Mạng thần kinh tích chập (Convolutional Neural Network (CNN) - Phần 1
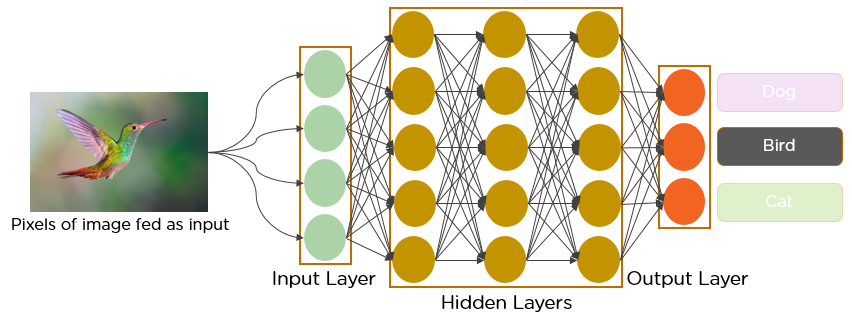
Sau khi đã tìm hiểu cơ bản về Neural Network, chúng ta sẽ đi tìm hiểu về CNN. CNN là một dạng kiến trúc Neural Network đóng vai trò vô cùng quan trọng trong Deep Learning.
Trong Feedfoward Neural Network, mỗi neural trong một layer được kết nối đến tất cả các nodes của layer tiếp theo. Ta gọi điều này là Fully Connected (FC) layer. Tuy nhiên, trong CNNs, FC layers chỉ được sử dụng ở 1 vài layers cuối. Các layers còn lại được gọi là convolutional layers.
Một hàm kích hoạt (activation function) (thường là ReLU) được áp dụng tới output của các convolutional layers. Kết hợp với các dạng layers khác nhau để giảm kích thước của input. Các FC layers ở cuối có nhiệm vụ phân loại output thành các classes khác nhau.
Mỗi layer trong CNN áp dụng một tập các bộ lọc (filters) (có thể lên đến hàng trăm hoặc hàng nghìn), kết hợp kết quả lại, cho qua layer tiếp theo. Trong suốt quá trình training, giá trị của các filters được cập nhật (tương tự như trọng số weight trong Neural Network).
Trong lĩnh vực xử lý ảnh, CNN có thể học để:
- Phát hiện biên (edges) từ
raw pixel dataở layer đầu tiên. - Sử dụng edges đã phát hiện để phát hiện hình dạng (shapes) đối tượng ở layer thứ 2.
- Sử dụng shapes để phát hiện
heigher-level featurestrong các layers tiếp theo.
1. Hiểu rõ về Convolutions
Chúng ta sẽ cùng nhau trả lời một số câu hỏi sau:
- Convolutions là gì?
- Chúng lamf được những việc gì?
- Tại sao lại sử dụng chúng?
- Áp dụng chúng vào xử lý ảnh như thế nào?
Từ convolution, dịch sang tiếng việt là tích chập, nghe có vẻ phức tạp. Bạn chắc chắn đã nghe đến từ này nếu bạn học qua môn Xử lý tín hiệu sô. Tuy nhiên, convolution trong lĩnh vực xử lý lý ảnh hơi khác một chút. Không phải khi có Deep Learning, chúng ta mới sử dụng convolution, các phương pháp xử lý ảnh truyền thống đều sử dụng convolution: Edges detection, Sharpen images, Blurring and Smoothing images, … Vì thế mới nói, convolution là xương sống của xử lý ảnh. Hiểu rõ convolution là điều kiện tiên quyết để bước chân vào lĩnh vựa xử lý ảnh (theo cả phương pháp truyền thống và sử dụng Deep Learning).
Nghe thì có vẻ “đao to búa lớn” vậy, nhưng thực sự không phải vậy. Convolution đơn giản chỉ là tổng của các tích đôi một của từng phần tử tron 2 ma trận. Chia nhỏ các bước ra cho dễ hiểu:
- Lấy 2 ma trận có cùng kích thước
- Nhân 2 ma trận đôi một (element-by-element) (không phải phép nhân ma trận trong đại số tuyến tính).
- Cộng kết quả của các tích lại.
Yup, đó là convolution.
1.1 Kernel
Một image là một ma trận nhiều chiều. Thường là 3 chiều (w, h, c) với width là số cột, height là số hàng và depth là số kênh màu. “Image matrix” thường được gọi với cái tên “big matrix”. Một ma trận khác gọi là kernel (hoặc “convolution matrix”, “tiny matrix”, filter) đặt bên trên “big matrix”, trượt từ trái sang phải, từ trên xuống dưới. Trong quá trình di chuyển, các phép toán (convolution, …) được áp dụng đối với 2 ma trận đó. Sử dụng các kernel khác nhau, ta có thể đạt được các mục đích mong muốn: Blurring (average smoothing, Gaussian smoothing, …), Edge detection (Laplacian, Sobel, ...), …
Để hiểu rõ hơn, chúng ta sẽ làm thử 1 ví dụ cụ thể.
Giả sử có “image matrix” kernel như sau:


