Tổng hợp các thuật toán Deep Learning
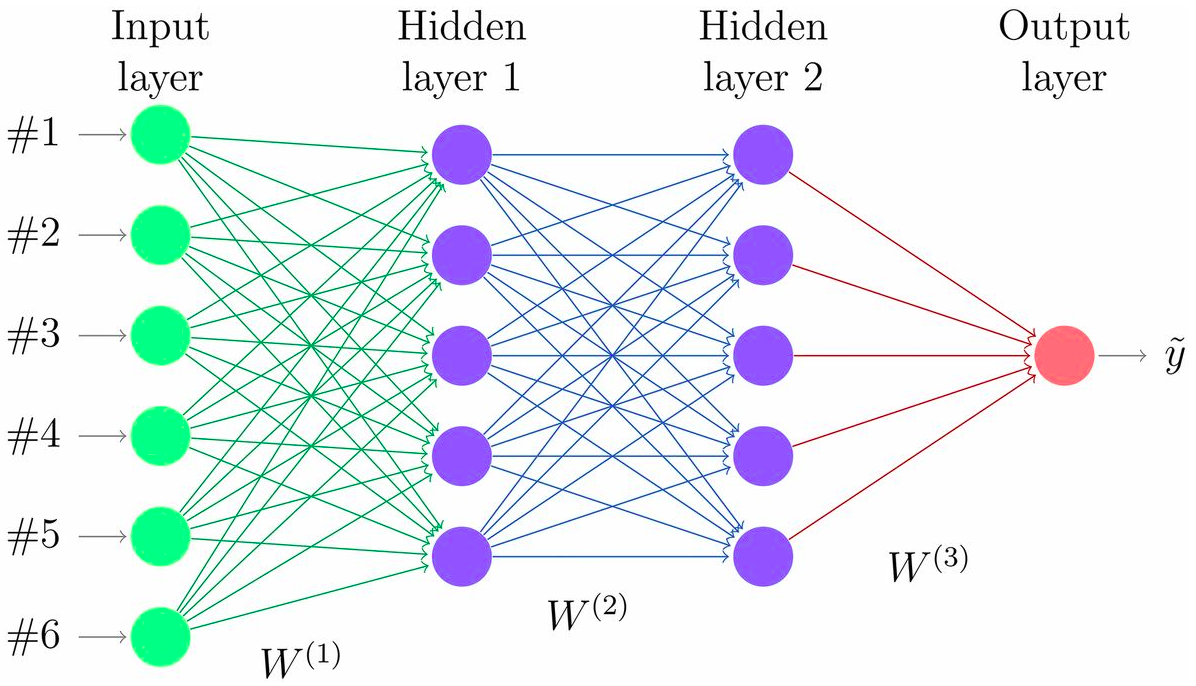
Bài viết này nhằm mục đích tổng hợp, tóm tắt lại các thuật toán của Deep Learning, giúp bạn đọc có cái nhìn toàn cảnh và hiểu rõ hơn về Deep Learning.
1. Deep Learning (DL) là gì?
Theo Wikipedia: “Deep learning (also known as deep structured learning or differential programming) is part of a broader family of machine learning methods based on artificial neural networks with representation learning. Learning can be supervised, semi-supervised or unsupervised”.
Hiểu theo một cách khác thì DL là một tập hợp các thuật toán mô phỏng lại cách thức hoạt động của bộ não của con người trong việc phân tích dữ liệu, nhằm tạo ra các models cái mà được sử dụng cho việc đưa ra quyết định dựa trên dữ liệu đầu vào. Về bản chất, DL bao gồm nhiều layers, mỗi layer có thể coi là một mạng Neural Network (NN).
Giống như não bộ của con người, NN có chứa các neurons. Mỗi neurons nhận các tín hiệu ở đầu vào, nhân chúng với các trọng số (weights), tổng hợp chúng lại, và sau cùng là áp dụng các hàm kích hoạt (thường là non-linear) lên chúng. Các neurons được sắp xếp thành các layers liên tiếp nhau (stack).
Các kiến trúc mạng DL đều sử dụng thuật toán Backpropagation để tính toán và cập nhật các trọng số của nó thông qua quá trình huấn luyện. Về mặt ý tưởng, dữ liệu được đưa vào mạng DL, sinh ra output, so sánh output với giá trị thực tế (sử dụng loss function) rồi điều chỉnh trọng số theo kết quả so sánh đó.
