CNN - Một hành trình phát triển từ 63.3% đến 90.2%
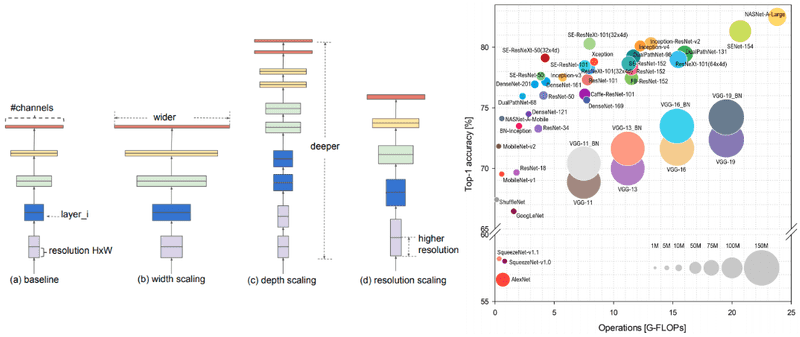
Năm 2012, Alexnet ra đời với độ chính xác trên tập dữ liệu ImageNet được công bố là 63.3%. Từ đó đến nay, trải qua gần 9 năm phát triển, có rất nhiều kiến trúc mới của CNN nối tiếp nhau ra đời, cái sau tốt hơn cái trước. Thời điểm hiện tại, EfficientNet có lẽ là kiến trúc đạt được độ chính xác trên ImageNet cao nhất, lên đến hơn 90% khi huấn luyện bằng phương pháp Teacher-Student.
Bài viết này, mục đích là nhìn lại toàn bộ quá trình phát triển đó của CNN, không chỉ đưa ra số liệu, bảng biểu, đồ thị mà còn tóm tắt lại nguyên lý cơ bản của mỗi kiến trúc CNN.
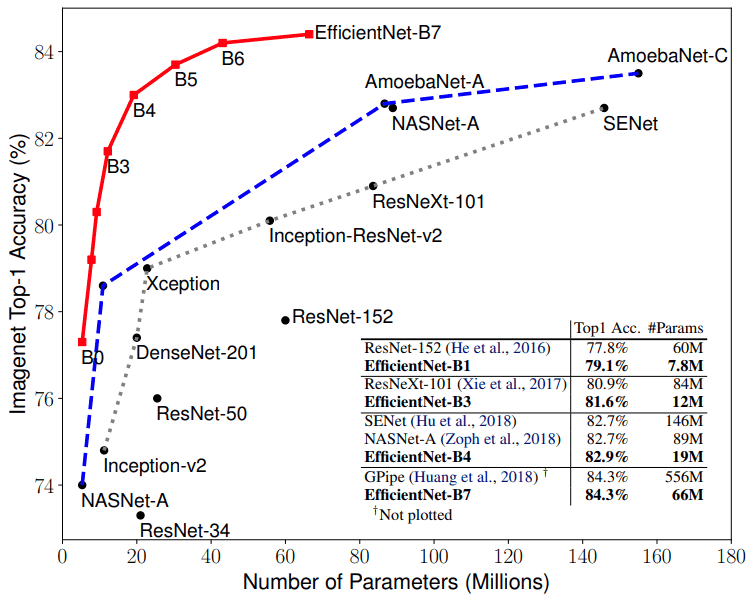
Simone Bianco, năm 2018, đã đưa ra một tóm tắt về Top Performing CNNs Model, thể hiện như hình dưới đây:
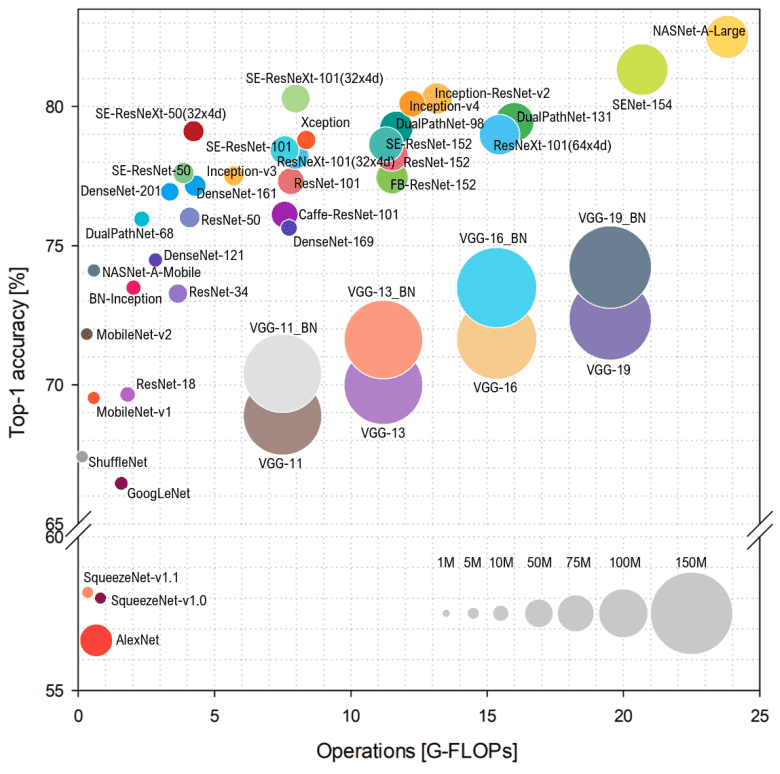
Trong hình trên, trục Y thể hiện độ chính xác của model trên tập ImageNet, trục X (Floating Point Operations Per Second - FLOPS) chỉ ra mức độ phức tạp của model. Bán kính của vòng tròn càng lớn, model càng có nhiều tham số. Từ tổng kết này, rõ ràng rằng không phải cứ có nhiều tham số thì độ chính xác sẽ cao hơn.
