Sử dụng kỹ thuật Data Augmentation và Model Checkpoint khi huấn luyện CNN model

Tiếp theo bài trước, trong bài này chúng ta sẽ áp dụng thêm 2 kỹ thuật mới vào CNN model Cat&Dog classification:
-
Data Augmentation: Đây là kỹ thuật tăng cường dữ liệu huấn luyện cho model. Nó đặc biệt hữu ích khi chúng ta có ít dữ liệu vì từ một ảnh gốc ban đầu, thông qua các phép biến đổi hình thái học (xoay, lật, phóng to, thu nhỏ, thay đổi độ sáng, độ tương phải, …) ta có thêm được nhiều ảnh mới. Kỹ thuật này không chỉ giới hạn trong các bài toán liên quan đến ảnh, mà các bài toán Data Science và NLP cũng có thể sử dụng được.
-
Model Checkpoint: Đây thực chất là một hàm callback, được gọi sau mỗi epoch trong quá trình huấn luyện model. Nó sẽ lưu lại model nếu giá trị loss hoặc accuracy được cải thiện sau mỗi epoch.
Cùng với EarlyStopping thì 2 kỹ thuật này được cũng được sử dụng rất thường xuyên để hạn chế hiện tượng overfitting của model.
Bây giờ, ta sẽ sử dụng chúng trong bài toán xây dựng CNN model phân loại Cat&Dog.
Import thư viện:
import os
import random
import tensorflow as tf
import shutil
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.preprocessing.image import ImageDataGenerator
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.compat.v1.InteractiveSession(config=config)
Hai kỹ thuật Data augmentation và Model checkpoint sẽ được sử dụng thông qua lớp ImageDataGenerator và ModelCheckpoint, tương ứng.
Lớp ImageDataGenerator cho phép ta biến đổi ảnh gốc thành nhiều ảnh khác nhau thông quá các tham số truyền vào. Như trong hàm gen_data() dưới đây, ta sinh ra được 6 ảnh mới thông qua các phép biến đổi:
- Quay 40 độ
- Dịch theo chiều rộng 0.2 pixcel
- Dịch theo chiều cao 0.2 pixcel
- Cắt (xén) 0.2 pixcel
- Phóng to 0.2 pixcel
- Lật ngang
Chú ý rằng, các ảnh mới sinh ra không được lưu vào ổ cứng máy tính, mà chỉ được sinh ra tại thời điểm huấn luyện model và lưu tạm thời trong RAM. Khi kết thức quá trình training thì các ảnh đó cũng sẽ mất.
Tham số fill_mode='nearest' chỉ ra phương pháp bù lại giá trị cho những pixcel tại các vị trí bị mất mát do quá trình biến đổi. Nearest tức là dựa vào giá trị của các pixcel xung quanh, gần nó nhất (theo một tiêu chuẩn nào đó).
def gen_data():
training_datagen = ImageDataGenerator(
rescale=1/255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
validation_datagen = ImageDataGenerator(
rescale=1/255
)
training_generator = training_datagen.flow_from_directory(
'cat-dog-dataset/train',
target_size=(150, 150),
batch_size=32,
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
'cat-dog-dataset/val',
target_size=(150, 150),
batch_size=32,
class_mode='binary'
)
return training_generator, validation_generator
Tiếp theo, ta khai báo một instance của ModelCheckpoint:
callback_1 = ModelCheckpoint(
'cat_dog_model_checkpoint/weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5', # Tên model tại mỗi điểm checkpoint
monitor='val_acc', # Giá trị cần theo dõi
save_best_only=True, # Chỉ lưu những model tốt nhất đến thời điểm checkpoint
save_weights_only=True, # Chỉ lưu weights của model (để giảm kích thước)
save_freq='epoch', # Checkpoint sau mỗi epoch
mode='auto', # Val_acc phải tăng mới tính là model được cải thiện. Nếu monitor='loss/val_loss' thì nó phải giảm mới tính là model được cải thiện
verbose=1 # Hiển thị thông tin model lúc checkpoint
)
Chi tiết từng tham số của ModelCheckpoint instance được giải thích chi tiết theo các comments trong code khai báo.
Ta vẫn sử dụng thêm EarlyStopping để tiết kiệm thời gian training:
callback_2 = EarlyStopping(monitor='val_acc', patience=5)
Kiến trúc CNN model vẫn giữ nguyên như bài trước:
def create_model():
model = keras.models.Sequential([
keras.layers.Conv2D(128, (3,3), activation='relu', input_shape=(150, 150, 3)),
keras.layers.MaxPooling2D(2,2),
keras.layers.Conv2D(64, (3,3), activation='relu'),
keras.layers.MaxPooling2D(2,2),
keras.layers.Conv2D(32, (3,3), activation='relu'),
keras.layers.MaxPooling2D(2,2),
keras.layers.Flatten(),
keras.layers.Dense(256, activation='relu'),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['acc'])
return model
Hàm plot_chart để thể hiện kết quả training lên đồ thị:
def plot_chart(history):
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.figure(figsize=(10, 6))
plt.plot(epochs, acc, 'r', label='Training Accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation Accuracy')
plt.plot(epochs, loss, 'g', label='Training Loss')
plt.plot(epochs, val_loss, 'y', label='Validation Loss')
plt.title('Traing and Validation, Accuracy and Loss')
plt.legend(loc=0)
plt.show()
Cuối cùng, gộp tất cả lại và train model:
training_generator, validation_generator = gen_data()
model = create_model()
history = model.fit(
training_generator,
epochs=30,
validation_data=validation_generator,
callbacks=[callback_1, callback_2],
verbose=1
)
Output:
Found 20000 images belonging to 2 classes.
