Tìm hiểu về Kubernetes và áp dụng vào bài toán AI - Phần 4: Kubernetes Deployment
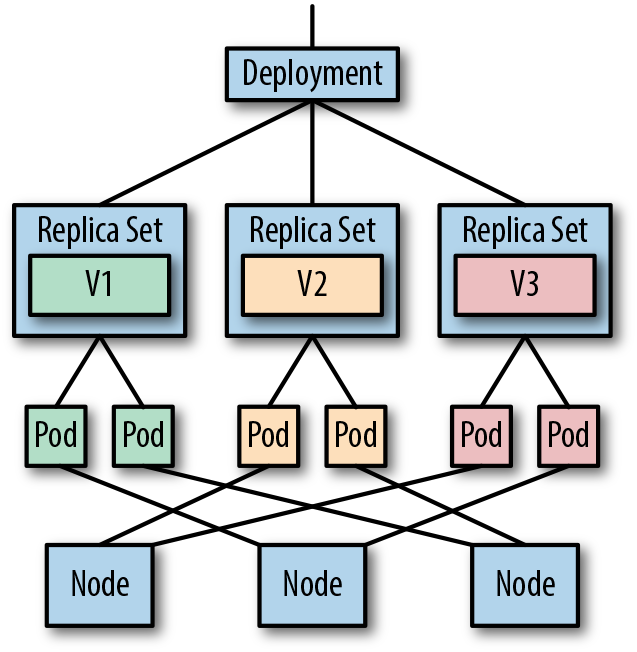
Trong bài toán AI, nếu như Job và CronJob phù hợp nhất cho các tác vụ thực hiện không liên tục, không realtime (VD: Batch Inference, Training, …) thì Deployment lại là lựa chọn tốt nhất cho các tác vụ cần chạy liên tục, realtime (VD: Online Inference, …). Trong bài này, hãy cùng tìm hiểu về Deployment và cách sử dụng nó.
1. Kubernetes Deployment là gì?
Deployment có thể hiểu là một tập các Pods giống nhau chạy trên một Kubernetes Cluster. Giống như Job, nó cũng quản lý các Pods trong việc thực hiện một nhiệm vụ nào đó. Sự khác nhau giữa Job và Deployment ở tính chất nhiệm vụ mà chúng thực hiện. Đối với Job, các tasks của nó chỉ chạy một lần, sau đó kết thúc luôn. Ngược lại, các tasks của Deployment chạy liên tục từ lúc được khởi tạo và chỉ kết thúc khi có sự can thiệp của người quản trị hoặc một ngoại lệ bất thường.
Một số đặc điểm trong cách quản lý Pod của Deployment:
- Trong quá trình làm việc, nếu một Pod bị chết, Deployment sẽ tạo ra một Pod khác thay thế.
- Deployment cũng có khả năng tự động scale up/down số lượng các Pods tùy thuộc vào mức độ nặng/nhẹ của công viêc mà nó thực hiện.
- Có thể thay đổi cấu hình của Deployment trực tiếp trong file cấu hình mà không phải downtime.
- Có thể quay lại những thay đổi trước đó trong trường hợp sự thay đổi mới gây ra lỗi.
Chính vì vậy mà Deployment rất phù hợp với nhiệm vụ Online Inference trong bài toán AI. Chúng ta train một model, tạo một REST API để lắng nghe các yêu cầu dự đoán. Sau đó, tạo ra một Deployment để chấp nhận và thực hiện các yêu cầu đó một các realtime. Nếu số lượng các yêu cầu tăng lên cao, Deployment sẽ tự động tạo thêm các Pod để xử lý và ngược lại. Nếu có một phiên bản mới của model, ta có thể dễ dàng đưa luôn vào sử dụng mà không phải downtime. Và nếu model mới đó không hiệu quả bằng model cũ, ta hoàn toàn có thể quay về sử dụng model cũ đó.
2. Làm việc với Kubernetes Deployment
Chúng ta sẽ thực hiện tạo một Deployment để phục vụ nhiệm vụ Online Inference trong bài toán AI.