1. Một số thuật ngữ sử dụng trong bài
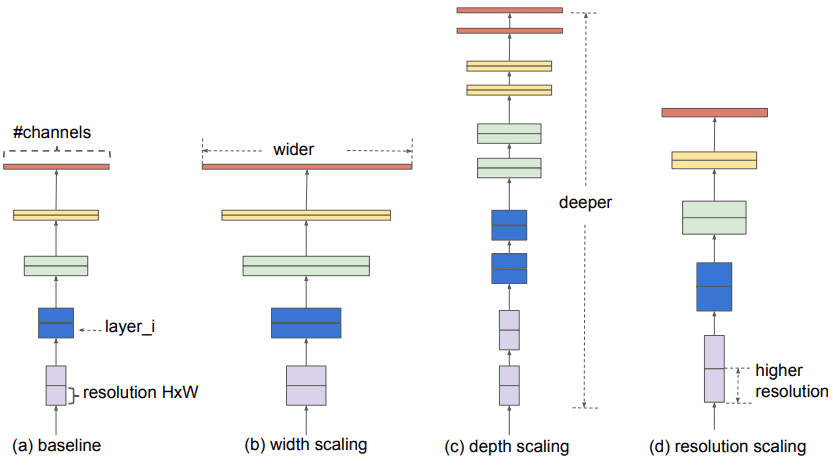
Để tránh làm các bạn bối rối khi theo dõi bài viết, mình sẽ giải thích trước một số thuật ngữ được sử dụng ở đây:
- Wider network - Network có nhiều Feature Maps (Filters).
- Deeper network - Network có nhiều Convolutional layers.
- High Resolution network - Network nhận Input Image có độ phân giải lớn (Spatial resolutions).
2. AlexNet: ImageNet Classification with Deep Convolutional Neural Networks (2012)
Alexnet được tạo thành từ 5 Conv Layers, bắt đầu từ 11x11 kernel, giảm dần đến 3x3 kernel. Nó là kiến trúc CNN đầu tiên sử dụng Max-Pooling layers, ReLU Activation function, và Dropout. Alexnet được sử dụng cho bài toán phân loại hình ảnh, số lượng nhãn lên đến 1000. Đó là một điều rất bất ngờ tại thời điểm bấy giờ.
Chúng ta có thể tạo ra Alexnet chỉ với khoảng 35 dòng Pytorch code:
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
Alexnet cũng là mô hình đầu tiên huấn luyện thành công trên tập ImageNet, đạt được Top-5 Error Rate là 15.3%.
