Sử dụng kỹ thuật EarlyStopping khi huấn luyện CNN model

Nếu như bài trước, toàn bộ dữ liệu được đưa vào training, thì bài này, ta sẽ chia tập dữ liệu thành 2 phần:
- Train set: Dùng để huấn luyện model.
- Validation set: Dùng đễ đánh giá model trong suốt quá trình training.
OK, hãy bắt đầu!
Trước tiên, download bộ dataset cat-and-dog và giải nén về máy tính của bạn tại thư mục làm việc. Ta chỉ cần download file train.zip.
Bộ dataset này bao gồm 25.000 bức ảnh, chia thành 2 lớp chó và mèo. Mỗi lớp có 12.500 ảnh, kích thước 150x150.
Ta tiếp tục sử dụng lớp ImageDataGenerator để chuẩn bị dữ liệu cho training model. Lớp ImageDataGenerator yêu cầu cấu trúc thư mục dataset có dạng như sau:
- training
- class 1
- image 1
- image 2
- ...
- class 2
- image 3
- image 4
- ...
- ...
- validation
- class 1
- image 5
- image 6
- ...
- class 2
- image 7
- image 8
Để chuẩn hóa cấu trúc thư mục như yêu cầu, ta có thể tự viết code để copy các ảnh vào đúng thư mục mong muốn. Hoặc có 1 cách đơn giản hơn là sử dụng thư viện split-folders.
Cài đặt thư viện:
pip install split-folders
Sử dụng lệnh sau để tạo dữ liệu theo cấu trúc mong muốn:
splitfolders cats-and-dogs --ratio .8 .2 --output cat-dog-dataset
Ta được thư mục output cat-dog-dataset:
cat-dog-dataset
├── train
│ ├── cats
│ └── dogs
└── val
├── cats
└── dogs
Có dữ liệu chuẩn chỉ rồi, giờ ta sẽ bắt tay vào viết code để train model.
Đầu tiên, như thường lệ vẫn là import các thư viện sử dụng:
import os
import random
import tensorflow as tf
import shutil
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.preprocessing.image import ImageDataGenerator
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.compat.v1.InteractiveSession(config=config)
Ở đây, ngoài các thư viện, các lớp quen thuộc, ta có sử dụng thêm hàm EarlyStopping của lớp callback. Hàm này cho phép model dừng training khi nó thoả mãn một tiêu chí về độ chính xác mà người dùng có thể định nghĩa được. So với hàm callback tự viết như trong các bài trước thì việc sử dụng EarlyStopping linh động hơn rất nhiều. Ta sẽ đi chi tiết ở phần sau.
Tiếp theo, ta sử dụng lớp ImageDataGenerator để chuẩn bị dữ liệu cho việc huấn luyện model.
def gen_data():
training_datagen = ImageDataGenerator(
rescale=1/255
)
validation_datagen = ImageDataGenerator(
rescale=1/255
)
training_generator = training_datagen.flow_from_directory(
'cat-dog-dataset/train',
target_size=(150, 150),
batch_size=32,
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
'cat-dog-dataset/val',
target_size=(150, 150),
batch_size=32,
class_mode='binary'
)
return training_generator, validation_generator
Vì dataset đã được chia thành 2 phần, train set và validation set, nên ở đây ta cũng có 2 instances của lớp ImageDataGenerator tương ứng. Một cái dành cho train model, 1 cái dành cho validate model. Hai instances này chỉ khác nhau đường dẫn đến nơi chứa data, còn lại các thông số khác đều giống nhau. Cần lưu ý đến giá trị của tham số batch_size, vì lần này chúng ta sử dụng dữ liệu thật nên nếu bạn set giá trị của nó cao quá có thể dẫn đến hiện tượng out of memory. Thực tế, ban đầu mình set batch_size=64 nhưng bị lỗi nên phải giảm xuống còn 32.
CNN model được tạo ra giống như bài trước:
def create_model():
model = keras.models.Sequential([
keras.layers.Conv2D(128, (3,3), activation='relu', input_shape=(150, 150, 3)),
keras.layers.MaxPooling2D(2,2),
keras.layers.Conv2D(64, (3,3), activation='relu'),
keras.layers.MaxPooling2D(2,2),
keras.layers.Conv2D(32, (3,3), activation='relu'),
keras.layers.MaxPooling2D(2,2),
keras.layers.Flatten(),
keras.layers.Dense(256, activation='relu'),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['acc'])
return model
Optimizer vẫn là RMSprop nhưng được learning_rate được khởi tạo với giá trị 0.001 thay vì sử dụng giá trị mặc đinh. Loss Function là binary_crossentroy vì có 2 classes cần phân biệt.
