Neural Network cơ bản (Phần 1)
Trong bài này chúng ta sẽ cùng nhau tìm hiểu lys thuyết cơ bản về mạng thần kinh nhân tạo (neural network):
- Cấu trúc của
neural network. - Thuật toán lan truyền (propagation) và lan truyền ngược (backpropagation).
Những kiến thức trong bài này sẽ là tiền đề để các bạn tiến xa hơn trong thế giới của Deep Learning.
1. Neural Network là gì?
Neural Networks là các khối (blocks) để xây dựng lên các hệ thống Deep Learning. Chúng ta sẽ bắt đầu với việc xem xét ở mức "high-level" của Neural Network, bao gồm cả mối liên hệ của chúng với não bộ của con người.
Trong thực tế, có rất nhiều những công việc rất khó để có thể thực hiện tự động hóa bởi máy móc nhưng lại rất dễ dàng đối với các loài động vật (bao gồm cả con người). Những công việc đó thường liên quan đến việc nhận diện, phân loại đối tượng.
Ví dụ:
- Con chó của gia đình bạn có thể phân biệt được người quen (người trong gia đình bạn) và người lạ (không phải trong gia đình bạn)?
- Một đứa trẻ có thể nhận biết được sự khác nhau giữa xe oto con và xe oto tải.
Tại sao con chó và đứa trẻ có thể làm được những việc đó?
Câu trả lời nằm ở cấu tạo bên trong não bộ của chúng. Não bộ của cả 2 đều chứa một mạng thần kinh sinh học kết nối đến hệ thần kinh trung tâm. Mạng này được tạo ra bởi rất nhiều các neurons kết nối với nhau.
Từ neural là dạng tính từ của neuron, và network ngầm chỉ kiến trúc "graph" của hệ thần kinh. Do vậy, một Artificial Neural Network (ANN) là một hệ thống tính toán, cố gắng mô phỏng (bắt chước) mạng thần kinh sinh học của các loài động vật. ANN là một graph có định hướng, nó bao gồm các nodes và các connections (kết nối giữa các nodes). Mỗi node thực hiện một tính toán đơn giản nào đó, mỗi connection mang một tín hiệu từ node này đến node khác. Những tín hiệu này đi kèm theo một trọng số (weight) chỉ ra mức độ khuyếch đại hoặc giảm bớt cường độ tín hiệu đó. Giá trị weight càng lớn chứng tỏ tín hiệu đi kèm càng quan trọng đối với kết quả đầu ra và ngược lại.
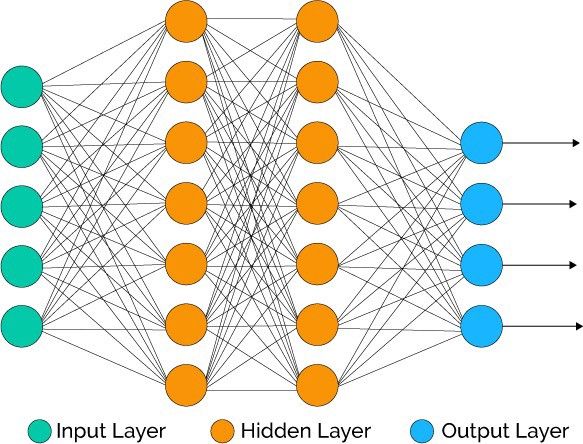
Hình dưới đây là một ANN đơn giản, bao gồm một lớp input ở đầu, 2 lớp ở giữa (hidden layers) và một lớp output ở cuối. Mỗi connection mang theo một tín hiệu xuyên qua hai hidden layers. Kết quả cuối cùng được tính toán tại lớp output.

