Thiết kế hệ thống cho AI model để phục vụ từ 1 đến 1 triệu người dùng
Nếu bạn là người thiết kế giải pháp cho hệ thống phần mềm, (ở công ty mình thường gọi là SA - Solution Architecture) (có sử dụng AI model hoặc không) thì bài viết này dành cho bạn!
Đối với cá nhân mình, một SA ở công ty, công việc của mình bao gồm:
- Tiếp nhận bài toán của khách hàng (KH). KH có thể là các tổ chức, cá nhân ngoài công ty (outsoursing) hoặc chính là công ty mình nếu công ty phát tự triển sản phẩm (product).
- Cùng với đội ngũ BA, phân tích làm rõ yêu cầu của KH.
- Tạo tài liệu “đề xuất phát triển” (Development Proposal) để thống nhất với KH. Tài liệu này thường bao gồm các nội dung:
- Tóm tắt yêu cầu bài toán
- Đưa ra kiến trúc tổng thể giải pháp và các công nghệ sử dụng. Phần này tùy theo đối tượng KH là ai mà mình sẽ trình bày chi tiết hoặc mức tổng quát.
- Các chức năng mà sản phẩm (phần mềm) cung cấp.
- Kế hoạch phát triển dự án, từ thời gian nào để thời gian nào, các mốc phát triển chính.
- Tổ chức dự án: dự án có những ai liên quan (stakeholder), vai trò nhiệm vụ của mỗi người (không cần tên cụ thể, chỉ cần đưa ra các vị trí trong dự án. VD: PM, SM, Developers, QA, …)
- Chi phí dự án: liệt kê chi phí cho từng chức năng lớn, bao gồm cả phần quản lý (chi phí Overhead) và phát triển.
- Cách thức làm việc giữa đội phát triển, quản lý dự án và KH: họp, báo cáo, demo, …
- Các điều kiện cần, điều kiện ràng buộc và hạn chế của dự án.
- Trình bày tài liệu “đề xuất phát triển” với KH. Đây là bước rất quan trọng để thuyết phục KH. Nếu KH đồng ý với những đề xuất đưa ra thì sẽ chinh thức tiến hành thực hiện dự án.
- Đưa ra giải pháp chi tiết hơn cho đội phát triển dự án.
- Theo dõi và hỗ trợ đội phát triển dự án khi có vấn đề khó khăn về kỹ thuật xảy ra. (Viêc quản lý tiến độ phát triển, làm tài liệu dự án hay giao tiếp với KH là trách nhiệm của PM).
- Nghiên cứu, tìm hiểu những công nghệ mới để hướng dẫn lại cho mọi người hoặc áp dụng vào dự án.
- Trong trường hợp đội phát triển dự án không đủ người thì SA có thể tham gia làm cùng như một Developer hoặc nếu đội dự án không đủ năng lực kỹ thuật thì SA tổ chức các buổi đào tạo, huấn luyện cho các thành viên trong đội.
Ngoài ra, ở công ty, mình cũng đang quản lý team AI, đào tạo và phân bổ nguồn lực AI cho các dự án. Thi thoảng thì mình cũng có tham gia làm PM cho một vài dự án nếu mình cảm thấy thú vị.
Chi tiết hơn về công việc của một SA cũng như cách thức làm tài liệu “đề xuất phát triển”, mình sẽ có 1 bài viết chi tiết sau.
Quay trở lại chủ đề chính của ngày hôm nay, mình sẽ hướng dẫn các bạn cách thiết kế một hệ thống phần mềm (có sử dụng công nghệ AI) để nó có thể hoạt động trơn tru từ lúc bắt đầu phát triển, một vài người dùng đến lúc phục vụ hàng triệu người dùng đồng thời.
Đầu tiên, chúng ta phải xác định được phạm vi của dự án, của sản phẩm. Nếu sản phẩm của ta chỉ phục vụ một số ít người dùng hoặc làm ra với mục đích demo thì chúng ta không cần phải làm theo những gì được đề cập trong bài viết này. Vì như thế chẳng khác nào “mang dao mổ trâu giết gà”, vừa tốn công sức lại tốn cả chi phí. Ngược lại, nếu ứng dụng làm ra hướng đến phục vụ số lượng lớn người dùng thì chúng ta phải đặc biệt quan tâm đến thiết kế ngay từ đầu. Nếu không, nó có thể chạy tốt với một vài users, nhưng khi số lượng users tăng lên, nó sẽ không thể đáp ứng được. Lúc đó, có thể chúng ta phải đập đi làm lại từ đầu, rất tốn thời gian, công sức, tiền bạc.
Bài viết này dành cho các dự án đi theo hướng số 2.
1. On-premise hay Cloud Services
Cái đầu tiên bạn phải nghĩ đến là hạ tầng phát triển và triển khai. Có 2 lựa chọn cho các bạn là: On-premise và Cloud Services.
Mỗi cái đều có ưu, nhược điểm riêng, bạn có thể tham khảo ở đây
Về cơ bản thì Cloud Services lợi nhiều hơn hại. Nếu như ở local, chúng ta phải tự xây dựng từ đầu thông qua các thư viện/framework như Docker, Nginx, uWSGI, Kubernetes, … thì trên Cloud hỗ trợ chúng ta rất nhiều trong việc “Scalability” sản phẩm thông qua các dịch vụ mà nó cung cấp. Chúng ta chỉ cần hiểu rõ chức năng, mục đích của từng service để sử dụng đúng mục đích, tránh lãng phí tiền bạc không cần thiết. Và mình cũng khuyến khích các bạn sử dụng Cloud cho mục đích này.
Một số nhà cung cấp Cloud Services khá phổ biến hiện này là AWS, GCP, Azure. Mình chọn GCP để làm ví dụ trình bày trong bài này. Các bạn hoàn toàn có thể áp dụng cho các Cloud Services khác một cách tương tự, chỉ cần hiểu rõ các services của chúng là được.
2. Bước đầu triển khai ứng dụng AI
Giả sử, chúng ta đã huấn luyện thành công một AI model, độ chính xác như mong muốn. Chúng ta cũng tạo ra một API đơn giản (sử dụng Flask, uWSGI, Nginx, …) để nhận các yêu cầu dự đoán (inference) gửi đến model.
Trên GCP, chúng ta tạo ra một VM Instance (nên chon VM Instance dành riêng cho các tác vụ DL, bởi vì nó được tối ưu và bao gồm đầy đủ các thư viện cần thiết như TF, Cuda, …) và copy toàn bộ dự án của chúng ta lên đó. Cấu hình cho phép HTTP traffic từ bên ngoài kết nối đến VM Instance đó.
