Giới thiệu bài toán OCR
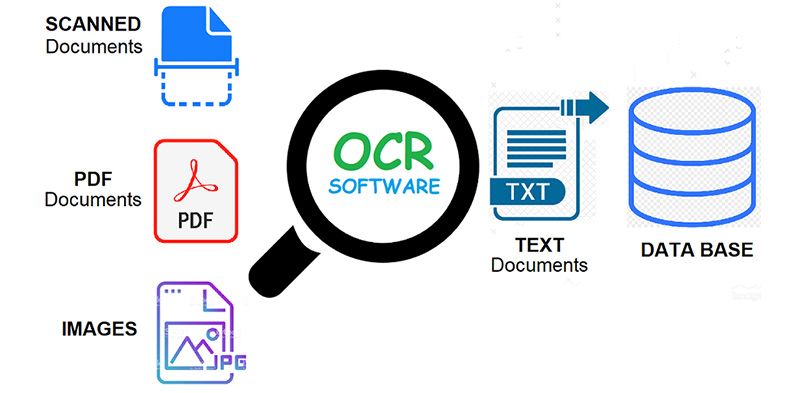
1. OCR là gì?
OCR, viết tắt của Optical Character Recognition là một phương pháp chuyển đổi các văn bản, ký tự xuất hiện trong hình ảnh, hay các tài liệu scaned thành định dạnh mà máy tính có thể hiểu được. Từ đó, chúng ta có thể dễ dàng chỉnh sửa, tìm kiếm, và thực hiện rất nhiều công việc khác. Nếu đưa cho máy tính một hình ảnh chứa các văn bản, ký tự thì máy tính chỉ coi đó là một bức ảnh đại diện bởi ma trận các giá trị của từng pixel trong ảnh đó.
2. Ứng dụng của OCR
OCR có rất nhiều ứng dụng trong thực tế. Có thể kể ra đây một số ví dụ sau:
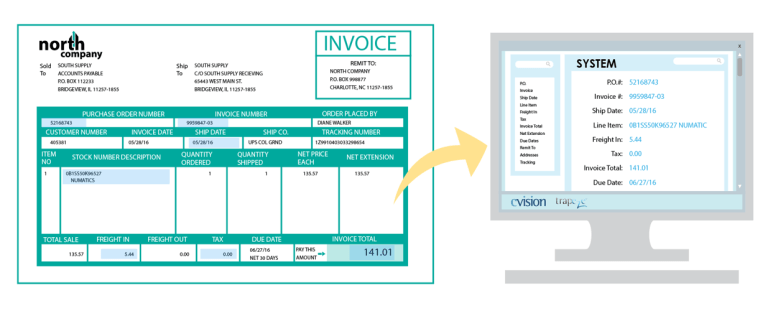
- Automatic Data Entry - Tự động nhập liệu
Đây có lẽ là ứng dụng phổ biến và quan trọng nhất của OCR. Trước đây, đối với những số liệu trong một hình ảnh hay tài liệu scan, để đưa vào máy tính xử lý, con người phải nhập thủ công bằng tay. Việc này rất mất thời gian và nhàm chán. Ngày nay, với sự hỗ trợ của OCR, quá trình này diễn ra hoàn toàn tự động, nhanh chóng, dễ dàng, độ chính xác cao.
- Nhận diện biển số xe
Áp dụng trong các bãi đỗ xe, tự động nhận diện biển số giúp giảm thời gian quản lý cho cả người lái xe và nhân công bảo vệ.

- Xe tự lái
OCR giúp xe tự động nhận diện biển số để đi theo đúng chỉ dẫn.

- Book Scanning
OCR giúp chuyển sách giấy thành sách điện từ một cách dễ dàng.