3. VGG (2014)
Kiến trúc VGG xuất hiện trong bài báo Very Deep Convolutional Networks for Large-Scale Image Recognition vào năm 2014. Đây là nghiên cứu đầu tiên cung cấp bằng chứng không thể phủ nhận rằng chỉ cần thêm nhiều lớp Conv trong kiến trúc sẽ tăng hiệu quả quả model. Tuy nhiên, giả định này chỉ đúng đến một thời điểm nhất định. Các tác giả của bài báo chỉ sử dụng các Filters có kích thước 3x3, trái ngược lại với Alexnet. Ảnh đầu vào để huấn luyện model là ảnh RGB có kích thước 224x224.
VGG được đặc trưng bởi sự đơn giản của nó, chỉ sử dụng các lớp Conv với Kernel 3 × 3 xếp chồng lên nhau theo chiều sâu ngày càng tăng. Việc giảm kích thước được xử lý bằng cách sử dụng Max-pooling. Ba Fully-Connected layers, trong đó 2 lớp đầu, mỗi lớp có 4.096 nodes, lớp còn lại có 1000 nodes (tương ứng với 1000 classes), được theo sau bởi một bộ phân loại Softmax.

Có 2 phiên bản của VGG thường hay được sử dụng là VGG16 và VGG19. Các con số 16, 19 chỉ ra số Weights layers của mỗi model (cột D và E trong bảng trên). Ở thời điểm năm 2014 thì 16 và 19 layers được xem là rất deep rồi. Bây giờ thì chúng ta có kiến trúc ResNet có số lượng layers từ 50-200.
VGG có 2 nhược điểm:
- Thời gian huấn luyện rất lâu nếu bạn ko có GPU.
- Dung lượng của model sau khi huấn luyện xong rất lớn (VGG16 là khoảng 533MB, còn VGG19 khoảng 574MB). Điều này làm cho VGG khó triển khai trên các thiết bị có bộ nhớ khiêm tốn.
VGG vẫn thi thoảng được sử dụng trong một số ứng dụng như Image Classification, Feature Extraction, … nhưng nhìn chung thì các kiến trúc nhỏ nhẹ (SqueezeNet, GoogleNet, …) vẫn được ưu chuộng hơn.
4. InceptionNet/GoogleNet (2014)
Sau VGG, bài báo Going Deeper with Convolutions viết bởi Christian Szegedy cũng tạo ra một bước đột phá lớn. Bài báo ra đời xuất phát từ suy nghĩ rằng việc tăng độ sâu của model không phải các duy nhất làm cho nó tốt hơn. Tại sao không mở rộng model trong khi vẫn cố gắng duy trì sự tính toán ở mức độ ổn định?
Kiến trúc của GoogleNet bao gồm nhiều Inception Module, mỗi Module hoạt động như một multi-level feature extractor (bộ trích xuất đặc trưng nhiều tầng) bằng cách sử dụng các Filters có kích thước khác nhau: 1x1, 3x3, 5x5. Output của các Filters sau đó được tổng hợp lại trước khi đưa vào Module tiếp theo.
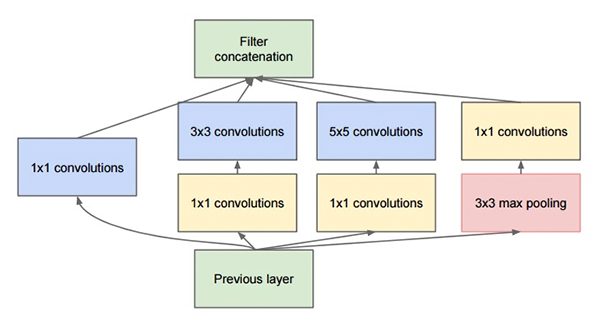
Filter 1x1 đặt trước cac Filters 3x3 và 5x5 để giảm số lượng Input Channel, từ đó giảm giúp chi phí tính toán của kiến trúc GoogleNet.
4.1 Inception V2
Trong bài báo năm 2014 thì kiến trúc này có tên là GoogleNet, đến bài báo Rethinking the Inception Architecture for Computer Vision (2015), với một chút cải tiến để tăng hiệu quả, nó được đặt tên là Inception V2 và Inception V3.
