Một ví dụ về hiện tượng Data Driff trong Machine Learning
Sau một thời gian nghỉ tết thì hôm nay mình đã trở lại. Trong bài viết mình sẽ cùng các bạn làm một ví dụ nhỏ về Data Driff để các bạn hiểu rõ hơn về nó. Cá nhận mình đánh giá, đây là một trong những vấn đề quan trọng nhất để giữ cho AI model chạy ổn định trong thực tế.
Hãy xem lại bài này nếu bạn chưa biết về Data Driff.
1. Ví dụ Giả sử chúng ta muốn dự đoán chất lượng của rượu tại một cửa hàng chuyên bán rượu, để quyết định xem có nên mua chai rượu đó hay không?
Chúng ta sẽ sử dụng UCI Wine Quality dataset để xây dựng một ML model dự đoán. Mỗi loại rượu có tất cả 12 features: type, fixed acidity, volatile acidity, citric acid, residual sugar, chlorides, free sulfur dioxide, total sulfur dioxide, density, pH, sulphates, và alcohol rate. Nhãn là quality score có giá trị từ 0 đến 10.
Import các thư viện sử dụng: Output:

Đọc và kiểm tra dữ liệu:
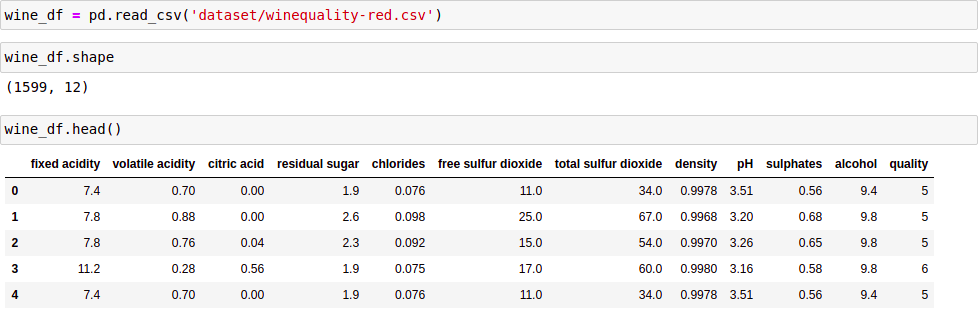
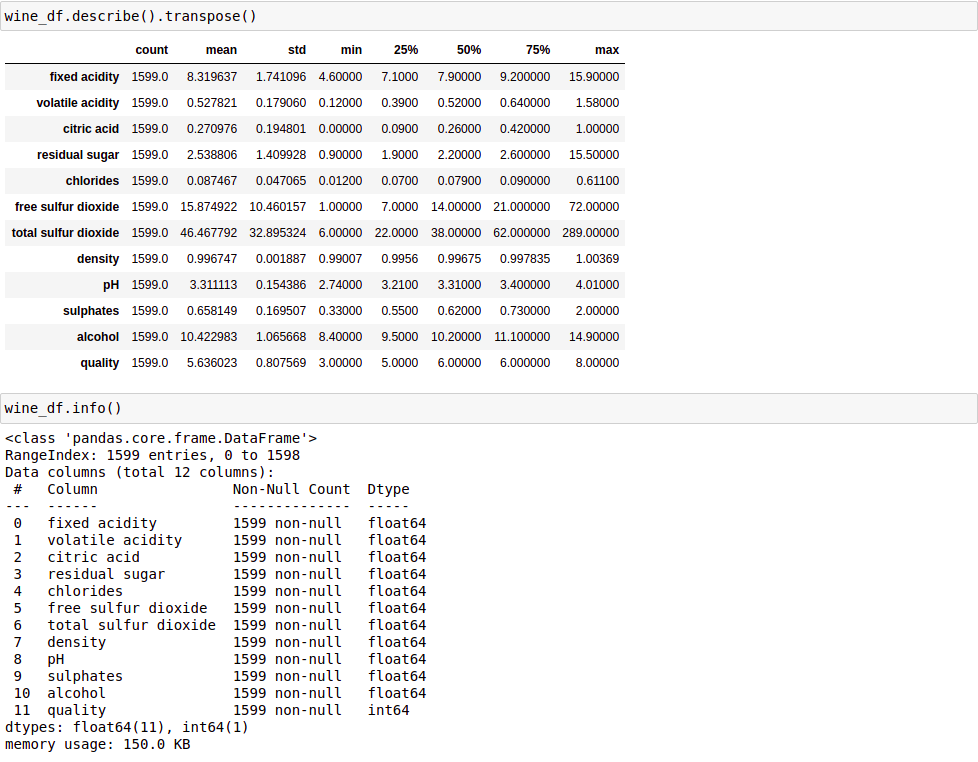
Thống kê dữ liệu:
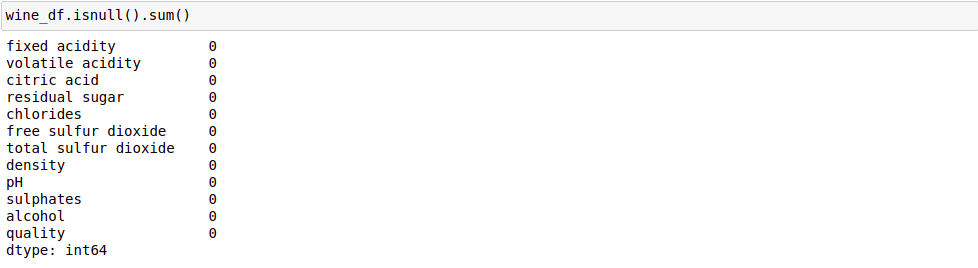
Kiểm tra xem data có chứa giá trị NULL hay không?