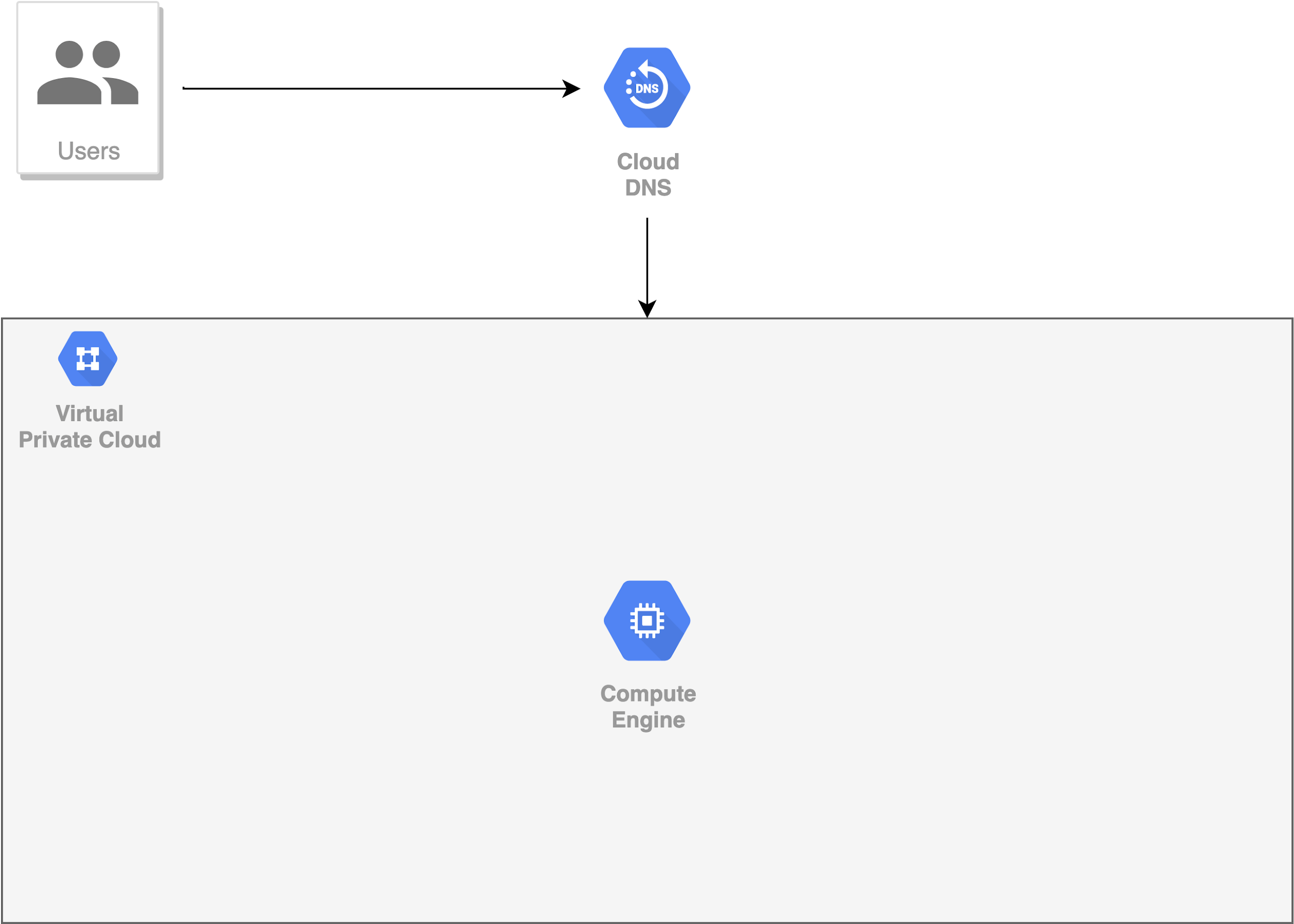
Thử gửi một request đến AI model, kết quả trả về không khác gì khi chạy trên local. Bước đầu, như vậy là thành công.
3. Cấu hình CI/CD Pipeline
Sau một vài ngày (tuần) sử dụng, chúng ta muốn thay đổi model, thay đổi thư viện sử dụng. Chúng ta bắt đầu nhận ra một số bất cập:
- Việc triển khai yêu cầu rất nhiều thao tác thủ công, mất nhiều thời gian.
- Không có sự đồng bộ giữa các phiên bản của AI model cũng như các thư viện sử dụng.
- Khó khăn trong việc debug khi xảy ra lỗi trong quá trình sử dụng.
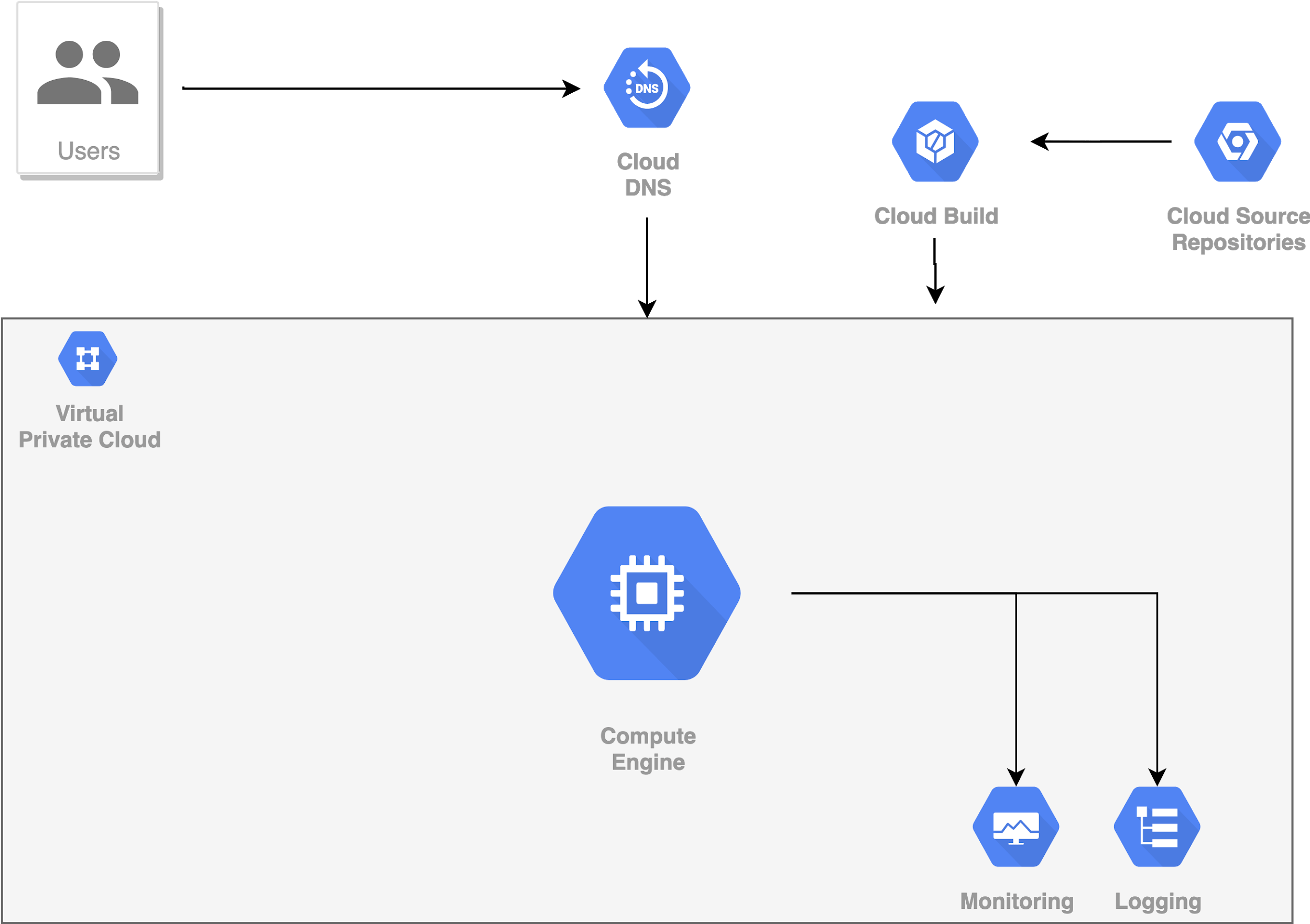
Để giải quyết 2 khó khăn đầu tiên, chúng ta bổ sung thêm CI/CD Pipeline (CD - Continuous integration, CI - Continuous deployment). Pipeline này sẽ tự động hóa việc tạo, kiểm thử và triển khai sản phẩm. Trên local, một số framework hỗ trợ việc này, bao gồm Jenkins, CircleCI. Trên GCP, Pipeline này được triển khai thành Cloud Build service.