Sự cải tiến của Inception V2 so với GoogleNet thể hiện ở 2 điểm:
-
Thay thế Filter 5x5 bằng 2 Filters 3x3 chồng lên nhau, mục đích là để tăng tốc độ xử lý vì theo lý thuyết, thời gian để một Filter 5x5 tính toán băng 2.78 lần so với Filter 3x3.
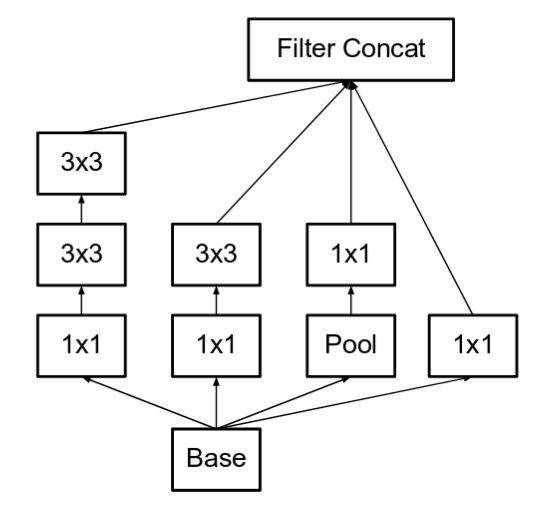
-
Tách Filter nxn thành 1xn và nx1. Ví dụ, với Filter 3x3 sẽ tương đương với 1x3 và 3x1. Theo thực nghiệm thì việc làm này sẽ giảm được khoảng 33% chi phí tính toán.

4.2 Inception V3
Inception V3 tiếp tục cải tiển từ Inception V2:
- Sử dụng RMSProp Optimizer.
- Thêm Filter 7x7.
- Sử dụng BatNorm sau các FC layers.
- Sử dụng Label Smoothing.
Dung lượng của Inception V3 khá nhỏ so với VGG, chỉ khoảng 96MB.
Code thực hiện GoogleNet bằng Pytorch như sau:
import torch
import torch.nn as nn
class InceptionModule(nn.Module):
def __init__(self, in_channels, out_channels):
super(InceptionModule, self).__init__()
relu = nn.ReLU()
self.branch1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0),
relu)
conv3_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)
conv3_3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.branch2 = nn.Sequential(conv3_1, conv3_3,relu)
conv5_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)
conv5_5 = nn.Conv2d(out_channels, out_channels, kernel_size=5, stride=1, padding=2)
self.branch3 = nn.Sequential(conv5_1,conv5_5,relu)
max_pool_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv_max_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)
self.branch4 = nn.Sequential(max_pool_1, conv_max_1,relu)
def forward(self, input):
output1 = self.branch1(input)
output2 = self.branch2(input)
output3 = self.branch3(input)
output4 = self.branch4(input)
return torch.cat([output1, output2, output3, output4], dim=1)
model = InceptionModule(in_channels=3,out_channels=32)
inp = torch.rand(1,3,128,128)
print(model(inp).shape)
5. ResNet: Deep Residual Learning for Image Recognition (2015)
Từ sau khi VGG ra đời, người ta đã từng nghĩ rằng cứ thêm nhiều lớp Conv thì model sẽ hoạt động tốt hơn. Nhiều người trong số họ cũng thử tiến hành các thực nghiệm với số lớp Conv nhiều hơn của VGG. Tuy nhiên, tất cả đều gặp phải một vấn đề, đó là Vanishing Gradient.
ResNet ra đời đã giải quyết được phần nào vấn đề này. Ý tưởng của nó là đưa vào trong kiến trúc của mình các Identity Shortcut Connection hay Skip Connection, để sử dụng thông tin của các layers trước đó cho layer hiện tại. Nhờ vậy mà hạn chế được hiện tượng Vanishing Gradient khi số lớp Conv tăng lên.

Với việc áp dụng ý tưởng này, số lớp Conv của Resnet có thể tăng đến con sô 150 lớp (Resnet-150).