Ta định nghĩa thêm hàm plot_chart để thể hiện kết quả training lên đồ thị:
def plot_chart(history):
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.figure(figsize=(10, 6))
plt.plot(epochs, acc, 'r', label='Training Accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation Accuracy')
plt.plot(epochs, loss, 'g', label='Training Loss')
plt.plot(epochs, val_loss, 'y', label='Validation Loss')
plt.title('Traing and Validation, Accuracy and Loss')
plt.legend(loc=0)
plt.show()
Bên trên ta đã nói về hàm callback sử dụng EarlyStopping. Ta định nghĩa nó như sau:
callback = EarlyStopping(monitor='loss', patience=5)
Mục đích của hàm này là buộc model dừng quá trình training nếu sau 5 epochs liên tiếp mà giá trị của loss không giảm. Bạn cũng có thể thay loss bằng acc, khi đó, model sẽ dừng training nếu giá trị accuracy không tăng sau 5 epochs liên tiếp.
Gộp tất cả lại và train model:
training_generator, validation_generator = gen_data()
model = create_model()
history = model.fit(
training_generator,
epochs=30,
validation_data=validation_generator,
callbacks=[callback],
verbose=1
)
Dòng `validation_data=validation_generator` trong hàm fit chỉ ra dữ liệu được dùng để validate model trong suốt quá trình training.
Output:
```python
Found 20000 images belonging to 2 classes.
Found 5000 images belonging to 2 classes.
Epoch 1/30
1/625 [..............................] - ETA: 0s - loss: 0.6942 - acc: 0.5000WARNING:tensorflow:Callbacks method `on_train_batch_end` is slow compared to the batch time (batch time: 0.0141s vs `on_train_batch_end` time: 0.0326s). Check your callbacks.
625/625 [==============================] - 116s 186ms/step - loss: 0.6851 - acc: 0.5663 - val_loss: 0.6292 - val_acc: 0.6240
Epoch 2/30
625/625 [==============================] - 121s 194ms/step - loss: 0.6250 - acc: 0.6571 - val_loss: 0.5594 - val_acc: 0.7356
Epoch 3/30
625/625 [==============================] - 117s 188ms/step - loss: 0.5928 - acc: 0.6921 - val_loss: 0.5248 - val_acc: 0.7652
...
Epoch 14/30
625/625 [==============================] - 124s 198ms/step - loss: 0.4828 - acc: 0.7799 - val_loss: 0.4186 - val_acc: 0.8050
Epoch 15/30
625/625 [==============================] - 123s 197ms/step - loss: 0.4877 - acc: 0.7753 - val_loss: 0.5091 - val_acc: 0.7568
Epoch 16/30
625/625 [==============================] - 124s 198ms/step - loss: 0.4787 - acc: 0.7796 - val_loss: 0.5068 - val_acc: 0.8126
Epoch 17/30
625/625 [==============================] - 124s 198ms/step - loss: 0.4844 - acc: 0.7826 - val_loss: 0.3928 - val_acc: 0.8374
Epoch 18/30
625/625 [==============================] - 124s 198ms/step - loss: 0.4876 - acc: 0.7832 - val_loss: 0.4588 - val_acc: 0.8388
Ta thấy rằng quá trình training model dừng lại tại epoch thứ 18, vì từ epoch 13 đến epoch 18, giá trị của loss không giảm đi chút nào, thậm chí còn tăng lên.
Thử vẽ đồ thị loss và accurcy:
plot_chart(history)
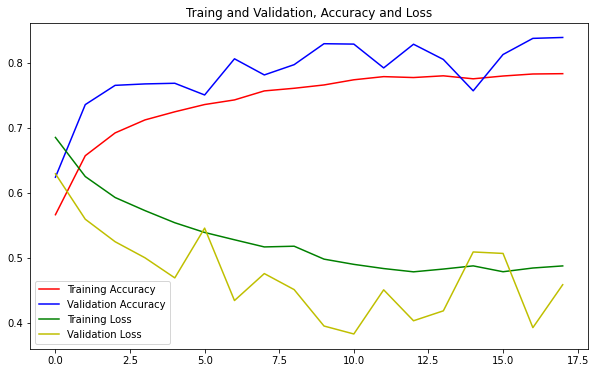
Từ đồ thị ta có thể nhận xét rằng model được training khá tốt, có một chút overfitting nhưng không đáng kể.
Cuối cùng, model nên được lưu lại để sử dụng cho việc dự đoán về sau:
model.save('cats-dogs-model.h5')
Source code của bài này, các bạn có thể tham khảo trên github cá nhân của mình tại đây.
Bài tiếp theo, ta sẽ áp dụng thêm 2 kỹ thuật quan trọng nữa cho bài toán phân loại cat-dog, đó là data augmentation và ModelCheckpoint. Cũng giống như EarlyStopping, mục đích của 2 kỹ thuật này không gì hơn là ngăn chặn hiện tượng Overfitting của model trong quá trình training. Mời các bạn đón đọc!
Tham khảo