Khó khăn còn lại có thể vượt qua bằng cách thêm 2 services là Monitoring và Logging. Một khi có 2 services này, chúng ta có thể biết được toàn bộ quá trình hoạt động của hệ thống, và từ đó biết được chính xác nguyên nhân của lỗi (nếu có).
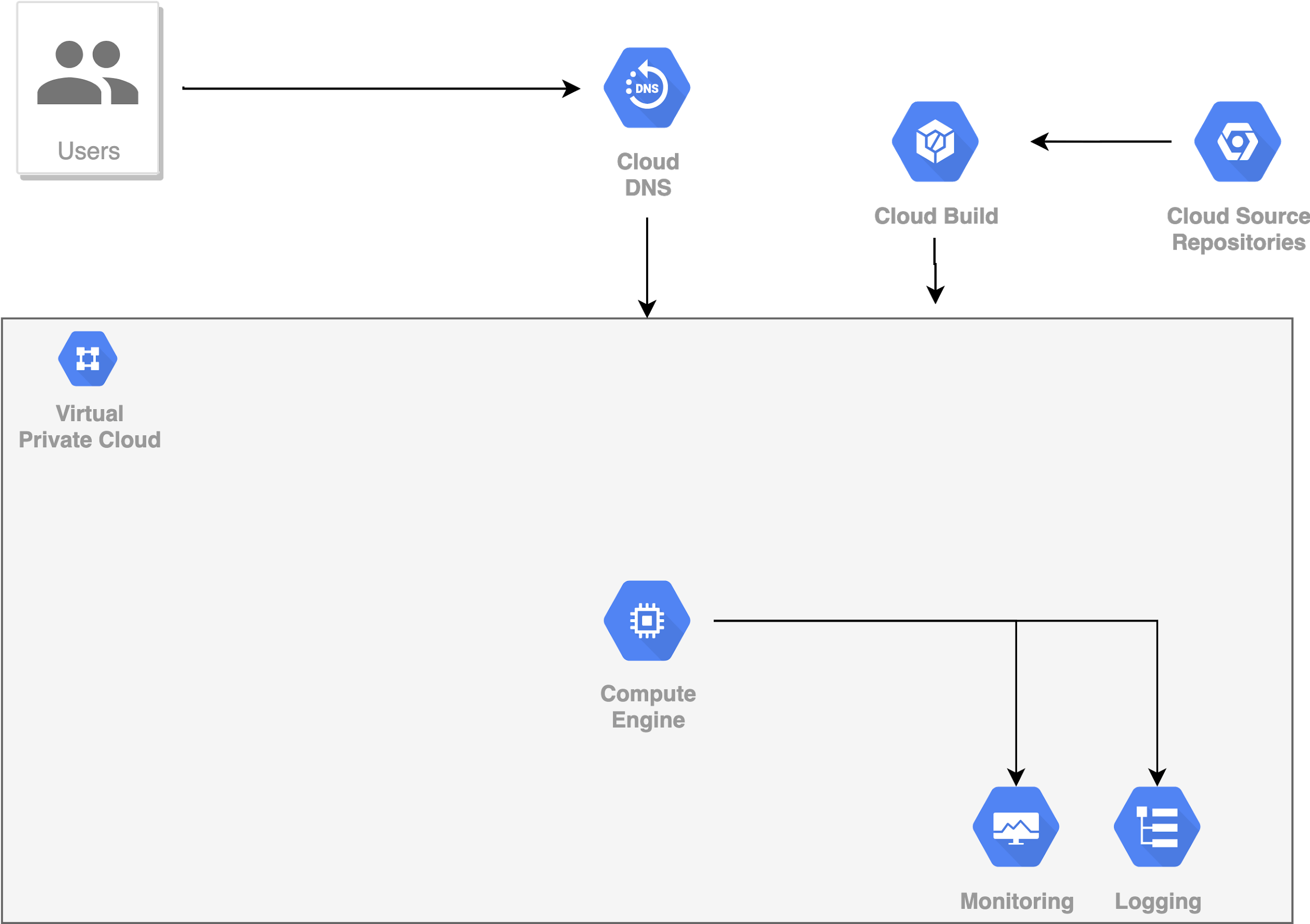
Để thuận tiện hơn nữa, chúng ta nên đóng gói toàn bộ dự án trong một Docker Container, sau đó mới đặt Container đó trong VM Instance. Mỗi lần thêm mới hay cập nhật thư viện, AI model, chúng ta chỉ cần thay đổi trong file Dockerfile, Rebuild lại Container rồi Redeploy. Mọi thứ trở nên rất đơn giản và dễ dàng. Có rất nhiều Docker Container được xây dựng sẵn cho mục đích phục vụ các bài toán DL. Bạn hoàn toàn có thể tải về và sử dụng chúng miễn phí.