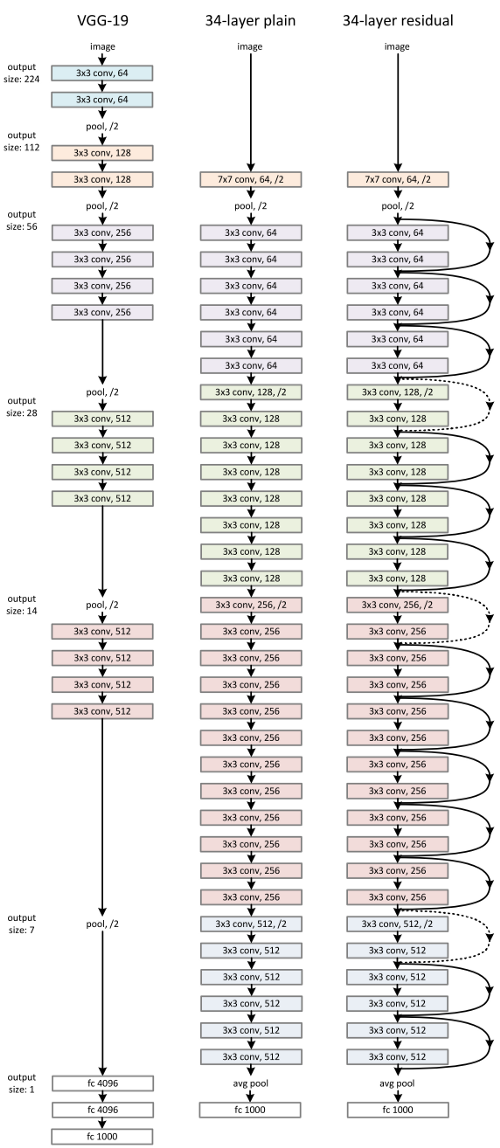
Torchvision cung cấp sẵn một số Pre-trained của các phiên bản Resnet, bạn có thể import trực tiếp vào và sử dụng chúng.
import torchvision
pretrained = True
# A lot of choices :P
model = torchvision.models.resnet18(pretrained)
model = torchvision.models.resnet34(pretrained)
model = torchvision.models.resnet50(pretrained)
model = torchvision.models.resnet101(pretrained)
model = torchvision.models.resnet152(pretrained)
model = torchvision.models.wide_resnet50_2(pretrained)
model = torchvision.models.wide_resnet101_2(pretrained)
Bản thân mình không thích từ Skip Connection hay từ dịch nghĩa bỏ qua kết nối vì thực tế ResNet có bỏ qua kết nối nào đâu (nhìn vào hình minh họa thấy rất rõ ràng). Chẳng qua là nó thêm đường tắt, bắc cầu từ các lớp Conv trước đó đến chính nó. Do vây, dùng từ Shortcut Connection mới chính xác, phản ánh đúng bản chất của ResNet.
6. DenseNet: Densely Connected Convolutional Networks (2017)
DenseNet tiếp tục giải quyết vấn đề cố hữu khi sử dụng nhiều lớp Conv, đó là Vanishing Gradient.

Đối với mạng CNN truyền thống (VGG, …) thì Input của một lớp chính là Ouput của lớp ngay trước đó.
$x_i = H_i(x_{i-1})$
ResNet mở rộng hành vi này bằng cách thêm vào thông tin của một lớp trước đó nữa (không nhất thiết là lớp ngay trước mà có thể trước vài lớp) thông qua Shortcut Connection.
$x_i = H_i(x_{i-1} + x_{i-n})$
DenseNet tiếp tục mở rộng, nó tổng hợp thông tin của tất cả các lớp trước đó làm Input cho lớp hiện tại.
$x_i = H_i([x_0, x_1, ..., x_{i-1}])$
Tạo DenseNet model trong Torchvision như sau:
import torchvision
model = torchvision.models.DenseNet(
growth_rate = 16, # how many filters to add each layer (`k` in paper)
block_config = (6, 12, 24, 16), # how many layers in each pooling block
num_init_features = 16, # the number of filters to learn in the first convolution layer (k0)
bn_size= 4, # multiplicative factor for number of bottleneck (1x1 cons) layers
drop_rate = 0, # dropout rate after each dense conv layer
num_classes = 30 # number of classification classes
)
print(model) # see snapshot below
Ban đầu, DenseNet được đề xuất để sử dụng cho bài toán Image Classification, nhưng về sau nó còn được sử dụng cho rất nhiều bài toán khác, như thống kê dưới đây.