Hãy xem cấu trúc thư mục làm việc:
kubernetes_deployment
│ ├── deployment
│ │ └── deployment-online-inference.yaml
│ └── docker
│ ├── api.py
│ ├── Dockerfile
│ └── train.py
2.1 Train model AI và tạo REST API
Tạo thư mục docker và hai file code python bên trong nó:
- File
train.py: Train model AI và lưu file model. - File
api.py: Tạo API để cho phép yêu cầu dự đoán gửi đến và trả về kết quả.
Nội dung của file train.py như sau:
import json
import os
from joblib import dump
import matplotlib.pyplot as plt
import numpy as np
from sklearn import ensemble
from sklearn import datasets
from sklearn.utils import shuffle
from sklearn.metrics import mean_squared_error
MODEL_DIR = os.environ["MODEL_DIR"]
MODEL_FILE = os.environ["MODEL_FILE"]
METADATA_FILE = os.environ["METADATA_FILE"]
MODEL_PATH = os.path.join(MODEL_DIR, MODEL_FILE)
METADATA_PATH = os.path.join(MODEL_DIR, METADATA_FILE)
# #############################################################################
# Load data
print("Loading data...")
boston = datasets.load_boston()
print("Splitting data...")
X, y = shuffle(boston.data, boston.target, random_state=13)
X = X.astype(np.float32)
offset = int(X.shape[0] * 0.9)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
# #############################################################################
# Fit regression model
print("Fitting model...")
params = {'n_estimators': 500, 'max_depth': 4, 'min_samples_split': 2,
'learning_rate': 0.01, 'loss': 'ls'}
clf = ensemble.GradientBoostingRegressor(**params)
clf.fit(X_train, y_train)
train_mse = mean_squared_error(y_train, clf.predict(X_train))
test_mse = mean_squared_error(y_test, clf.predict(X_test))
metadata = {
"train_mean_square_error": train_mse,
"test_mean_square_error": test_mse
}
print("Serializing model to: {}".format(MODEL_PATH))
dump(clf, MODEL_PATH)
print("Serializing metadata to: {}".format(METADATA_PATH))
with open(METADATA_PATH, 'w') as outfile:
json.dump(metadata, outfile)
Nội dung của file api.py như sau:
import os
from flask import Flask
from flask_restful import Resource, Api, reqparse
from joblib import load
import numpy as np
MODEL_DIR = os.environ["MODEL_DIR"]
MODEL_FILE = os.environ["MODEL_FILE"]
METADATA_FILE = os.environ["METADATA_FILE"]
MODEL_PATH = os.path.join(MODEL_DIR, MODEL_FILE)
METADATA_PATH = os.path.join(MODEL_DIR, METADATA_FILE)
print("Loading model from: {}".format(MODEL_PATH))
clf = load(MODEL_PATH)
app = Flask(__name__)
api = Api(app)
class Prediction(Resource):
def __init__(self):
self._required_features = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM',
'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B',
'LSTAT']
self.reqparse = reqparse.RequestParser()
for feature in self._required_features:
self.reqparse.add_argument(
feature, type = float, required = True, location = 'json',
help = 'No {} provided'.format(feature))
super(Prediction, self).__init__()
def post(self):
args = self.reqparse.parse_args()
X = np.array([args[f] for f in self._required_features]).reshape(1, -1)
y_pred = clf.predict(X)
return {'prediction': y_pred.tolist()[0]}
api.add_resource(Prediction, '/predict')
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0')
Code của 2 files này khá đơn giản nên mình không giải thích gì thêm, hi vọng các bạn có thể tự hiểu được.
2.2 Chuẩn bị Docker Image
Cũng trong thư mục docker, ta file Dockerfile như sau:
FROM jupyter/scipy-notebook
USER root
WORKDIR /docker
ADD . /docker
RUN pip install flask flask-restful joblib
RUN mkdir /docker/model
ENV MODEL_DIR=/docker/model
ENV MODEL_FILE=clf.joblib
ENV METADATA_FILE=metadata.json
RUN python3 train.py
Sau đó tiến hành build Docker Image:
$ docker build -t docker-ml-online .