4. Scaling
Sau một thời gian sử dụng, ứng dụng của chúng ta đã trở nên phổ biến, số lượng người dùng ngày càng tăng lên. Và VM Instance ban đầu bắt đầu bộc lộ những yếu điểm:
- Thời gian đáp ứng lâu hơn
- Chẳng may VM Instance gặp sự cố thì toàn bộ users không thể sử dụng được ứng dụng.
Lúc này, chúng ta cần đến Scaling. Có 3 loại Scaling:
- Vertical Scaling hay Scaling Up: Tăng cấu hình phần cứng bằng cách thêm CPU, Memory, GPU, Storage vào VM Instance đang sử dụng, làm cho nó có đủ sức mạnh để xử lý đồng thời nhiều yêu cầu đến từ số lượng lớn người dùng. Việc làm này tất nhiên là không thể diễn ra liên tục, nó phải có giới hạn nhất định. Hơn nữa, nếu VM Instance này bị chết thì toàn bộ hệ thống cũng chết theo.
- Horizontal Scaling hay Scaling Out: Tạo thêm các VM Instance mới bằng cách nhân bản VM Instance hiện tại. Các yêu cầu gửi đến sẽ được phân phối đồng đều trên tất cả các VM Instances. Loại Scaling này thường được sử dụng nhiều hơn.
- Scaling Down: Ngược lại với 2 loại Scaling trên, tức là giảm cấu hình phần cứng hoặc giảm số VM Instances sử dụng khi số lượng người dùng giảm.
Đối với Scaling Out, làm thế nào để phân phối các yêu cầu từ người dùng đến các VM Instances? câu trả lời là Load Balancing. Load Balancer chịu trách nhiệm điều tiết traffic ngang qua tất cả các VM Instances, làm tăng tính sẵn sàng phục vụ của toàn hệ thống. Nếu một VM Instance bị chết, Load Balancer sẽ chuyển Traffic đến các Instance khác và Scaling Out sẽ giúp tạo ra VM Instance mới để thay thế VM Instance bị chết. Nói chung, ứng dụng của chúng ta vẫn hoạt động bình thường.
Load Balancer cũng cung cấp các cơ chế mã hóa, bảo mật, xác thực, và kiểm tra sức khỏe các kết nối (health connections checks). Monitoring và Debugging cũng được tích hợp trong Load Balancer.
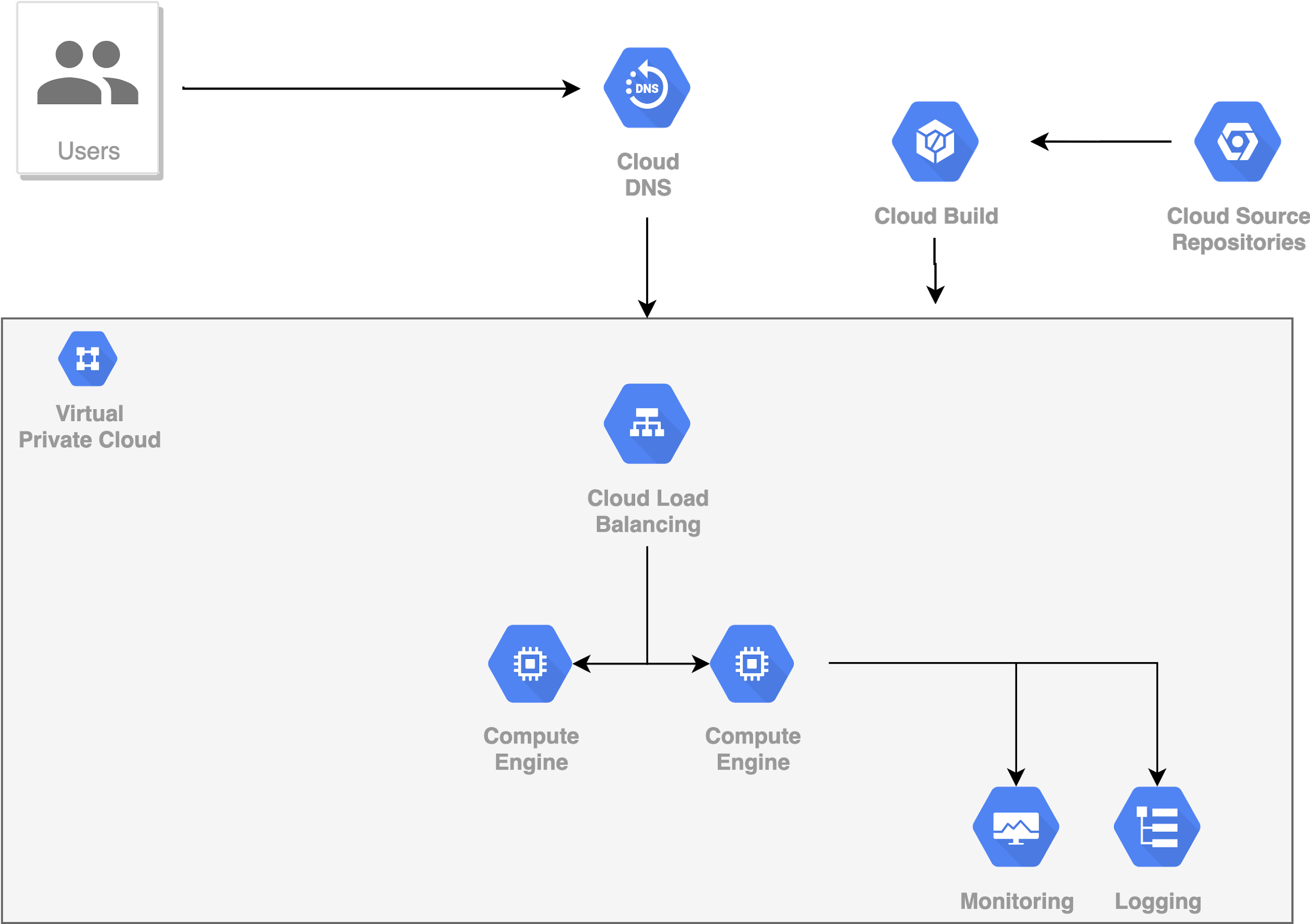
Số lượng VM Instance được thêm mới là không có giới hạn, tùy thuộc vào nhu cầu bài toán. Ngoài ta, các VM Instances có thể được tạo ra ở các khu vực địa lý khác nhau để tối ưu hóa việc gửi nhận và xử lý Traffic.