7. Big Transfer (BiT): General Visual Representation Learning (2020)
BiT là một biến thể của ResNet. Cả ba phiên bản của nó (small, medium và large) đều dựa trên ResNet152. BiT-large sử dụng ResNet152x4 và được huấn luyện trên tập JFT chứa khoảng 300M hình ảnh đã đánh nhãn, lớn hơn rất nhiều so với ImageNet.
Đóng góp lớn nhất của kiến trúc này là việc sử dụng các Normalization Layers. Tác giả đã sử dụng Group Normalization và Weight Standardization thay vì Batch Normalization.

8. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (2020)
EfficientNet được đề xuất bởi Mingxing Tan và Quoc V. Le tại Google trong bài báo EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. Kết quả nghiên cứu của các tác giả chỉ ra rằng nó đạt được dộ chính xác tốt hơn nhiều so với các kiến trúc CNN trước đó.
Ý tưởng của EfficientNet là thay vì tìm ra một kiến trúc tối ưu từ đầu thì nó xuất phát từ một Base model F, sau đó dần dần mở rộng, cải tiến nó dần lên.
Tuy nhiên, hãy nhớ lại một số vấn đề cần chú ý trong các kiến trúc từ trước đến giờ khi Scale-up từng thành phần riêng lẻ (Individual Scaling):
- Deeper Network có thể nắm bắt được nhiều các Features phức tạp hơn nhưng rất khó huấn luyện do vấn đề Vanishing Gradient.
- Wider Network có thể nắm bắt được nhiều các Featureschi tiết hơn nhưng cũng khó huấn luyện do vấn đề Saturate Gradient.
- High Resolution Network cũng có thể nắm bắt được nhiều các Featureschi tiết hơn nhưng độ chính xác giảm dần khi gặp những hình ảnh có độ phân giải thấp hơn.
Rút kinh nghiệm từ những vấn đề trên, EfficientNet tiến hành Scale-up đồng thời cả 3 thành phần, gọi là Compound Scaling.
Để tìm ra các hệ số Scale-up cho 3 thành phần đó, các nhà nghiên cứu đã sử dụng phương pháp chia tỷ lệ kết hợp. Grid-search được áp dụng để tìm mối quan hệ giữa các chiều có tỷ lệ khác nhau của Base-model trong điều kiện hạn chế tài nguyên cố định. Sử dụng chiến lược này, tác giả đã tìm được các hệ số tỷ lệ thích hợp cho mỗi chiều để có thể tăng lên. Từ các hệ số này, Base-model có thể được Scale-upe lên theo kích thước mong muốn.
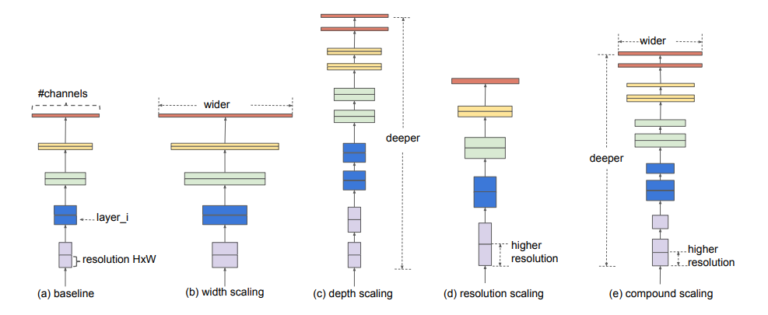
Việc áp dụng Compound Scaling rõ ràng đã cải thiện được hiệu quả đáng kể so với Individual Scaling.