Sending build context to Docker daemon 6.656kB
Step 1/10 : FROM jupyter/scipy-notebook
---> c1a7c7ef5e27
Step 2/10 : USER root
---> Using cache
---> 0d9f55e9c7e0
Step 3/10 : WORKDIR /docker
---> Using cache
---> 4ed21d81d110
Step 4/10 : ADD . /docker
---> a266bfc5ca35
Step 5/10 : RUN pip install flask flask-restful joblib
---> Running in 97888ed0b989
Collecting flask
Downloading Flask-1.1.2-py2.py3-none-any.whl (94 kB)
Collecting flask-restful
Downloading Flask_RESTful-0.3.8-py2.py3-none-any.whl (25 kB)
Requirement already satisfied: joblib in /opt/conda/lib/python3.8/site-packages (1.0.0)
Requirement already satisfied: click>=5.1 in /opt/conda/lib/python3.8/site-packages (from flask) (7.1.2)
Collecting Werkzeug>=0.15
Downloading Werkzeug-1.0.1-py2.py3-none-any.whl (298 kB)
Requirement already satisfied: Jinja2>=2.10.1 in /opt/conda/lib/python3.8/site-packages (from flask) (2.11.2)
Collecting itsdangerous>=0.24
Downloading itsdangerous-1.1.0-py2.py3-none-any.whl (16 kB)
Requirement already satisfied: MarkupSafe>=0.23 in /opt/conda/lib/python3.8/site-packages (from Jinja2>=2.10.1->flask) (1.1.1)
Requirement already satisfied: six>=1.3.0 in /opt/conda/lib/python3.8/site-packages (from flask-restful) (1.15.0)
Requirement already satisfied: pytz in /opt/conda/lib/python3.8/site-packages (from flask-restful) (2020.5)
Collecting aniso8601>=0.82
Downloading aniso8601-8.1.1-py2.py3-none-any.whl (44 kB)
Installing collected packages: Werkzeug, itsdangerous, flask, aniso8601, flask-restful
Successfully installed Werkzeug-1.0.1 aniso8601-8.1.1 flask-1.1.2 flask-restful-0.3.8 itsdangerous-1.1.0
Removing intermediate container 97888ed0b989
---> d9f31d7e7c83
Step 6/10 : RUN mkdir /docker/model
---> Running in 89b237f6427c
Removing intermediate container 89b237f6427c
---> b2778ed90f4a
Step 7/10 : ENV MODEL_DIR=/docker/model
---> Running in d7a52c9249f9
Removing intermediate container d7a52c9249f9
---> 5157d919abd5
Step 8/10 : ENV MODEL_FILE=clf.joblib
---> Running in a7f75c6f79e5
Removing intermediate container a7f75c6f79e5
---> 790a21e54588
Step 9/10 : ENV METADATA_FILE=metadata.json
---> Running in b0b94567182c
Removing intermediate container b0b94567182c
---> 92a98ce95a8d
Step 10/10 : RUN python3 train.py
---> Running in d8055e4ef00d
Loading data...
Splitting data...
Fitting model...