Kiểm tra xem dữ liệu có bị trùng lặp hay không? Nếu có thì xóa bỏ những dữ liệu bị trùng đó.

Kiểm tra sự tương quan (liên hệ) giữa các features đôi một.
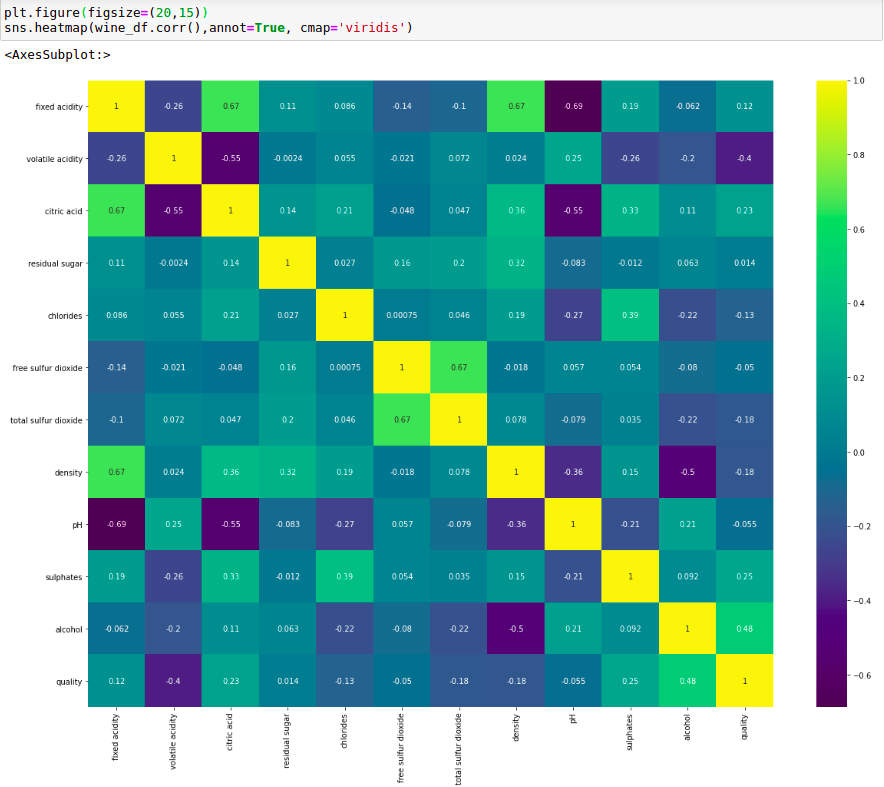
Từ đây, ta có thể loại bợt những features mà không có sự liên hệ nhiều đến nhãn (hệ số corr giữa feature đó và nhãn nhỏ).
Để đơn giản hóa model, chúng ta sẽ model hóa bài toán thành dạng binary classification. Cụ thể, rượu được coi là ngon khi quality score có giá trị lớn hơn 6 và ngược lại, rượu có quality score nhỏ hơn hoặc bằng 6 được coi là không ngon.

Kiểm tra sự phân phối dữ liệu giữa 2 nhãn.