Và còn rất rất nhiều ứng dụng khác nữa.
3. OCR Pipeline
OCR hoạt động theo một Pipeline như sau:
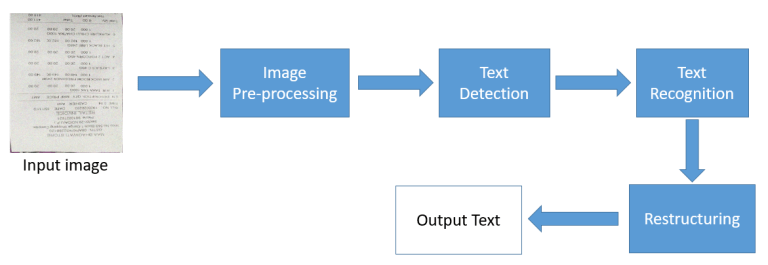
3.1 Image Pre-processing
Đây là bước tiền xử lý hình ảnh trước khi đưa vào cho model học tập. Các images có thể bị mờ, bị nhiễu, bị lệch, … Nếu để nguyên như vậy đưa vào model thì kết quả sẽ rất kém. Nhiệm vụ của Image Pre-processing là cố gắng loại bỏ những lỗi như vậy.

3.2 Text Detection
Như cái tên đã chỉ ra, nhiệm vụ của bước này là tìm ra khu vực trong hình ảnh chứa ký tự/văn bản.
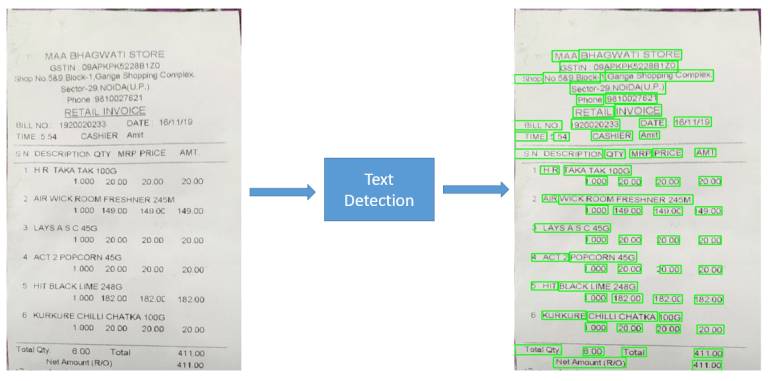
Có 2 kiểu ký tự/văn bản trong hình ảnh mà bài toán OCR có thể giải quyết:
- Ký tự/văn bản có cấu trúc: Là những hình ảnh tương đối rõ ràng, background cố định, font chữ cố định, màu sắc cố định, ký tự/văn bản được tổ chức ngay ngắn theo hàng/cột, … Ví dụ, trang sách.

- Ký tự/văn bản phi cấu trúc: Là những hình ảnh có ký tự/văn bản xuất hiệu không sự thống nhất về màu sắc, vị trí, kiểu chữ, … Ví dụ: bảng quảng cáo.

Rõ ràng, giải quyết kiểu thứ 2 khó hơn rất nhiều so với kiểu thứ nhất.
Để thực hiện nhiệm vụ Text Detection, có thể tiếp cận theo 3 cách:
- Cách 1 - Phát hiện từng ký tự một (Character-by-Character).
- Cách 2 - Phát hiện từng từ một (Word-by-Word).
- Cách 3 - Phát hiện từng dòng một (Line-by-Line).

Nhìn chung, hầu hết các hệ thống OCR đều sử dụng cách tiếp cận thứ 2 hoặc 3. Cách 1 chậm và độ chính xác thấp hơn.
Về mặt kỹ thuật, có 2 cách có thể sử dụng:
- Cách 1- Sử dụng các kỹ thuật xử lý ảnh cơ bản (truyền thống) Cách này sử dụng các bộ lọc (filters) để tách rời các ký tự ra khỏi nền của bức ảnh, sau đó áp dụng các kỹ thuật phát hiện biên, Contours để thu được vị trí của từng ký tự riêng rẽ. Một số cái tên điển hình sử dụng nguyên lý này là Stroke Width Transform (SWT), Maximally Stable Regions (MSER).
Trong điều kiện tương đối lý tưởng, dữ liệu sạch sẽ, ít nhiễu thì phương pháp này tỏ ra khá hiệu quả, độ chính xác cao và dễ thực hiện. Tuy nhiên, trong thực tế, rất khó để đảm bảo những điều kiện như vậy.
- Cách 2 - Sử dụng kỹ thuật Deep Learning Sử dụng DL, nói chung là hiệu quả hơn rất nhiều so với phương pháp bên trên, bởi vì chúng có khả năng học từ dữ liệu nên không bị ảnh hưởng quá nhiều bởi các yếu tố môi trường. Một số model nổi bật là Connectionist Text Proposal Network (CTPN), Efficient and Accurate Scene Text Detector (EAST), … Các Object Detection models khác như SSD, Yolo, Faster RCNN cũng có thể thực hiện được nhiệm vụ này.
Ở cách 2 này, nếu chia nhỏ hơn nữa thì có thể thành: Simplified pipeline và Multi-steps.