Serializing model to: /docker/model/clf.joblib
Serializing metadata to: /docker/model/metadata.json
Removing intermediate container d8055e4ef00d
---> b1fb95b775ec
Successfully built b1fb95b775ec
Successfully tagged docker-ml-online:latest
Có Docker Image rồi, tiến hành push nó lên Docker Hub:
$ docker push tiensu/ml-model-online-infer:latest
The push refers to repository [docker.io/tiensu/ml-model-online-infer]
f0e40a44cb9c: Pushed
a079ef4fd38e: Pushed
76cba4a3a958: Pushed
3451a539eae2: Pushed
66f4cc63b50c: Mounted from tiensu/docker-ml
5f70bf18a086: Mounted from tiensu/docker-ml
6f5a41ae77fd: Mounted from tiensu/docker-ml
5a1b9a3f9355: Mounted from tiensu/docker-ml
b1d7816bac14: Mounted from tiensu/docker-ml
c91fed2d1998: Mounted from tiensu/docker-ml
cc70098d00e3: Mounted from tiensu/docker-ml
88727e93cbac: Mounted from tiensu/docker-ml
cadaf24035f3: Mounted from tiensu/docker-ml
8f170f4774e3: Mounted from tiensu/docker-ml
33bd52db887f: Mounted from tiensu/docker-ml
21e5dd010f50: Mounted from tiensu/docker-ml
ea370ab22368: Mounted from tiensu/docker-ml
421d1408f872: Mounted from tiensu/docker-ml
18fd1ca0de51: Mounted from tiensu/docker-ml
8f01aab6d756: Mounted from tiensu/docker-ml
e18a1c4e1d31: Mounted from tiensu/docker-ml
8552f27c3cd8: Mounted from tiensu/docker-ml
1a4c57efcc23: Mounted from tiensu/docker-ml
94b8fe888eac: Mounted from tiensu/docker-ml
02473afd360b: Mounted from tiensu/docker-ml
dbf2c0f42a39: Mounted from tiensu/docker-ml
9f32931c9d28: Mounted from tiensu/docker-ml
latest: digest: sha256:67c219ed32f9748c0c3ce64e8c4274932a8dadaf05510402f5d64a038bca2165 size: 6790
2.3 Tạo Kubernetes Deployment
Trong thư mục deployment, tạo file cấu hình (deployment-online-inference.yaml) của Deployment với nội dung như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
name: online-inference-deployment
spec:
replicas: 2
selector:
matchLabels:
app: model-api
template:
metadata:
labels:
app: model-api
spec:
containers:
- name: model-api
imagePullPolicy: Always
image: tiensu/ml-model-online-infer:latest
command: ["python3", "api.py"]
ports:
- containerPort: 5000
Một số thông tin cần lưu ý ở đây:
- replicas: Số lượng Pods được tạo ra lúc ban đầu.
- selector: Định nghĩa tên của Pods/Containers mà nó quản lý.
Chạy các lệnh sau để tạo và kiểm tra Deployment:
$ kubectl create -f deployment-online-inference.yaml
deployment.apps/online-inference-deployment created
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
online-inference-deployment 2/2 2 2 41s
Thực ra, Deployment không trực tiếp quản lý các Pods. Thay vào đó, nó sẽ tạo ra các ReplicaSet với mục đích duy trì sự ổn định của các Pods tại bất kì thời điểm nào trong suốt quá trình hoạt động.
Kiểm tra ReplicaSet được Deployment tạo ra:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
online-inference-deployment-59c8579f48 2 2 2 68s
Chú ý: Tên của ReplicaSet = Tên của Deployment + chuỗi ngẫu nhiên.
Kiểm tra thử các Pods được quản lý bởi online-inference-deployment-59c8579f48 ReplicaSet:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
online-inference-deployment-59c8579f48-bg2vj 1/1 Running 0 97s
online-inference-deployment-59c8579f48-j9fl2 1/1 Running 0 97s
Chú ý: Tên của Pod = Tên của ReplicaSet + chuỗi ngẫu nhiên.
Thử debug một Pod xem có gì bất thường không?
