Mạng thần kinh tích chập (Convolutional Neural Network (CNN) - Phần 3
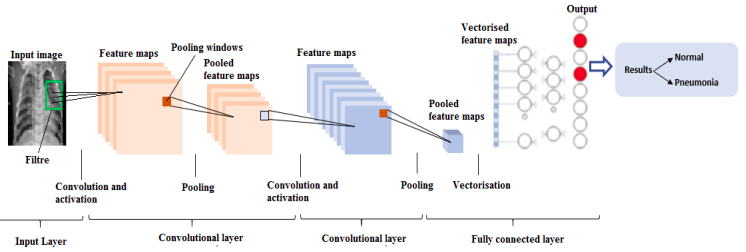
Tiếp tục chuỗi các bài viết về CNN, trong bài này mình sẽ chia sẻ với các bạn một số “common patterns 7 rules” trong việc xây dựng kiến trúc CNN. Nắm rõ những “patterns & rules” này sẽ giúp các bạn giảm thiếu thời gian và công sức khá nhiều trong các dự án của các bạn!
3. Common Architectures & Training Patterns
Qua 2 bài viết trước, chúng ta đã biết, CNN được tạo thành từ 4 loại layers chủ yếu, bao gồm: CONV, POOL, RELU, và FC. Sắp xếp các layers này với nhau theo một thứ tự nhất định ta sẽ một CNN (gọi tên đầy đủ là kiến trúc CNN).
3.1 Layers Patterns
Nói chung, hầu hết các kiến trúc CNN đều có mộ vài lớp CONV và RELU liên tiếp nhau, theo sau bởi lớp POOL. Lặp lại như thế đến khi kích thước của input volumn đủ nhỏ, rồi thêm vào một hoặc nhiều FC layers. Pattern tổng quát như sau:
INPUT => [[CONV => RELU]xM => POOL?]xN => [FC => RELU]xK => FC
Ký hiệu x ở đây tức là lặp lại 1 hoặc nhiều lần, còn ? nghĩa là tùy chọn, có thể có hoặc không.
M, N, K thường chọn theo các rules sau:
- 0 <= N <= 3
- M >= 0
- 0 <= K <= 2
Ví dụ một số kiến trúc CNN áp dụng pattern tổng quát bên trên như sau:
- INPUT => FC
- INPUT => [CONV => RELU => POOL]x2 => FC => RELU => FC
- INPUT => [[CONV => RELU]x2 => POOL]x3 => [FC => RELU]x2 => FC
Các kiến trúc CNN kinh điển cũng dựa trên pattern tổng quát này:
- AlexNet: INPUT => [CONV => RELU => POOL]x2 => [CONV => RELU]x3 => POOL => [FC => RELU => DO]x2 => SOFTMAX
- VGGNet: INPUT => [CONV => RELU]x2 => POOL => [CONV => RELU]x2 => POOL => [CONV => RELU]x3 => POOL => [CONV => RELU]x3 => POOL => [FC => RELU => DO]x2 => SOFTMAX
Một cách khái quát, chúng ta sẽ áp dụng các kiến trúc CNN sâu khi gặp bài toán phức tạp, nhiều labels, các đối tượng thay đổi không có quy luật. Sử dụng nhiều CONV layers trước khi áp dụng POOL layer cho phép các CONV layers học được các complex features trước khi áp dụng POOL layer để giảm kích thước của input volumn.
Như đã đề cập ở bài trước, một số kiến trúc CNN đã loại bỏ hoàn toàn các POOL layers phía sau CONV layers, chỉ sử dụng CONV layers để giảm kích thước của input volumn. Hơn nữa, các FC layers ở cuối cũng không còn được sử dụng, thay vào đó là average pooling. GoogLeNet, ResNet, SqueezeNet là những kiến trúc sử dụng cách này. Kết quả là giảm số lượng tham số của CNN và thời gian train cũng ngắn hơn.
Đặc biệt hơn, GoogLeNet còn áp dụng đồng thời 3 loại filters có kích thước khác nhau (1x1, 3x3, 5x5) tại cùng 1 vị trí trong kiến trúc để học multi-level features. Những kiến trúc kiểu như này được coi là công nghệ tiên tiến trong lĩnh vực DL.
3.2 Quy tắc ngón tay cái
Trong phần này, chúng ta sẽ cùng xem xét một số rules khi xây dựng CNN model.
- Rule 1
Đầu tiên, images đưa vào CNN nên có chiều rộng và chiều cao bằng nhau (square) ($W_{input} = H_{input}$). Sử dụng squere images cho phép chúng ta tận dụng các lợi ích của các thư viện tối ưu trong đại số tuyến tính. Kích thước thường hay sử dụng là: 32x32, 64x64, 96x96, 224x224, 227x227, 229x229.