Found 5000 images belonging to 2 classes.
Epoch 1/30
2/625 [..............................] - ETA: 17s - loss: 1.6500 - acc: 0.5469WARNING:tensorflow:Callbacks method `on_train_batch_end` is slow compared to the batch time (batch time: 0.0223s vs `on_train_batch_end` time: 0.0339s). Check your callbacks.
625/625 [==============================] - ETA: 0s - loss: 0.6804 - acc: 0.5882
Epoch 00001: val_acc improved from -inf to 0.69340, saving model to horse-humand_model_checkpoint/weights-improvement-01-0.69.hdf5
625/625 [==============================] - 115s 184ms/step - loss: 0.6804 - acc: 0.5882 - val_loss: 0.6017 - val_acc: 0.6934
Epoch 2/30
625/625 [==============================] - ETA: 0s - loss: 0.6239 - acc: 0.6591
Epoch 00002: val_acc improved from 0.69340 to 0.73060, saving model to horse-humand_model_checkpoint/weights-improvement-02-0.73.hdf5
625/625 [==============================] - 112s 179ms/step - loss: 0.6239 - acc: 0.6591 - val_loss: 0.5446 - val_acc: 0.7306
Epoch 3/30
625/625 [==============================] - ETA: 0s - loss: 0.5922 - acc: 0.6922
Epoch 00003: val_acc improved from 0.73060 to 0.76340, saving model to horse-humand_model_checkpoint/weights-improvement-03-0.76.hdf5
625/625 [==============================] - 113s 181ms/step - loss: 0.5922 - acc: 0.6922 - val_loss: 0.5106 - val_acc: 0.7634
............
Epoch 30/30
625/625 [==============================] - ETA: 0s - loss: 0.4392 - acc: 0.8173
Epoch 00030: val_acc did not improve from 0.86600
625/625 [==============================] - 112s 179ms/step - loss: 0.4392 - acc: 0.8173 - val_loss: 0.4723 - val_acc: 0.7768
Model được train đầy đủ 30 epochs, không bị dừng giữa chừng do không thỏa mãn điều kiện của EarlyStopping.
Quan sát thư mục cat_dog_model_checkpoint ta cũng thấy model được lưu tại một số điểm checkpoint. Model có độ chính xác cao nhất tại epoch thứ 29.
├── weights-improvement-01-0.69.hdf5
├── weights-improvement-01-0.98.hdf5
├── weights-improvement-02-0.73.hdf5
├── weights-improvement-02-1.00.hdf5
├── weights-improvement-03-0.76.hdf5
├── weights-improvement-05-0.80.hdf5
├── weights-improvement-07-0.81.hdf5
├── weights-improvement-10-0.83.hdf5
├── weights-improvement-12-0.83.hdf5
├── weights-improvement-17-0.83.hdf5
├── weights-improvement-20-0.85.hdf5
├── weights-improvement-24-0.86.hdf5
└── weights-improvement-29-0.87.hdf5
Kiểm tra quá trình huấn luyện bằng cách thể hiện giá trị loss và accuracy lên đồ thị:
plot_chart(history)
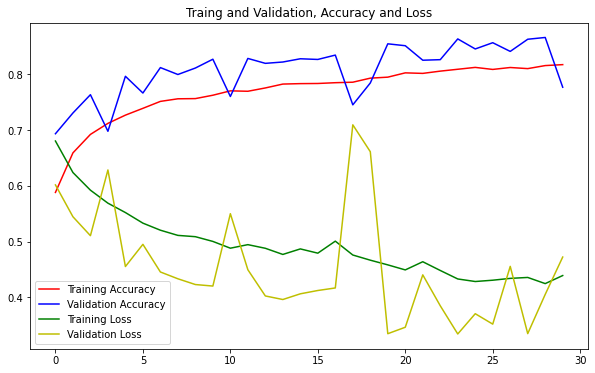
Các giá trị loss và accuracy tuy có sự dao động nhưng kết quả cuối cùng vẫn khá tốt. Model không bị overfit quá nhiều, có thể chấp nhận được.
Source code của bài này, các bạn có thể tham khảo trên github cá nhân của mình tại đây.
Bài tiếp theo, ta sẽ học thêm một kỹ thuật rất thú vị nữa, giúp chúng ta giảm rất nhiều công sức trong việc huấn luyện model, đó là Tranfer Learning. Mời các bạn đón đọc!
Tham khảo