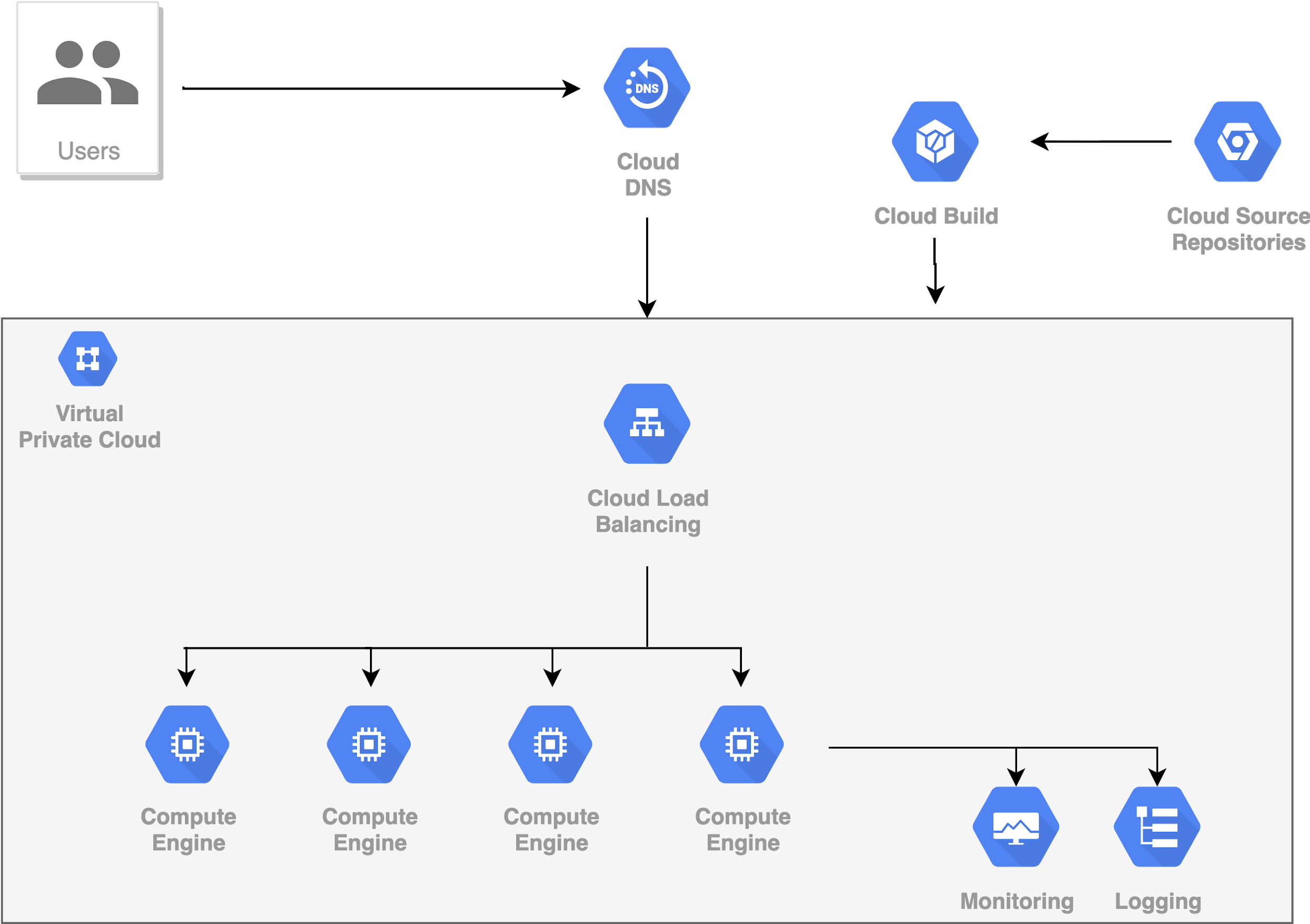
Đến lúc này, nhìn chung hệ thống của chúng ta đã có thể chạy ổn định nếu như không có gì bất thường xảy ra. Nhưng nếu như có gì bất thường xảy ra thì sao?
5. Auto Scaling
Giả sử tại một số thời điểm, ví dụ như các ngày lễ tết, số lượng Request đến hệ thống tăng lên đột biến. Đây là một common case mà chúng ta thường thấy, chúng được gọi chung với cái tên là sudden spikes in traffic.
Vậy làm thế nào để giải quyết tình huống này?
Bạn có thể nghĩ đến việc Scaling Out hệ thống để đáp ứng yêu cầu này. Nhưng khi nào thì thực hiện Scaling Out và Scaling Out bao nhiêu cho đủ. Chúng ta không thể (không nên) tạo ra các VM Instances một cách tùy ý, vì như vậy sẽ tốn rất nhiều tiền. Mọi thứ sử dụng trên hạ tầng Cloud đều phải trả tiền. Auto Scaling là giải pháp cho những tình huống như thế này. Nó là một phương pháp được sử dụng trong điện toán đám mây để thay đổi số lượng tài nguyên tính toán dựa trên tải. Thông thường, điều này có nghĩa là số lượng phiên bản VM Instances tăng lên hoặc giảm xuống, dựa trên một số chỉ số (metrics).
Có 2 loại Auto Scaling:
- Schedule Scaling: Sử dụng khi chúng ta biết trước rằng Traffic sẽ thay đổi tại các thời điểm nào đó. Và để đáp ứng, chúng ta sẽ đặt lịch cho hệ thống tự động Scaling Out/Down tại những thời đỉểm đó.
- Dynamic Scaling: Sử dụng khi chúng ta không biết trước chính xác thời điểm nào lượng Traffic sẽ thay đổi. Vì thế, chúng ta sẽ cấu hình để hệ thống giám sát một số Metrics, khi các Metrics này vượt quá một ngưỡng nào đó thì các VM Instances sẽ tự động được tạo ra để đáp ứng đủ lượng Traffic. Các Metrics ở đây có thể là phần trăm sử dụng CPU, bộ nhớ, hay thời gian đáp ứng yêu cầu, … Ví dụ, chúng ta cấu hình để hệ thống tạo ra số VM Instances gấp đôi khi phần trăm sử dụng của CPU vượt quá 90%, và khi phần trăm này giảm xuống nhỏ hơn 40% thì số lượng VM Instances cũng được giảm giống như trạng thái bình thường.