Hai model CTPN và EAST đều thuộc nhóm Simplified Pipeline. Trong các bài tiếp theo, chúng ta sẽ tìm hiểu kỹ hơn EAST model.
3.3 Text Recognition
Các ký tự/văn bản trong từng khu vực phát hiện ở bước bên trên sẽ được nhận diện cụ thể ở bước này.
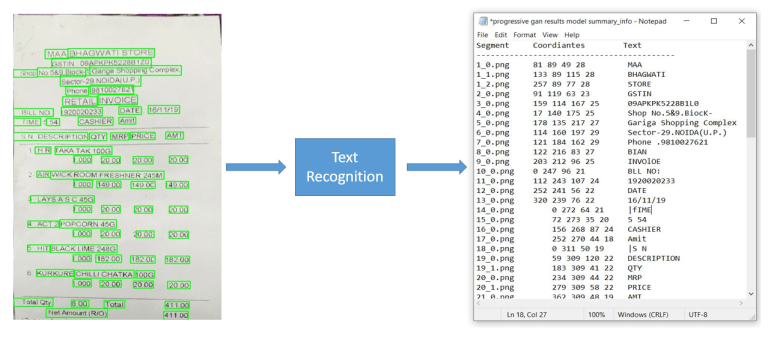
Tương tự như Text Detection, ở đây cũng có 2 phương pháp giải quyết là dùng kỹ thuật xử lý ảnh cơ bản và dùng kỹ thuật Deep Learning.
Đối với cách thứ nhất, sau khi tách riêng được từng ký tự ra khỏi nền, sẽ cho chúng đi qua mội bộ phân lớp để nhận diện. Cách này xử lý ở mức Characters, phụ thuộc nhiều vào kết quả của Text Detection và môi trường nên độ chính xác không cao.
Cách thứ 2 hiện nay đã chứng tỏ được tính ưu việt của nó so với cách thứ nhất. Hai model nổi bật sử dụng DL cho nhiệm vụ này là:
- CRNN - Connectionist Temporal Classification (CTC) based.
- Attention-based.
Trong các bài tiếp theo, chúng ta sẽ tìm hiểu kỹ hơn về 2 model này.
3.4 Restructing
Ở bước cuối cùng này, ký tự/văn bản sau khi nhận dạng xong sẽ được sắp xếp lại đúng theo vị trí của nó như trong hình ảnh bản đầu. Mục đích của việc làm này là để thuận tiện trong việc trích chọn ra các thông tin cần thiết, dựa vào vị trí tương đối của chúng với nhau.

4. Kết luận
Bài này, mình đã giới thiệu đến các bạn những kiến thức tổng quát về bài toán OCR: OCR là gì, các bước thực hiện như thế nào, có các phương pháp gì, ưu/nhược điểm của từng phương pháp.
Ở bài tiếp theo, mình giới thiệu về model EAST để thực hiện Text Detection. Mời các bạn đón đọc.
5. Tham khảo
[1] TheAILearner, “Optical Character Recognition: Introduction and its Applications”, Available online: https://theailearner.com/2021/03/10/optical-character-recognition-introduction-and-its-applications/ (Accessed on 04 May 2021).
[2] TheAILearner, “Optical Character Recognition Pipeline”, Available online: https://theailearner.com/2019/05/28/optical-character-recognition-pipeline/ (Accessed on 04 May 2021).
[3] TheAILearner, “OOptical Character Recognition Pipeline: Text Detection”, Available online: https://theailearner.com/2021/01/28/optical-character-recognition-pipeline-text-detection/ (Accessed on 04 May 2021).
[4] TheAILearner, “Optical Character Recognition Pipeline: Text Recognition”, Available online: https://theailearner.com/2019/05/29/optical-character-recognition-pipeline-text-recognition/ (Accessed on 04 May 2021).