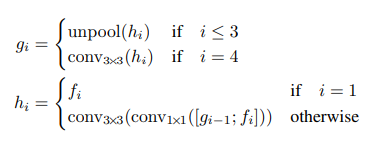
-
Output Layer - Ouput Layer chứa Score Map và Geometry Map. Score Map cho ta biết xác suất xuất hiện Text trong một khu vực, còn Geometry Map chứa thông tin về tọa độ Bounding Box của khu vực đó. Bounding Box có thể được đưa ra dưới dạng Rotated Box (tọa độ của điểm top-left, chiều dài, chiều rộng, góc quay) hoặc Quadrangle (đầy đủ tọa độ 4 điểm của hình chữ nhật).
3. Loss Function
Loss Function của EAST là tổng Loss của Score Map và Geometry Map.
$L = L_s + \lambda_gL_g$
Trong đó, $L_s$ là Loss Function của Score Map, còn $L_g$ là Loss Function của Geomatry Map. Hằng số $\lambda_g$ là trọng số thể hiện mức độ quan trong của $L_g$, nó nhận giá trị trong khoảng [0,1]. Trong bài báo thì tác giả đang sử dụng $\lambda_g$ = 1.
4. Non-max Suppression Mergin Stage
Output của Geomatry Map đối với một khu vực có thể có rất nhiều, Chỉ một Output lớn hơn giá trị ngưỡng quy định bởi Locality-Aware NSM mới được giữ lại.
5. Sử dụng EAST model
Có khá nhiều Source Code của EAST trên Github. Trong phần này, mình sẽ sử dụng Github của argman để làm thực nghiệm.
5.1 Clone EAST Repository
$ git clone https://github.com/argman/EAST.git

5.2 Compile LANMS
EAST sử dụng Locality-Aware NMS (LSNMS) thay vì NSM chuẩn, trong Github này, LSNMS được viết bằng C++. Để nó có thể làm việc được với Python, chúng ta cần biên dịch nó thành thư viện .so
- Cài đặt công cụ cần thiết:
$ sudo apt-get install build-essential
-
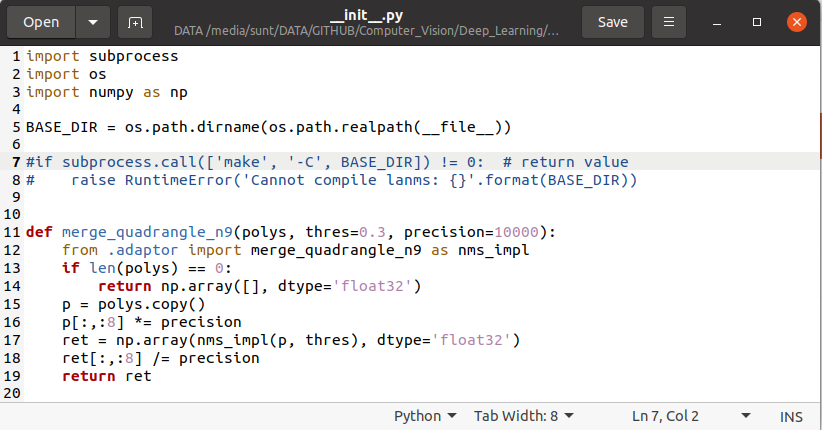
Mở file init.py trong thư mục lanms, và Comment Out 2 dòng 7 và 8 như hình:
-
Chạy lệnh sau để biên dịch
$ cd EAST/lanms/
$ make
5.3 Test EAST model
Trước tiên cần phải có EAST model. Nếu có đủ dữ liệu của riêng mình, chúng ta có thể huấn luyện nó lại từ đầu như hướng dẫn trên Github argman. Ở đây, mình chọn Pre-trained EAST model, download tại đây.
- Chuyển đổi Code từ TF 1.xx sang TF 2.xx Source Code trên Github được viết bằng Tensorflow phiên bản 1.xx. Thời điểm hiện tại, hầu hết các model mới đều chuyển sang sử dụng Tensorflow phiên bản 2.xx. Để chạy được với Tensorflow 2.xx, chúng ta cần làm thêm 1 bước chuyển đổi Code từ TF 1.xx sang TF 2.xx.
$ tf_upgrade_v2 --intree . --outtree tf2_version --reportfile report.txt
Source Code mới tương thích với TF 2.xx được di chuyển hết vào thư mục tf2_version. Tuy nhiên, vẫn còn 1 lỗi mà chưa thể chuyển đổi tự động được, ta phải sửa bằng tay.
Dòng 60, file nets/resnet_v1.py: from tensorflow.contrib import slim -> import tf_slim as slim
Dòng 43, file nets/resnet_utils.py: slim = tf.contrib.slim -> import tf_slim as slim
Tất nhiên, ta phải cài thêm thư viện tf_slim: pip install tf_slim.
- Chạy EAST model
Thực hiện lệnh sau:
$ cd tf2_version
$ python eval.py --test_data_path=training_samples/ --gpu_list=0 --checkpoint_path=east_icdar2015_resnet_v1_50_rbox/ --output_dir=outputs/
Ở đây, ta dùng cách ảnh trong thư mục training_samples để test, kết quả được lưu ra thư mục outputs.

Hiện tại, EAST đã được tích hợp sẵn trong OpenCV phiên bản 4.xx. Chúng ta có thể dễ dàng sử dụng nó mà không cần phải làm nhiều bước dài dòng như thế này. Tham khảo cách sử dụng EAST trong OpenCV tại đây.
6. Kết luận
Bài này, mình đã giới thiệu đến các bạn những kiến thức khái quát về EAST model, dùng cho nhiệm vụ Text Detection của bài toán OCR: ưu/nhược điểm, kiến trúc, cách làm việc và cách sử dụng nó từ Source Code trên Github.
Ở bài tiếp theo, mình giới thiệu về model CRNN và CTC để thực hiện Text Recognition. Mời các bạn đón đọc.
7. Tham khảo
[1] X.Zhou, C.Yao, H.Wen, et al, EAST: An Efficient and Accurate Scene Text Detector. arXiv preprint arXiv:1704.03155.
[2] TheAILearner, “Efficient and Accurate Scene Text Detector (EAST)”, Available online: https://theailearner.com/2019/10/19/efficient-and-accurate-scene-text-detector-east/ (Accessed on 06 May 2021).
[3] TheAILearner, “Implementation of EAST”, Available online: https://theailearner.com/2021/03/10/implementation-of-east/ (Accessed on 06 May 2021).