Theo lý thuyết bên trên, kernel sẽ được trượt qua “image matrix” từ trái qua phải, từ trên xuống dưới. Số bước trượt thường là 1 hoặc 2. Tại bước, sau khi trượt xong, ta sẽ dừng lại, thực hiện phép convolution giữa kernel và phần “image matrix” bị che bởi kernel. Giá trị ouput được lưu trong ma trận kết quả tại vị trí trung tâm của kernel tại bước đó.
Chi tiết các bước:
- Chọn tọa độ ($x,y$) từ “image matrix”.
- Đặt
centercủa kernel tại ($x,y$). - Thực hiện
convolutiongiữa kernel và phần “image matrix” bị che phủ bởi kernel. - Lưu kết quả tại ($x,y$) của ma trận kết quả.
Ví dụ, với $(x,y) = (3,3)$:


Sau khi tính toán xong, ta sẽ gán giá trị 132 cho pixel tại vị trí (3,3) của ma trận kết quả. $O_{i,j}$ = 132.
1.2 Implement Convolutions bằng python.
Giờ hãy bắt tay vào code thôi. Việc thực hiện convolution bằng code sẽ giúp bạn hiểu sâu sắc hơn cách áp dụng convolution trong xử lý ảnh.
Tạo file convolutions.py và code như sau:
# USAGE
# python convolutions.py --image mai-ngoc.jpg
# import the necessary packages
from skimage.exposure import rescale_intensity
import numpy as np
import argparse
import cv2
def convolve(image, K):
# grab the spatial dimensions of the image and kernel
(iH, iW) = image.shape[:2]
(kH, kW) = K.shape[:2]
# allocate memory for the output image, taking care to "pad" the orders of the input image so the spatial size (i.e., width and height) are not reduced
pad = (kW - 1) // 2
image = cv2.copyMakeBorder(image, pad, pad, pad, pad,
cv2.BORDER_REPLICATE)
output = np.zeros((iH, iW), dtype="float")
# loop over the input image, "sliding" the kernel across each (x, y)-coordinate from left-to-right and top-to-bottom
for y in np.arange(pad, iH + pad):
for x in np.arange(pad, iW + pad):
# extract the ROI of the image by extracting the *center* region of the current (x, y)-coordinates dimensions
roi = image[y - pad:y + pad + 1, x - pad:x + pad + 1]
# perform the actual convolution by taking the element-wise multiplication between the ROI and the kernel, the summing the matrix
k = (roi * K).sum()
# store the convolved value in the output (x, y)- coordinate of the output image
output[y - pad, x - pad] = k
# rescale the output image to be in the range [0, 255]
output = rescale_intensity(output, in_range=(0, 255))
output = (output * 255).astype("uint8")
# return the output image
return output
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
args = vars(ap.parse_args())
# construct average blurring kernels used to smooth an image
smallBlur = np.ones((7, 7), dtype="float") * (1.0 / (7 * 7))
largeBlur = np.ones((21, 21), dtype="float") * (1.0 / (21 * 21))
# construct a sharpening filter
sharpen = np.array((
[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]), dtype="int")
# construct the Laplacian kernel used to detect edge-like regions of an image
laplacian = np.array((
[0, 1, 0],
[1, -4, 1],
[0, 1, 0]), dtype="int")
# construct the Sobel x-axis kernel
sobelX = np.array((
[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]), dtype="int")
# construct the Sobel y-axis kernel
sobelY = np.array((
[-1, -2, -1],
[0, 0, 0],
[1, 2, 1]), dtype="int")
# construct an emboss kernel
emboss = np.array((
[-2, -1, 0],
[-1, 1, 1],
[0, 1, 2]), dtype="int")
# construct the kernel bank, a list of kernels we're going to apply using both our custom `convole` function and OpenCV's `filter2D` function
kernelBank = (
("small_blur", smallBlur),
("large_blur", largeBlur),
("sharpen", sharpen),
("laplacian", laplacian),
("sobel_x", sobelX),
("sobel_y", sobelY),
("emboss", emboss))
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# loop over the kernels
for (kernelName, K) in kernelBank:
# apply the kernel to the grayscale image using both our custom `convolve` function and OpenCV's `filter2D` function
print("[INFO] applying {} kernel".format(kernelName))
convolveOutput = convolve(gray, K)
opencvOutput = cv2.filter2D(gray, -1, K)
# show the output images
cv2.imshow("Original", gray)
cv2.imshow("{} - convole".format(kernelName), convolveOutput)
cv2.imshow("{} - opencv".format(kernelName), opencvOutput)
cv2.waitKey(0)
cv2.destroyAllWindows()
Kết quả:

Từ trái sang phải: Ảnh gốc, ảnh áp dụng "average blur" sử dụng 7x7 kernel convolution, và ảnh áp dụng "average blur" sử dụng OpenCV’s cv2.filter2D.
1.3 Vai trò của Convolutions trong Deep Learning
Như các bạn đã thấy từ phần trước, chúng ta phải tự định nghĩa (manually hand-define) các kernel cho mỗi nhiệm vụ xử lý ảnh khác nhau.
Liệu có cách nào “tự động hóa” việc này?
CNN chính là câu trả lời. Bằng cách sắp xếp nhiều lớp convolutions, kết hợp với “activation function”, pooling, backpropagation, … CNNs có khả năng học để cập nhật giá trị của kernel, từ đó trích xuất được các đặc trưng của đối tượng trong ảnh.
Trong bài tiếp theo, mình sẽ tìm hiểu kỹ hơn về các dạng layers khác nhau, sau đó sẽ đưa ra một số “common layer stacking patterns” được sử dụng rộng rãi trong lĩnh vực xử lý ảnh.
Source code sử dụng trong bài này, các bạn có thể tham khảo tại github cá nhân của mình tại github
Tham khảo