6. Caching
Có một cách khác rất hiệu quả để giảm thời gian đáp ứng yêu cầu, đó là sử dụng cơ chế Caching. Cơ chế này có thể áp dụng được khi hệ thống của bạn có những yêu cầu đến giống hệt nhau. Khi đó, model của chúng ta chỉ phải xử lý yêu cầu lần đầu, kết quả từ model được lưu trong bộ nhớ Cache. Các yêu cầu đến sau mà giống yêu cầu này thì kết quả sẽ được lấy ra từ bộ nhớ Cache đó. Việc lấy kết quả ra từ từ bộ nhớ Cache thường nhanh hơn rất nhiều so với việc xử lý của model. Tuy nhiên, cũng cần phải lưu ý khi sử dụng cơ chế Caching, đó là phải thiết lập thời gian Time Out cho bộ nhớ Cache. Hết thời gian này mà kết quả nào ko được lấy ra để sử dụng thì sẽ tự động bị xóa khỏi bộ nhớ Cache.
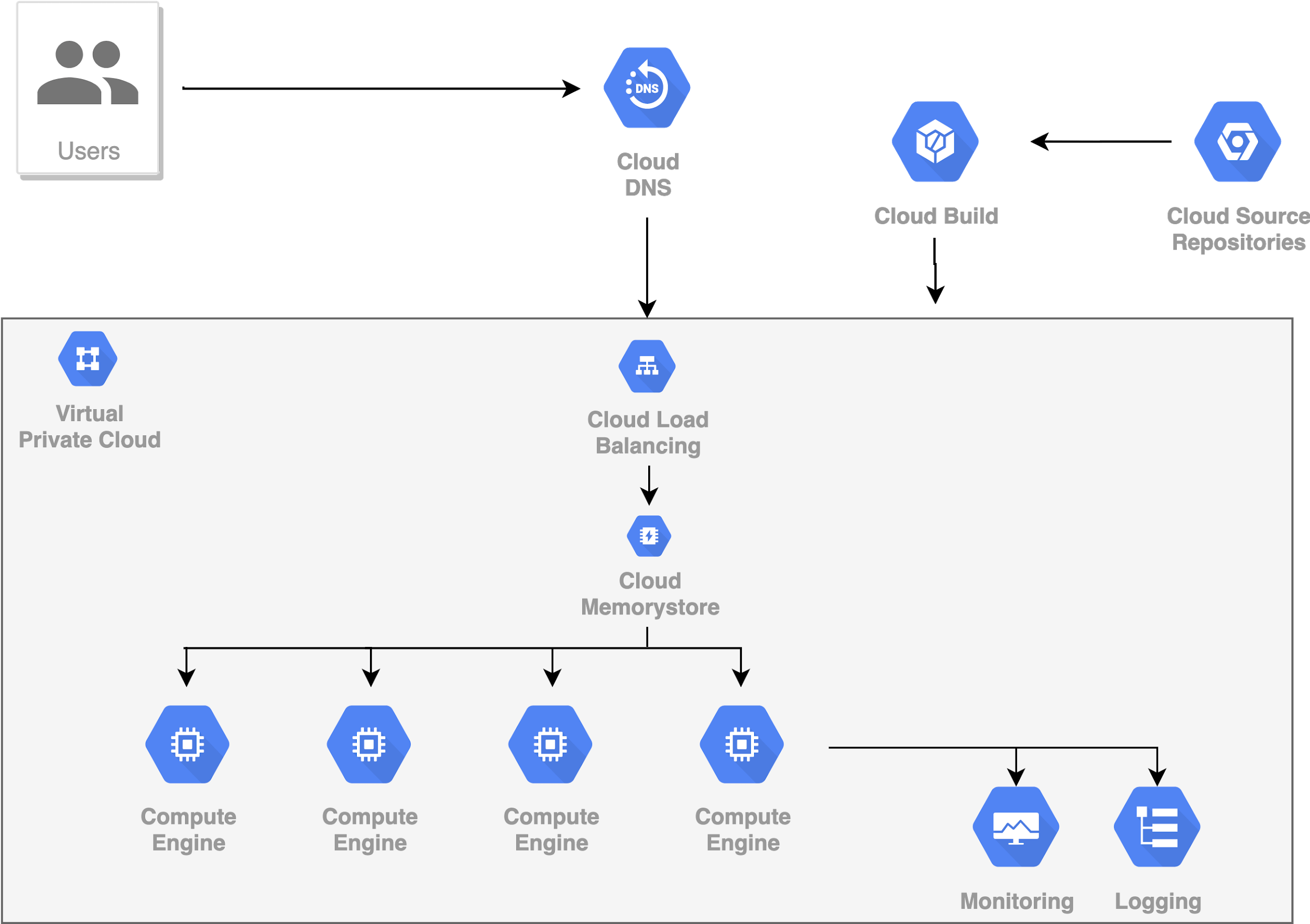
7. Monitoring, Logging & Alerts
Monitoring cũng là một phần không thể thiếu được của bất kỳ hệ thống phục vụ số đông người dùng nào. Mặc dù chúng ta có thể tự tin tạo ra một sản phẩm rất tốt, rất hoàn hảo, chạy trơn tru nhưng chúng ta không thể nào dự đoán hết được những lỗi có thể xảy ra trong suốt quá trình hoạt động của ứng dụng. Lỗi có thể đến từ nguyên nhân khách quan: mất mạng, mất điện, … hoặc chủ quan: code sai, … Nếu hệ thống chỉ phục vụ một vài người thì thi thoảng xảy ra lỗi cũng không phải vấn đề gì quá lớn lao. Nhưng nếu số lượng Users là hàng nghìn, hàng triệu thì mỗi phút không hoạt động sẽ làm tổn tất của chúng ta rất rất nhiều tiền. Đó là lý do chúng ta cần Monitor, Logging hệ thống và Alert khi xảy ra sự cố, để chúng ta có thể nhanh chóng nhận ra và khắc phục sự cố đó nhanh nhất có thể.
Hầu hết các nền tảng Cloud đều cung cấp cơ chế Monitor, Loging & Alert dưới dạng các Services của họ. Thông thường các bước để cấu hình Monitor, Logging & Alert sẽ là:
- Định nghĩa các Metrics và giám sát chúng liên tục (real-time) trong suốt quá hoạt động của hệ thống.
- Trực quan hóa các Metrics đó trên Dashboard dưới dạng các biểu đồ để theo dõi sự thay đổi của chúng theo thời gian (real-time).
- Thông báo đến người quản trị khi có hiện tượng bất thường xảy ra.