$ kubectl describe pod online-inference-deployment-59c8579f48-bg2vj
Name: online-inference-deployment-59c8579f48-bg2vj
Namespace: default
Priority: 0
Node: duynm-vostro-3670/10.1.30.130
Start Time: Mon, 01 Feb 2021 18:15:27 +0700
Labels: app=model-api
pod-template-hash=59c8579f48
Annotations: cni.projectcalico.org/podIP: 192.168.24.197/32
cni.projectcalico.org/podIPs: 192.168.24.197/32
Status: Running
IP: 192.168.24.197
IPs:
IP: 192.168.24.197
Controlled By: ReplicaSet/online-inference-deployment-59c8579f48
Containers:
model-api:
Container ID: docker://4cde562c962b48ff4c6bc3c812b140d2555e1984f064108bd8bf607b122cef9a
Image: tiensu/ml-model-online-infer
Image ID: docker-pullable://tiensu/ml-model-online-infer@sha256:67c219ed32f9748c0c3ce64e8c4274932a8dadaf05510402f5d64a038bca2165
Port: 5000/TCP
Host Port: 0/TCP
Command:
python3
api.py
State: Running
Started: Mon, 01 Feb 2021 18:15:45 +0700
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-wp4xr (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-wp4xr:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-wp4xr
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m25s default-scheduler Successfully assigned default/online-inference-deployment-59c8579f48-bg2vj to duynm-vostro-3670
Normal Pulling 2m22s kubelet Pulling image "tiensu/ml-model-online-infer"
Normal Pulled 2m8s kubelet Successfully pulled image "tiensu/ml-model-online-infer" in 14.038005704s
Normal Created 2m7s kubelet Created container model-api
Normal Started 2m7s kubelet Started container model-api
OK, mọi thứ đều đang hoạt động đúng như mong muốn.
Ta cũng có thể xem logs của Pod khi chạy:
$ kubectl logs -f online-inference-development-5d46c5c7dc-bg2vj
Loading model from: /docker/model/clf.joblib
* Serving Flask app "api" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 263-920-719
10.1.30.130 - - [02/Feb/2021 11:06:49] "POST /predict HTTP/1.1" 200 -
Tham số -f dùng để xem log một các realtime.
2.4 Chạy Online Inference
Bây giờ ta sẽ thử gửi một yêu cầu dự đoán thông qua REST API để xem kết quả trả về. Tuy nhiên, có một chú ý quan trọng là REST API này chỉ mới hoạt động được bên trong phạm vi của Kubernetes Cluster. Để mở rộng nó ra ngoài Internet, chúng ta cần phải sử dụng thêm Service. Service sẽ được trình bày trong bài viết tiếp theo.
Chúng ta sẽ thực hiện Online Inference từ một Pod trong cùng Cluster với Deployment. Sử dụng lệnh sau để chạy và truy cập vào Pod python3:
$ kubectl run python3 -ti --image=python:3.6 --command=true bash
If you don't see a command prompt, try pressing enter.
root@python3:/#
Phần xử lý Inference bây giờ đang nằm trên 2 Pods mà Deployment tạo ra. Ta sẽ gửi yêu cầu dự đoán đến chúng. Xem lại phần debug bên trên của Pod online-inference-deployment-59c8579f48-bg2vj ta thấy Internal IP của nó là 192.168.24.197
Từ trong Pod python3, thực hiện lệnh sau để gửi yêu cầu dự đoán:
$ curl -i -H "Content-Type: application/json" -X POST -d '{"CRIM": 15.02, "ZN": 0.0, "INDUS": 18.1, "CHAS": 0.0, "NOX": 0.614, "RM": 5.3, "AGE": 97.3, "DIS": 2.1, "RAD": 24.0, "TAX": 666.0, "PTRATIO": 20.2, "B": 349.48, "LSTAT": 24.9}' 192.168.24.197:5000/predict
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 41
Server: Werkzeug/1.0.1 Python/3.8.6
Date: Mon, 01 Feb 2021 11:22:25 GMT
{
"prediction": 12.273424794987877
}
Như vậy là ta đã nhận được kết quả dự đoán trả về, chứng tỏ Deployment của chúng ta đã hoạt động đúng như ta dự tính.
2.5 Xóa Deployment khi không sử dụng
Nếu không sử dụng nữa, ta thực hiện lệnh sau để xóa Deployment và các tài nguyên của nó:
$ kubectl delete deployment online-inference-development
deployment.apps "online-inference-development" deleted
Kiểm tra lại:
$ kubectl get rs
No resources found.
$ kubectl get pods
No resources found.
3. Kết luận
Xong, chúng ta đã thực hành thành công với Deployment, và ta cũng biết một thiếu sót của Deployment phải cần đến Service để giải quyết. Đó chính là nội dung của bài tiếp theo. Mời các bạn đón đọc!
Source code của bài này các bạn tham khảo tại đây.
8. Tham khảo