2. Artificial Models
Hãy xem thử một ANN cơ bản như hình bên dưới:
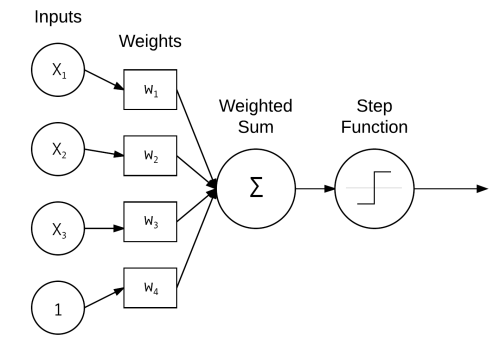
ANN này thực hiện tính tổng có trọng số ($w_i$) của các input vectors($x_i$). Trong thực tế, các input vectors có thể là pixcel của images, hay các rows của một dataset dạng tabular.
Mỗi $x_i$ kết nối với một neuron thông qua vector trọng số $w_i$.
Diễn giải bằng công thức toán học thì output của ANN này sẽ là:
- $y = f(w_1x_1 + w_2x_2 + ... + w_nx_n)$
- $y = f(\sum_{i=1}^n w_ix_i)$
- $y = f(net)$. Với net = $\sum_{i=1}^n w_ix_i$
Nói chung, dù diễn đạt theo cách nào đi nữa thì ý tưởng chung vẫn là áp dụng hàm activate (f) vào tổng có trọng số của các input vectors.
3. Activation Functions
- a) Step function
Hàm activation đơn giản nhất có lẽ là Step function. Hàm này được sử dụng bởi thuật toán Perceptron (sẽ đề cập ở phần sau).
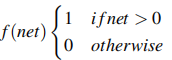
Hàm này luôn nhận giá trị 1 nếu $\sum_{i=1}^n$ $w_i$$x_i$ >= 0 và nhận giá trị 0 trong trường hợp còn lại.
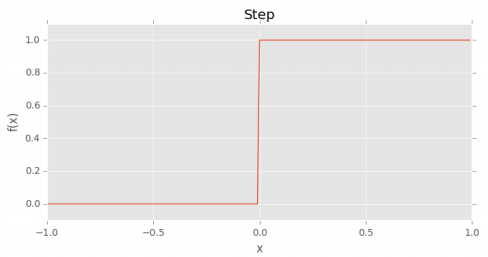
Vấn đề của step function là nó giá trị của nó không có sự khác biệt khi net >=0 hoặc net < 0. Điều này có thể dẫn đến một số vấn đề khi huấn luyện neural network.
- b) Sigmoid function

y = tf.nn.sigmoid(x)
d2l.plot(x.numpy(), y.numpy(), 'x', 'sigmoid(x)', figsize=(5, 2.5))
So với step function, sigmoid function có một số ưu điểm sau:
- Giá trị của nó liên tục và phân biệt nhau tại một nơi.
- Đồ thị của nó đối xứng qua trục y.
Tuy nhiên, có 2 nhược điểm lớn nhất của sigmoid function là:
- Output của nó không tập trung quanh điểm gốc tọa độ.
- Càng xa gốc tọa độ, giá trị của nó tiệm cận với giá trị
bão hòa. Điề u này vô tình triệt tiêu gradient, vì delta của gradient vô cùng nhỏ.
Đạo hàm của sigmoid function như sau:

with tf.GradientTape() as t:
y = tf.nn.sigmoid(x)
d2l.plot(x.numpy(), t.gradient(y, x).numpy(), 'x', 'grad of sigmoid',
figsize=(5, 2.5))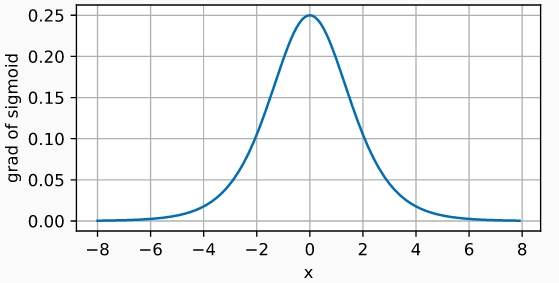
- c) Tanh function
Hàm này giải quyết được nhược điểm thứ nhất của sigmoid function.

y = tf.nn.tanh(x)
d2l.plot(x.numpy(), y.numpy(), 'x', 'tanh(x)', figsize=(5, 2.5))
- d) ReLU (Rectified Linear Unit) funtion
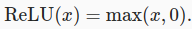
Hàm này nhận giá trị 0 khi inputs < 0, nhưng sẽ tăng tuyến tính khi inputs >= 0.
Thực tế chứng minh, ReLU function hoạt động tốt hơn hẳn so với các hàm kể trên. Bắt đầu từ năm 2015, nó được sử dụng thường xuyên trong Deep Learning.
x = tf.Variable(tf.range(-8.0, 8.0, 0.1), dtype=tf.float32)
y = tf.nn.relu(x)
d2l.plot(x.numpy(), y.numpy(), 'x', 'relu(x)', figsize=(5, 2.5))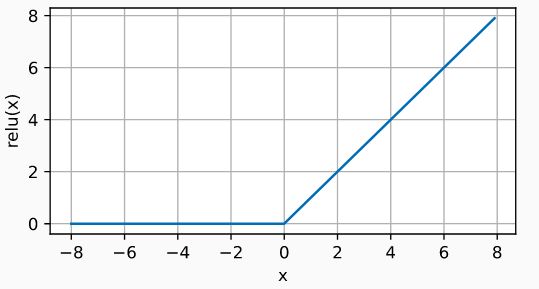
ReLU function vẫn có nhược điểm. Khi inputs < 0, nó nhận giá trị 0. Như vậy thì không thể tính được gradient tại những điể m đó. Thực tế thì cũng hiếm khi có trường hợp nào mà inputs lại có giá trị < 0. Tuy nhiên, để giải quyết triệt để vấn đề thì lại sinh ra một hàm mới:
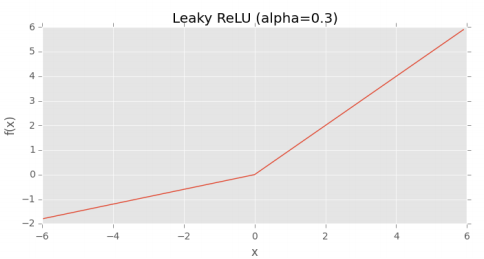
- e) Leaky ReLU function
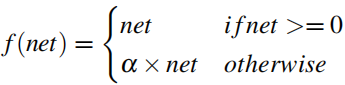
Đây là một biến thể của ReLU funtion, nó nhận một giá trị khác 0 (thường rất nhỏ) khi inputs < 0. Giá trị của $\alpha$ rất nhỏ và được cập nhật trong quá trình huấn luyện neural network.
- f) ELU (Exponential Linear Units) function