Việc điều chỉnh trọng số là một quá trình tối ưu, thường sử dụng thuật toán SGD. Ngoài SGD, một số thuật toán khác cũng hay được sử dụng. Đó là Adam, Radam, SRMprop.
2. Các thuật toán DL

2.1 Convolution Neural Network (CNN)
CNN sử dụng phép toán tích chập để tạo liên kết giữa các layers trong mạng NN. Mỗi neuron, thay vì kết nối đến tất cả các neurons khác thì sẽ chỉ kết nối đến một vài neurons đại diện. Điều này giúp cho CNN học được các mối liên hệ không gian của dữ liệu tốt hơn.
Đó là lý do mà vì sao CNN lại được sử dụng rất phổ biến trong các bài toán về Computer Vision như phân loại hình ảnh, phát hiện đối tượng trong ảnh/video, …
Một vài kiến trúc mạng CNN kinh điển có thể kể đến như: VGG, ResNet, MobiNet, InceptionNet, Yolo, SSD, …
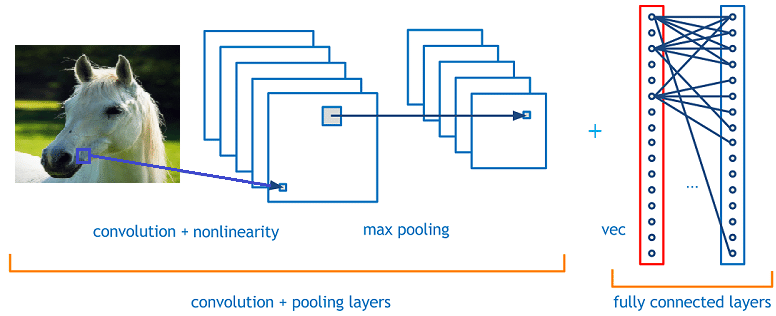
2.2 Recurrent Neural Network (RNN)