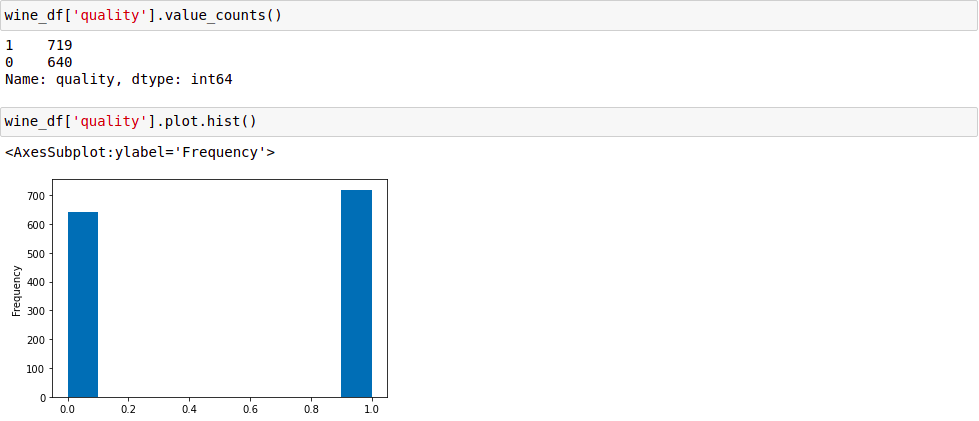
Ta có thể thấy số lượng dữ liệu phân phối khá đồng đều giữa 2 nhãn. Điều này là cần thiết để tránh việc bias dữ liệu.
Để minh họa hiện tượng Data Driff, chúng ta chia tập dữ liệu thành 2 phần:
- Phần 1, chứa tất cả rượu có giá trị của
alcohol ratelớn hơn 11%. - Phần 2, chứa tất cả rượu có giá trị của
alcohol ratenhỏ hơn hoặc bằng 11%.
Với việc phân chia như thế này, rõ ràng là dữ liệu ở phần 2 đã xảy ra hiện tượng Data Driff so với dữ liệu ở phần 1, cụ thể là ở feature alcohol.
Toàn bộ dữ liệu ở phần 1 sẽ được sử dụng để train và test model. Ở đây, mình không thực hiện việc tuning model mà chỉ xây dựng model đơn giản để minh họa ảnh hưởng của Data Driff.
Tách phần 1 thành 2 phần: features và labels. Sau đó lại chia mỗi phần đó thành 2 phần train và test theo tỉ lệ 80:20.

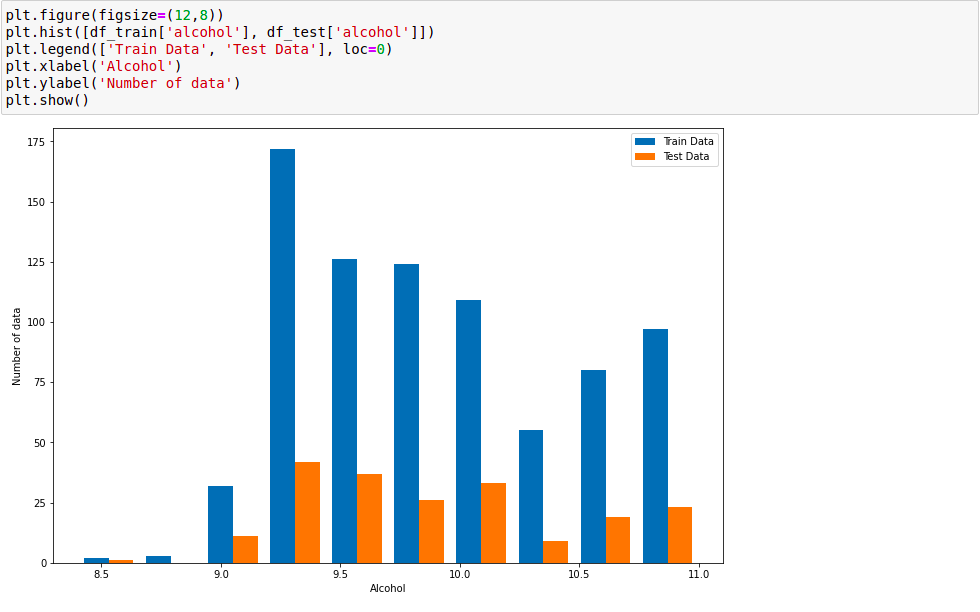
Thử kiểm tra sự phân bố dữ liệu giữa:
- Tập train và test của phần 1:
- Tập train và phần 2:
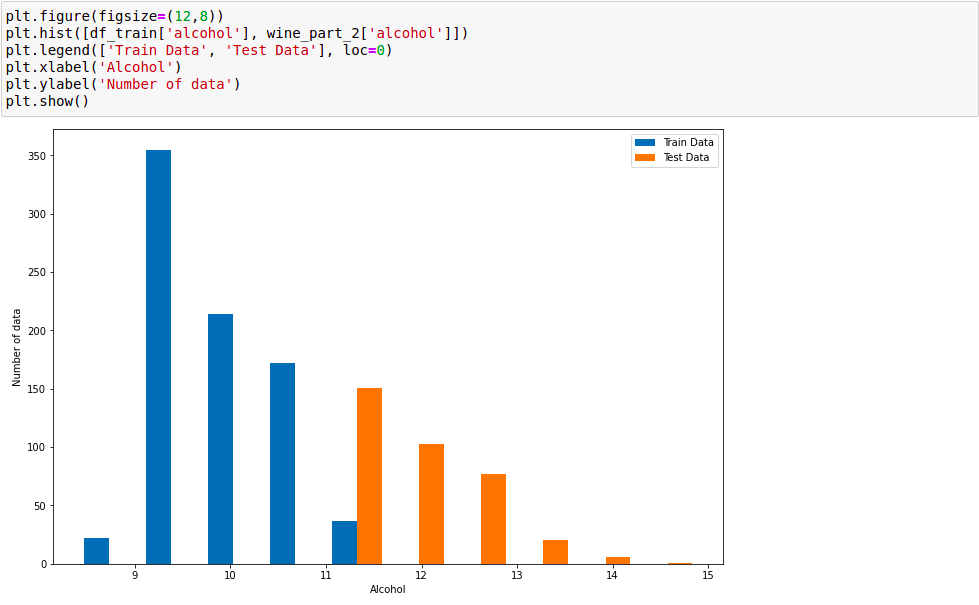