Khác với ReLU function, giá trị của $\alpha$ trong ELU function được cố định từ đầu (lúc xây đựng kiến trúc mạng). Giá trị thông thường của $\alpha$ là 1.

Nên sử dụng activation function nào?
Việc có nhiều hơn 1 activation function đôi khi làm cho bạn bối rối khi lựa chọn sử dụng cái nào, không sử dụng cái nào?
Lời khuyên của mình như sau:
- Bắt đầu với ReLU để đặt được một
baseline accuracy. (Hầu hết các public papers đều làm như vậy) - Thử chuyển qua sử dụng các biến thể của ReLU: Leaky ReLU, ELU.
Trong các dự án thực tế thì mình thường làm theo các bước:
- Sử dụng ReLU
- Tune các hyper-parameters khác: architecture, learning rate, regularization strength, ... Ghi lại các giá trị
accuracy. - Một khi đã tương đối thoả mãn về
accuracy, chuyển qua ELU. Độ chính xác thường sẽ tăng khoảng 1-5% tùy thuộc dataset.
Cách này chỉ là kinh nghiệm cá nhân của mình, và không có gì đảm bảo đúng trong mọi trường hợp. Bạn có thể tham khảo hoặc không. Hãy luôn nhớ thử-sai mọi khả năng có thể cho bài toán của bạn.
4. Feedfoward Network Architecture
Kiến trúc ANN thì có rất nhiều, nhưng phổ biến nhất là dạng feedfoward network.
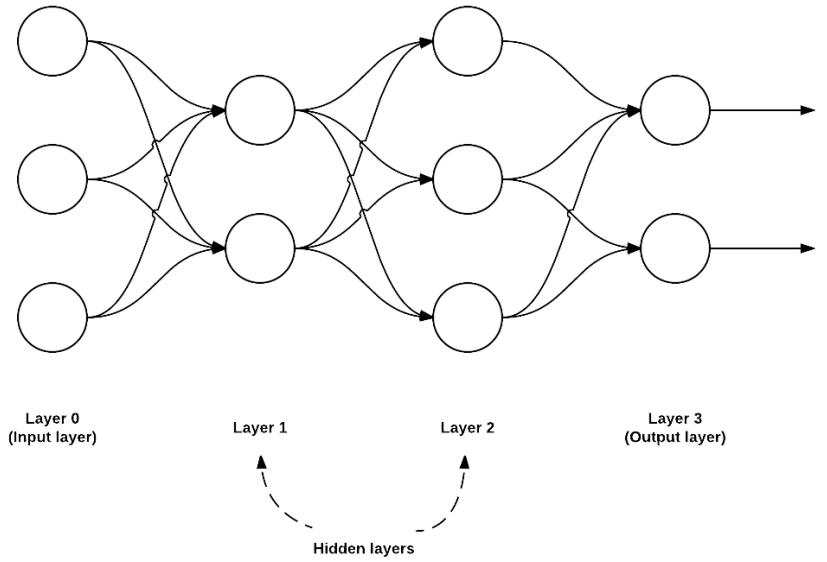
Trong kiến trúc này, một connection giữa 2 nodes chỉ được phép đi theo chiều từ layer $i$ tới layer $i+1$ (vì thế mà có tên feedfoward). Không có chiều từ layer $i+1$ đến layer $i$ hoặc bất kỳ chiều nào khác. Khi có thêm chiều từ layer $i+1$ đến layer $i$ (feedback connection) thì ta được kiến trúc RNN (Recurrent Neural Network). Feedfoward network được sử dụng chủ yếu trong các bài toán về Computer Vision (mạng CNN là một ví dụ điển hình) , trong khi feedback network lại được sử dụng chủ yếu trong các bài toán về Natural Language Processing.
ANN được sử dụng cho cả 3 dạng bài toán: supervised, unsupervised, and semi-supervised. Một số ví dụ điển hình là classification, regression, clustering, vector quantization, pattern association, ...
Trong bài tiếp theo, mình sẽ minh họa cách thức cập nhật trong số của mạng ANN thông qua một ví dụ rất dễ hiểu. Mời các bạn đón đọc.
3. Tham khảo