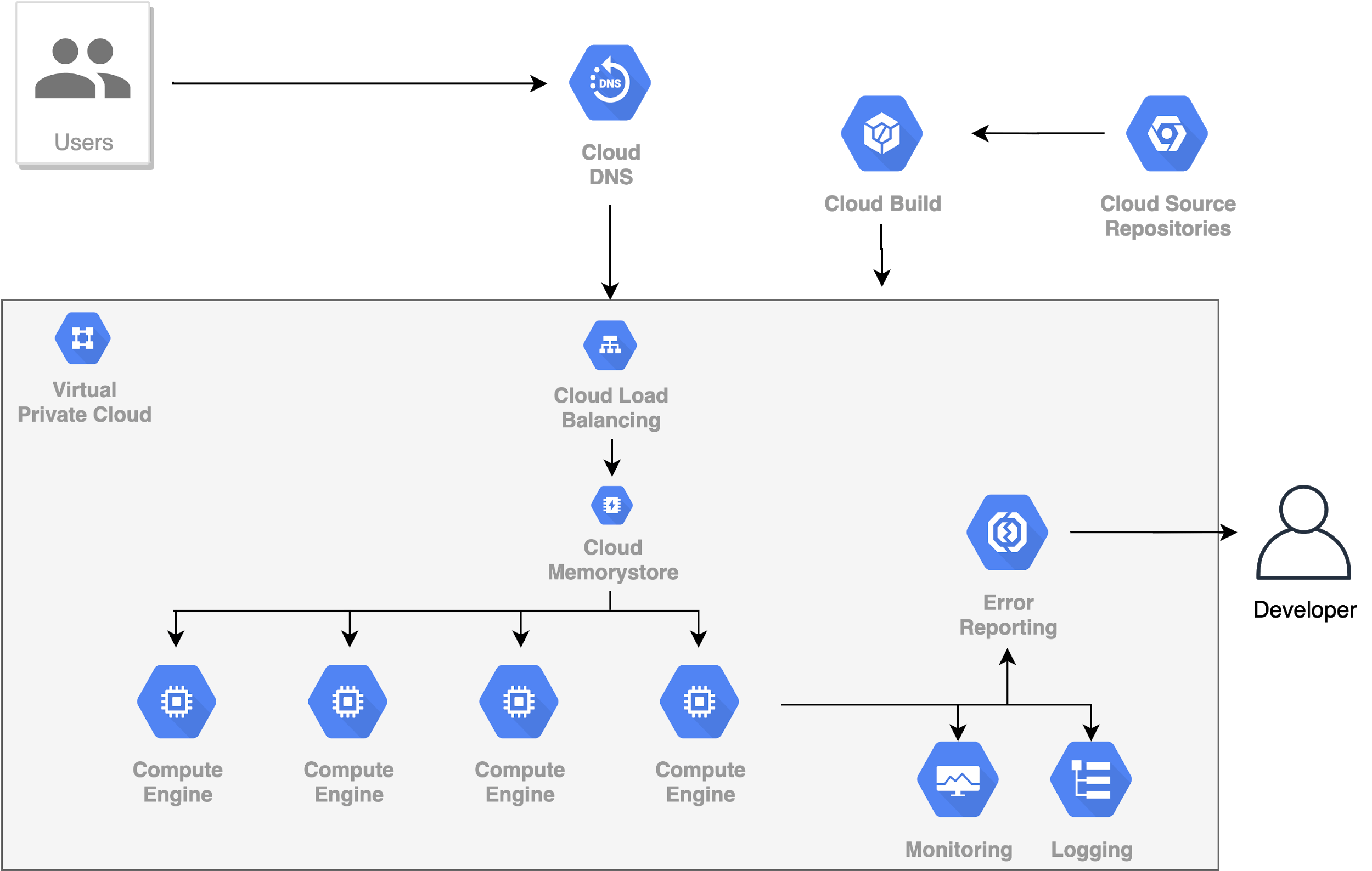
Có được cả 3 cơ chế này trong hệ thống, chúng ta có thể yên tâm ngủ ngon mỗi tối, vì mọi hoạt động của hệ thống đều đang được giám sát và điều khiển. Chúng ta chỉ phải quan tâm khi nhận được cảnh báo, báo cáo lỗi xảy ra.
Những thứ mà mình đã trình bày từ đầu cho đến bước này có thể áp dụng cho tất cả các loại phần mềm nói chung, trong đó có phần mềm sử dụng AI model. Tuy nhiên, riêng với dạng phần mềm có dính dáng đến AI model, chúng ta sẽ phải làm thêm một số bước khác, đặc thù hơn như dưới đây.
8. Retraining AI Model
Ở các bài trước mình đã trình bày về hiện tượng Data Driff và sự cần thiết phải Retraining model. Bạn có thể xem lại tại đây và ở đây.
Để có thể Retraining AI model thì chúng ta phải có dữ liệu mới. Dữ liệu này có thể chính là lịch sử hoạt động của model cũ, hoặc đến từ các phản hồi của KH, của người dùng. Do đó, chúng ta cần có một nơi để lưu trữ những dữ liệu như thế này, chúng ta cần một Database.
Xét về loại Database, chúng ta có thể hơi băn khoăn một chút là nên sử dụng loại Database nào? SQL hay NoSQL. Chi tiết so sánh giữa 2 loại này, các bạn có thể xem thêm tại đây. Còn riêng về khía cạnh Scability thì cả 2 lại Database này đều có thể đáp ứng được, mặc dù nói một cách thành thực thì NoSQL có nhiều điểm mạnh hơn SQL trong cá bài toán kiểu như này. Cá nhận mình thì khuyên các bạn sử dụng NoSQL.
Có đủ data rồi thì chúng ta có thể tiến hành Retraining model theo cách đã trình bày trong bài này và bài [này]](https://tiensu.github.io/blog/40_ai_model_registry/).
Có 2 điều cần chú ý ở đây:
- Các model hoàn toàn độc lập với nhau vì chúng được lưu trong các Docker Container riêng biệt.
- Bản thân model được lưu ở Storage service của Cloud Platform, như S3 của AWS hay Storage của GCP.
Một điều nữa cũng rất quan trọng, đó là không phải lúc nào model mới tạo ra cũng tốt hơn model cũ đang sử dụng. Vì thế, chúng ta phải sử dụng song song cả 2 model đồng thời 1 thời gian để đánh giá, so sánh tính hiệu quả của chúng. Đó chính là phương pháp A/B Testing. Để phân phối Traffic, chúng ta có thể cấu hình Load Balancer gửi đến mỗi model tương ứng. Ví dụ, ban đầu chỉ gửi 5% đến model mới, 95% đến model cũ, sau đó tăng dần lượng Traffic lên model mới cho đến khi đủ thông tin để kết luận rằng nó tốt hơn model cũ. Khi đó, chúng ta sẽ thay thế hoàn toàn model cũ bằng model mới.