Từ đồ thị phân bố có thể quan sát rõ ràng hiện tượng Data Driff khi mà feature alcohol của tập train và phần 2 nằm về 2 phía của giá trị 11. Tập train và test của phần 1 không có hiện tượng này.
Tiến hành tạo model và huấn luyện trên tập train:

Đánh giá model trên tập test:
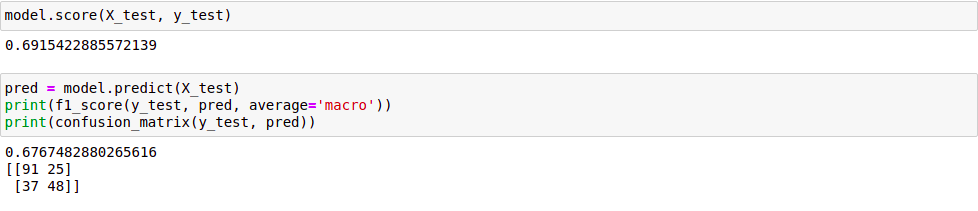
Đánh giá model trên phần 2. Chúng ta dự đoán rằng, kết quả test trên 20% của phần 1 sẽ lớn hơn trên toàn bộ phần 2, vì hiện tượng Data Driff xảy ra ở phần 2 so với phần 1.
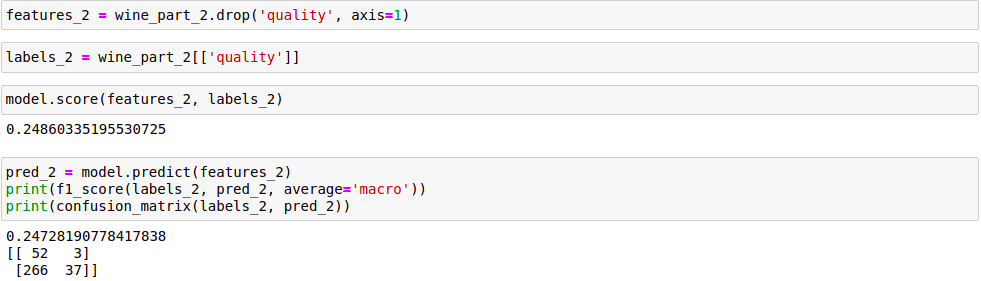
Ở đây, chúng ta sử dụng 3 metrics để đánh giá: accuracy score, f1 score và confusion matrix. Kết quả đánh giá chỉ ra, giá trị của các metrics trên phần 2 nhỏ hơn rất nhiều so với trên tập test, đúng như dự đoán ban đầu của chúng ta.
2. Kết luận
Như vậy là chúng ta đã cùng nhau làm 1 ví dụ về hiện tượng Data Driff, một trong những vấn đề rất quan trọng của quá trình triển khai AI/ML model trong thực tế. Hi vọng là các bạn có cái nhiều sâu sắc hơn về nó thông qua bài này.
Toàn bộ source code của bài này, các bạn có thể tham khảo tại github cá nhân của mình tại đây.
Hẹn các bạn trong các bài viết tiếp theo.