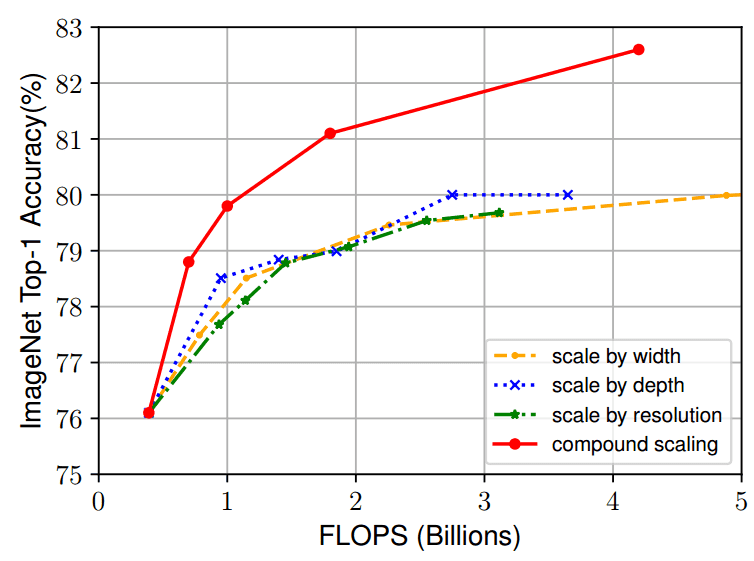
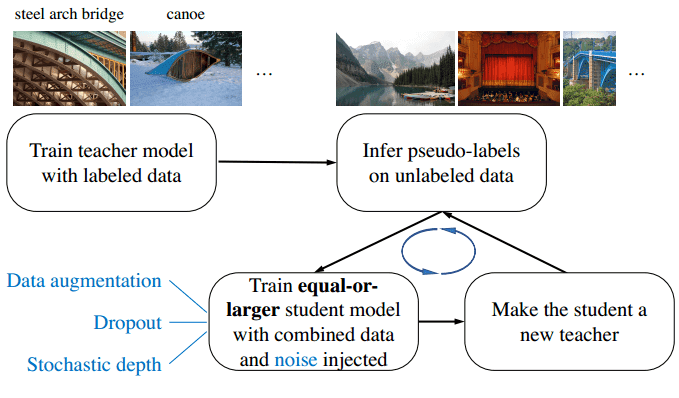
9. Noisy Student Training: Self-training with Noisy Student improves ImageNet classification (2020)
Xuất hiện sau EfficientNet một thời gian ngắn, Noisy Student Training đưa ra một phương pháp huấn luyện mới, sử dụng EfficientNet làm kiến trúc nền tảng. làm tăng đáng kể độ chính xác trên tập dữ liệu ImageNet.
Phương pháp này bao gồm 4 bước như sau:
- Bước 1 - Huấn luyện một Teacher model trên tập dữ liệu đã được gán nhãn (tập A).
- Bước 2 - Sử dụng Teacher model để sinh ra nhãn cho 300M ảnh chưa có nhãn (pseudo labels) (tập B)
- Bước 3 - Huấn luyện Student model trên tổng dữ liệu (tập A và B).
- Bước 4 - Lặp lại bước 1 bằng cách coi Student model như là Teacher model.
Về mặt lý thuyết, Student model sẽ hiệu quả hơn Teacher model vì nó được huấn luyện trên nhiều dữ liệu hơn. Ngoài ra, một lượng lớn nhiễu (Noise) cũng được thêm vào trong quá trình huấn luyện Student model để giúp nó học hiệu quả hơn từ tập B.
Một số kỹ thuật như Dropout, Data Augmentation, … cũng được áp dụng.
10. Meta Pseudo-Labels (2021)
Quay lại phương pháp Noisy Student Training, một vấn đề phát sinh là nếu như các Pseudo Labels không chính xác thì Student model sẽ không thể cải thiện được so với Teacher model, thậm chí là tồi hơn. Vấn đề này được gọi bằng cái tên Sự xác nhận sai lệch trong gán nhãn giả (confirmation bias in pseudo-labeling).
Để khác phục vấn đề này, một ý tưởng mới xuất hiện, đó là thiết kế một cơ chế phản hồi từ Student model đến Teacher model, để Teacher model sinh ra nhãn đúng hơn.