9. Offline Inference
Không phải bài toán AI nào cũng yêu cầu phải đáp ứng yêu cầu một cách tức thời. Trong chuyên môn, người ta gọi đó là Online Inference. Còn một loại khác mà model sẽ chỉ trả về kết quả tại một số thời điểm nhất định sau khi nhận được yêu cầu. Đó là kiểu Offline Inference hay Batch Inference, dựa trên cơ chế làm việc bất đồng bộ trong hệ thống. Một thằng thì cứ gửi yêu cầu, sau đó làm việc khác mà không phải chờ nhận kết quả. Một thằng thì cứ thong thả, gom đủ một số lượng yêu cầu nhất định mới trả lời một lần, rồi gửi thông báo đến cho thằng gửi yêu cầu đó.
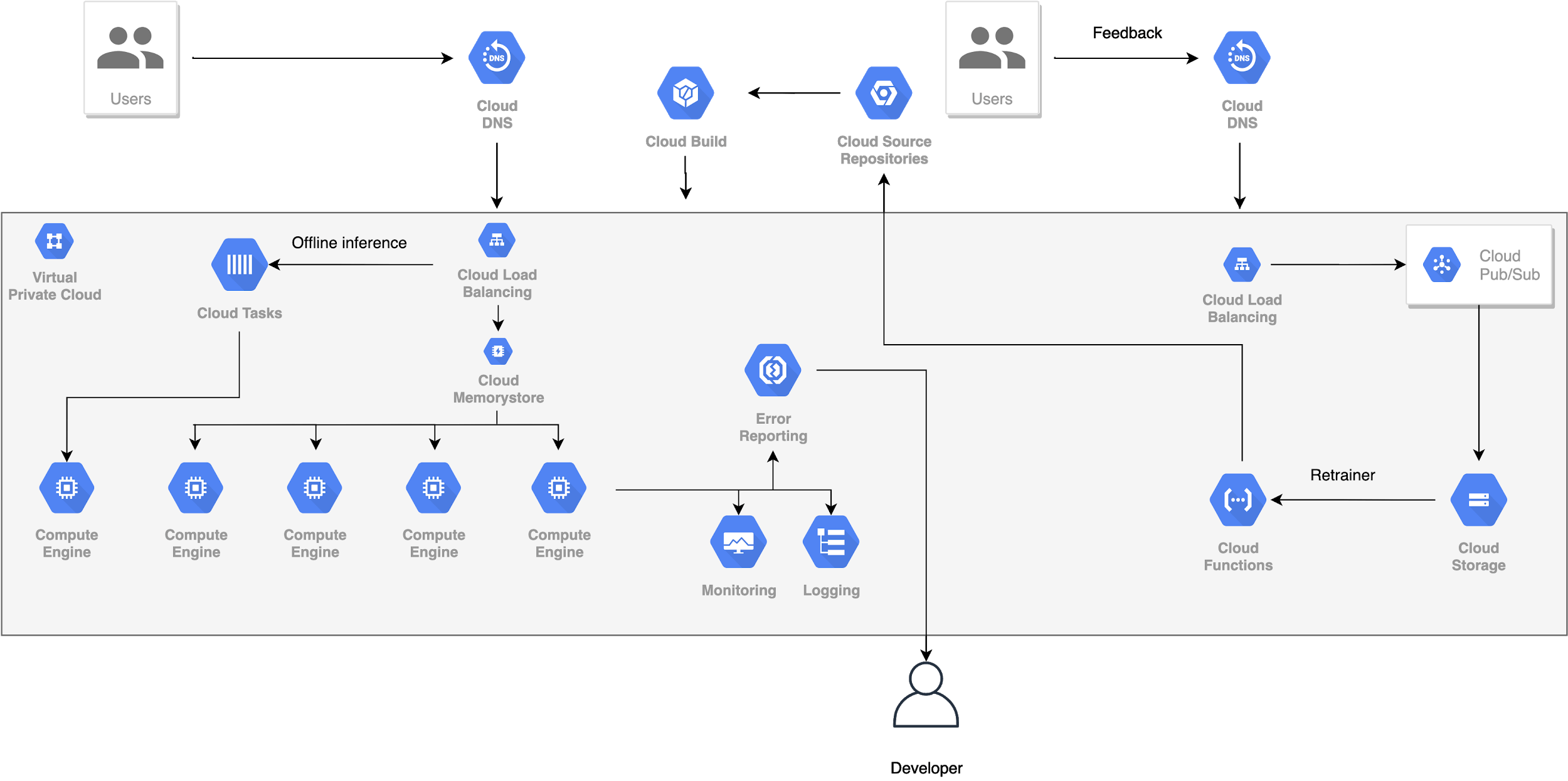
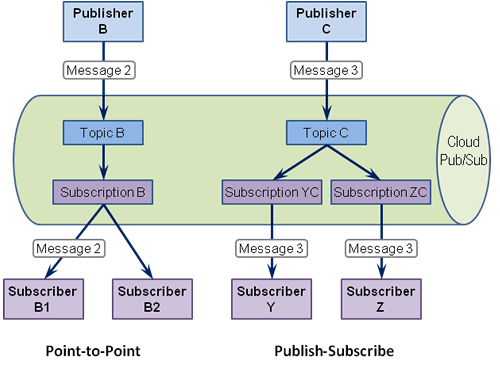
Để làm được việc này, chúng ta cần đến một kiểu dịch vụ, gọi là Message Queue. Nó là một dạng của dịch vụ không đồng bộ với giao tiếp dịch vụ. Message Queue lưu trữ các thông điệp đến từ một nhà sản xuất (Producer) và đảm bảo rằng mỗi thông báo sẽ chỉ được xử lý một lần bởi một người tiêu dùng (Consumer) duy nhất. Một Message Queue có thể có nhiều Producers và nhiều Consumers.
10. Kết luận
Như vậy là mình đã trình bày xong một cách tổng quát cách thức xây dựng kiến trúc hệ thống phần mềm có sử dụng AI model để phục vụ số lượng Users lớn. Thực tế thì tùy từng bài toán cụ thể mà các bạn có thể thay đổi, tối ưu hóa cho phù hợp với mục đích của các bạn. Hiện này, Kubernetes đang nổi là như là một xu hướng cho việc thiết kế hệ thống, bởi vì nó tập hơn gần như đầy đủ các thành phần được nhắc đến trong bài này. Mình cũng đã có 1 số bài viết về Kubernetes, các bạn có thể xem lại. Nếu có thời gian, mình sẽ viết thêm một bài về xây dựng 1 hệ thống đầy đủ như này trên GCP.
Hi vọng bài viết này mang lại những kiến thức bổ ích cho mọi người. Hẹn gặp lại các bạn trong những bài viết sau!
11. Tham khảo