RNN là thuật toán rất phù hợp với các loại dữ liệu có mối liên hệ về thời gian như time serial forecasting hay trong các bài toán về xử lý ngôn ngữ tự nhiên (NLP), bởi vì một phần output của nó ở thời điể m này được đưa trở lại thành input ở thời điểm tiếp theo. Do cách thức làm việc đặc biệt như vậy mà nó có có năng ghi nhớ được thông tin trong quá khứ và sử dụng những thông tin đó vào việc dự đoán kết quả.
Một số kiến trúc mạng kinh điển của RNN có thể kể đến như: GRU, LSTM, …
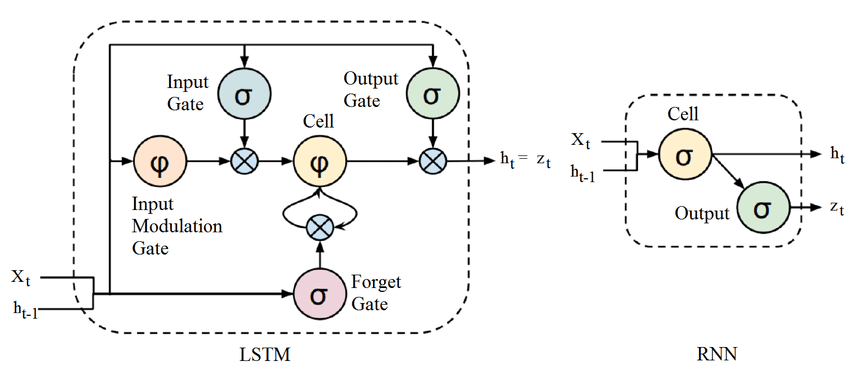
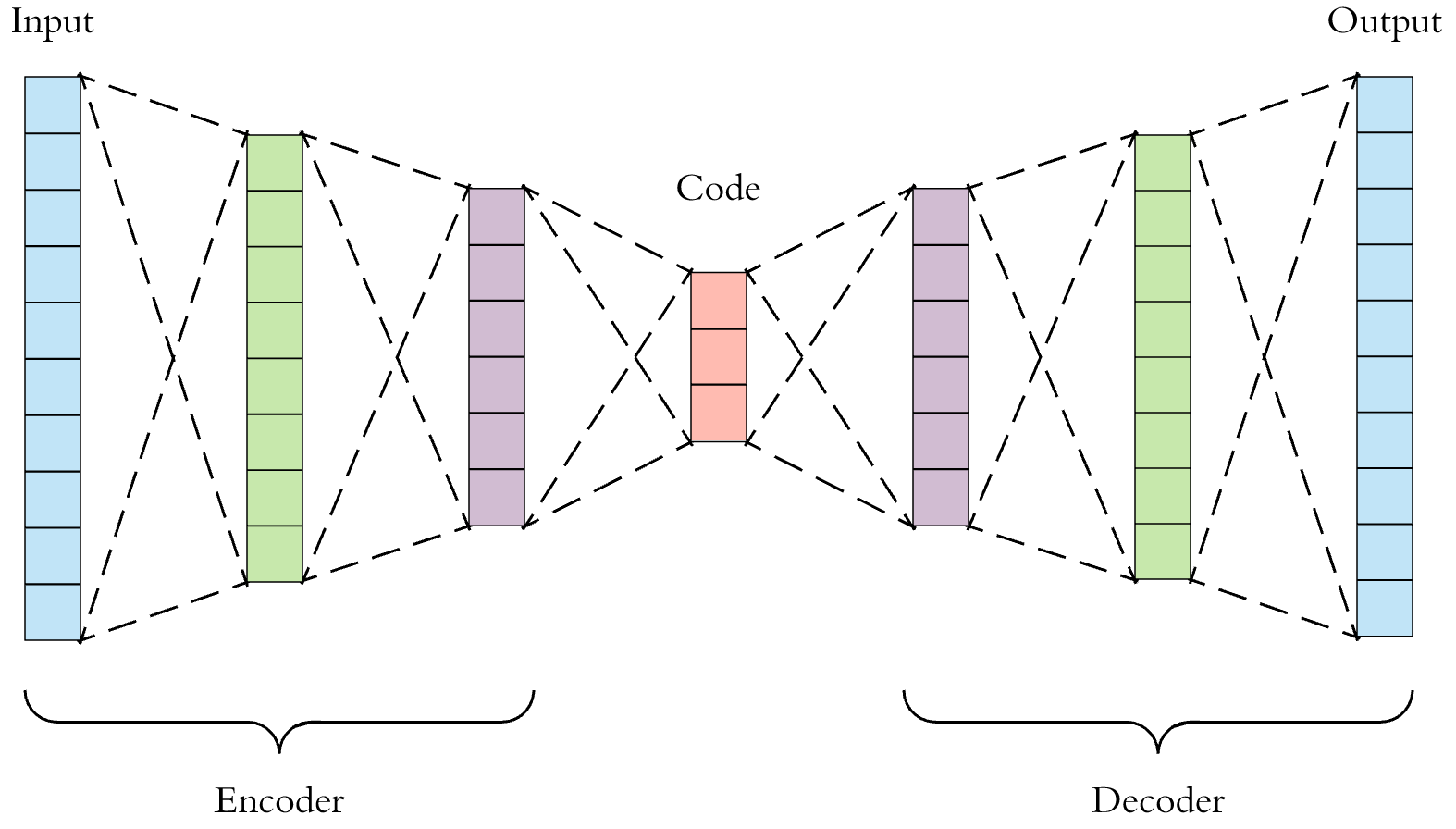
2.3 AutoEncoders
AutoEncoders là kiến trúc mạng bao gồm 2 thành phần: Encoder và Decoder. Encoder nhận input và mã hóa nó thành các vector trong một không gian có số chiều ít hơn. Decoder sử dụng các vertors đó để giải mã (xây dựng lại) nó thành dữ liệu ban đầu.