- Rule 2
Thứ 2, sau khi đi qua CONV layer đầu tiên, kích thước của images nên có thể chia hết cho 2. Điều này, cho phép POOL layer tiếp sau đó hoạt động theo cách hiệu quả hơn. Để áp dụng rule này, có thể điêu chỉnh kích thước của filters và stride. Nói chung, CONV layers nên có kích thước nhỏ (3x3 hoặc 5x5). Tiny filter (1x1) có thể được sử dụng để học các local features, nhưng chỉ nên áp dụng trong các kiến trúc hiện đại và phức tạp. Kích thước lớn hơn của filters (7x7 hoặc 11x11) cũng có thể xuất hiện ở CONV layer đầu tiên trong kiế trúc để giảm nhanh kích thước không gian của input volumn có kích thước > 200x200 pixels. Nhấn mạnh là chỉ áp dung filers có kích thước lớn ở CONV layer đầu tiên, ngược lại, input volumn sẽ giảm rất nhanh làm mất mát các features quan trọng.
-
Rule 3 Stride của CONV, S = 1 cũng nên được sử dụng cho các CONV layers đối với các input volumns có kích thước trung bình nhỏ (< 200x200 pixels). Sử dụng S = 2 cho các input volumns có kích thước lớn hơn, nhưng cũng chỉ nên áp dụng ở CONV layer đầu tiên. Khi S = 1 thì CONV layers làm nhiệm vụ học các features của images, trong khi POOL layers chịu trách nhiệm giảm kích thước input volumns. Tuy nhiên, nhắc lại lần nữa rằng trong các kiến trúc CNN tiên tiến, POOL layers đang dần dần được thay thể bởi CONV layers với S >= 2.
-
Rule 4 Cá nhân mình thường áp dụng zero-padding trong CONV layer để đảm bảo kich thước của input volumns không đổi khi đi qua CONV layer và sử dụng POOL layer để giảm kích thước input volumn. Thực nghiệm của mình cho thấy
classification accuracythường cao hơn khi sử dụng rule này. Khi làm viêc với Keras framework, bạn có thể làm điều này một cách dễ dàng bằng cách settingpadding=samekhi tạo CONV layer. Bạn chỉ nên sử thay POOL layer bằng CONV layer khi đã thành thạo ở mức chuyên gia trong việc thiết kế kiến trúc của CNN. -
Rule 5
Đối với POOL layer, kích thước thông thường của nó trong kiến trúc CNN là 2x2, cộng với stride S = 2. Kích thước 3x3 cũng có thể sử dụng ở các layers đầu trong CNN để giảm nhanh kích thước của input volumn. Kích thước > 3x3 chưa từng thấy xuất hiện trong bất cứ mạng CNN nào từ trước đến giờ.
- Rule 6
Về phần Batch Normalization, như trong bài trước đã đề cập, mặc dù nó làm tăng lên đáng kể thời gian training, nhưng chúng ta vẫn nên sử dụng nó trong hầu hết các trường hợp vì những lợi ích mà nó mang lại. BN layer được đặt sau ACT layer như trong các ví dụ sau:
-
INPUT => CONV => RELU => BN => FC
-
INPUT => [CONV => RELU => BN => POOL]x2 => FC => RELU => BN => FC
-
INPUT => [[CONV => RELU => BN]x2 => POOL]x3 => [FC => RELU => BN]x2 => FC
-
Rule 7
Droput (DO) được đặt giữa các FC layers với xác suất ngắt kết nối các nodes là 50%. Nó cũng được khuyên sử dụng DO trong mọi kiến trúc CNN của bạn. Cá nhân mình, đôi khi cũng đặt DO ở giữa CONV và POOL layers, và điều này đôi khi cũng tỏ ra hiệu quả trong việc giảm bớt Overfitting. Bạn có thể thử-sai trong các bài toán của bạn.
Ok, đó là 7 rules mình muốn giới thiệu đến các bạn. Bằng viêc ghi nhớ những rules này, bạn sẽ bớt đau đầu hơn khi xây dựng kiến trúc CNN của riêng mình. Một khi bạn đã trở thành chuyên gian xây dựng mạng CNN theo cách truyền thống như thế này, hãy thử bỏ qua max pooling, chỉ sử dụng CONV layer để giảm kích thước không gian của input volumns và sử dụng average pooling thay thế cho FC layer để giảm độ phức tạp tính toán của CNN. Mình sẽ đề cập chi tiết hơn những kỹ thuật advances này trong các bài viết về sau.
4. Tổng kết
Vậy là mình đã kết thúc 3 bài viết về CNN. Hi vọng với những kiến thức chia sẻ ở đây sẽ giúp ích được cho các bạn, đặc biệt là các patterns và rules ở bài số 3 này. Các bạn có thể áp dụng luôn vào trong bài toán của mình và kiểm tra sự khác biệt.
Tham khảo