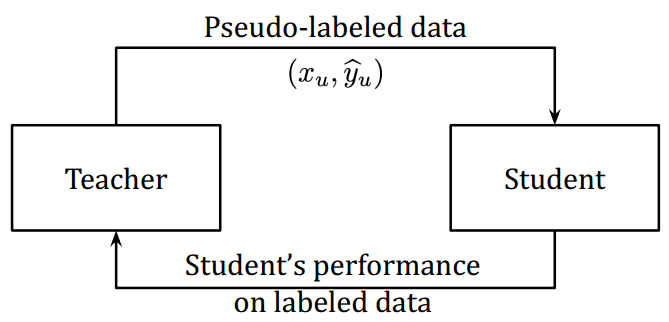
Bằng cách này, cả Teacher và Student đều tham gia vào quá trình huấn luyện cùng nhau, giúp nhau học tập tốt hơn - Together to better (Ý tưởng của phương pháp này nghe hơi giống với cách thức mà model GAN hoạt động nhỉ, :D).
11. Kết luận
Bảng sau so sánh các kiến trúc CNN đã trình bày từ đầu đến giờ, về các khía canh: số lượng tham số, độ chính xác trên tập ImageNet và năm công bố.
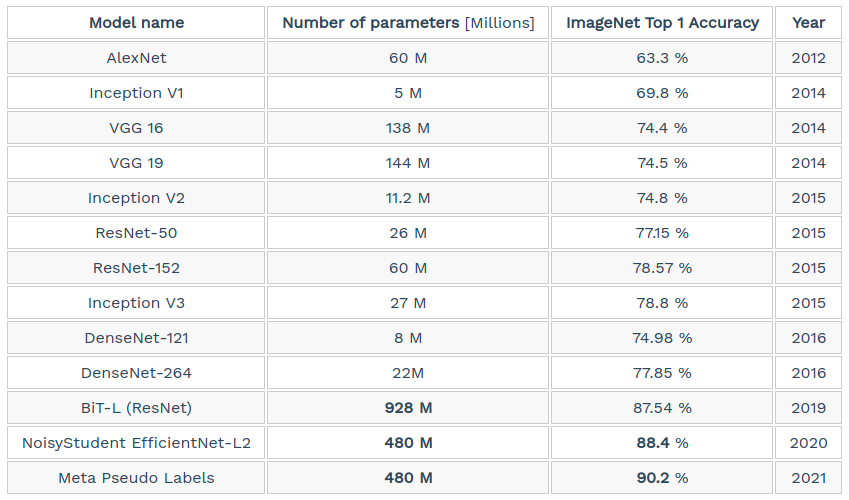
Có thể rút ra một số nhận xét sau:
- Model DenseNet có ít tham số nhất, model BiT-L có nhiều tham số nhất.
- Model Meta Pseudo Labels đạt được độ chính xác cao nhất trên tập ImageNet.
- Không phải cứ nhiều tham số hơn thì độ chính xác cao hơn.
Trong bài này, chúng ta đã cũng nhau nhìn lại chặng đường phát triển của các kiến trúc CNN thông qua một số models tiêu biểu. Hầu hết các models đều được cung cấp dưới dạng Pre-trained trong Keras hay Torchvision. Bạn có thể thử sử dụng chúng và Fine-tune trên tập dữ liệu của bạn để so sánh và đánh giá kết quả, giữa các models với nhau và so với việc tạo và huấn luyện model từ đầu.
Trong 3 bài tiếp theo, mình sẽ giới thiệu về bài toán OCR và hướng dẫn huấn luyện OCR model. Mời các bạn đón đọc.
11. Tham khảo
[1] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60(6), 84-90.
[2] Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
[3] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., … & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
[4] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
[5] Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., & Houlsby, N. (2019). Big transfer (bit): General visual representation learning. arXiv preprint arXiv:1912.11370, 6(2)
[6] Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700-4708).
[7] Tan, M., & Le, Q. V. (2019). Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946.
[8] Xie, Q., Luong, M. T., Hovy, E., & Le, Q. V. (2020). Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10687-10698).
[9] Pham, H., Xie, Q., Dai, Z., & Le, Q. V. (2020). Meta pseudo labels. arXiv preprint arXiv:2003.10580.
[10] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2818-2826).
[11] Nikolas Adaloglou, “Best deep CNN architectures and their principles: from AlexNet to EfficientNet”, Available online: https://theaisummer.com/cnn-architectures/ (Accessed on 02 May 2021).