AutoEncoders sử dụng chủ yếu trong các bài toán về giảm chiều dữ liệu, nén dữ liệu, …
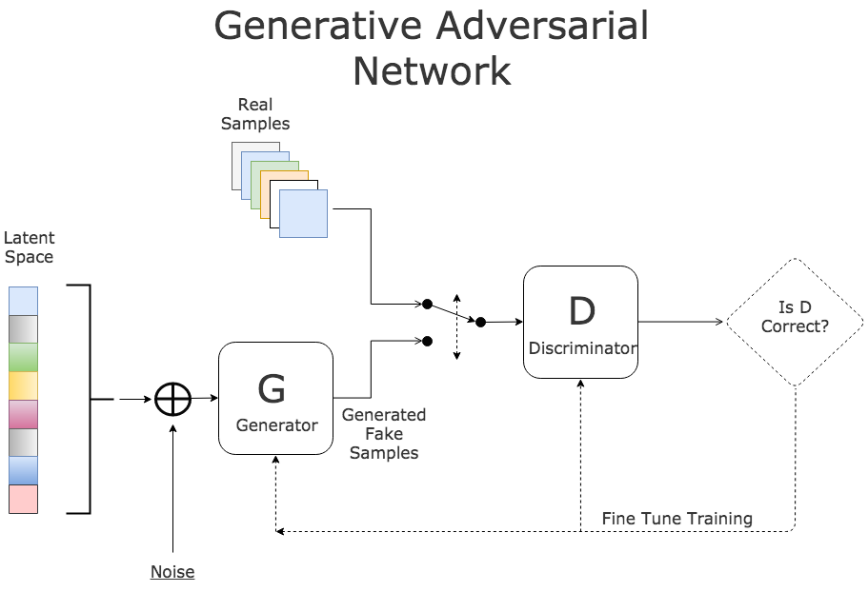
2.4 Generative Adversarial Networks (GAN)
GAN cũng bao gồm 2 thành phần: Generator và Discriminator. Generator sinh ra dữ liệu giả và Discriminator sẽ cố gắng phân biệt dữ liệu mới sinh ra đó là giả hay thật. Hai thành phần này được huấn luyện cùng với nhau, chúng sẽ cạnh tranh nhau để cuối cùng tạo ra được model GAN tốt nhất.
GAN được dùng để sinh ra dữ liệu mới từ dữ liệu ban đầu, ví dụ: sinh ra các mẫu thời trang mới, các mẫu nhân vật hoạt hình mới, …
2.5 Transformer
Transformer là kiến trúc mạng mới được phát triển và được sử dụng rộng rãi gần đây trong các bài toán NLP khi nó chứng minh được sự vượt trội của nó so với RNN. Có được này là nhờ vào một cơ chế, gọi là Attention, tức là chỉ tập trung và một số vị trí cụ thể thay vì toàn bộ vị trí trong dữ liệu.
Transformer cũng bao gồm một số bộ encoders và một số bộ decoders được đặt cạnh nhau (stacked) cùng với các lớp attentions.
Hiện nay, BERT và GPT-3 là 2 pre-trained model của transformer được sử dụng rất nhiều trong lĩnh vực NLP.
2.6 Graph Neural Network (GNN)
DL nói chung thường làm việc với dữ liệu có cấu trúc. Tuy nhiên, trong thực tế có rất nhiều dữ liệu ở dạng phi cấu trúc (unstructed data) và được sắp xếp dưới dạng graph. Ví dụ như là mạng xã hội, cấu tạo phân tử trong hóa học, …
GNN chính là mạng NN mô hình hóa graph data. Chúng sẽ nhận diện các mối liên kết của các nodes trong graph và output ra các vector đặc trưng của dữ liệu đó, giống như embedding. Output này được sử dụng làm input cho các NN khác.
3. Các thuật toán DL trong các bài toán Computer Vision & Natural Language Processing
3.1 DL trong CV

- Image Classification
Đây là bài toán nhận diện đối tượng trong ảnh thuộc về class nào. Số lượng class có thể là 2 (binary) hoặc nhiều hơn (multiple).
Các kiến trúc mạng kinh điển như VGG (VGG16, VGG19), ResNet, InceptionNet, MobiNet, AlexNet … giải quyết rất tốt bài toán này.
- Object Detection
Đây là bài toán mở rộng của image classification vì không chỉ phân loại mà còn phải định vị được đối tượng trong ảnh.
Các kiến trúc NN giải quyết vấn đề này bao gồm: Họ R-CNN (R-CNN, Fast R-CNN, Faster R-CNN), Yolo (YOLOv2, YOLOv3, YOLOv4), SSD, EfficientNet, …
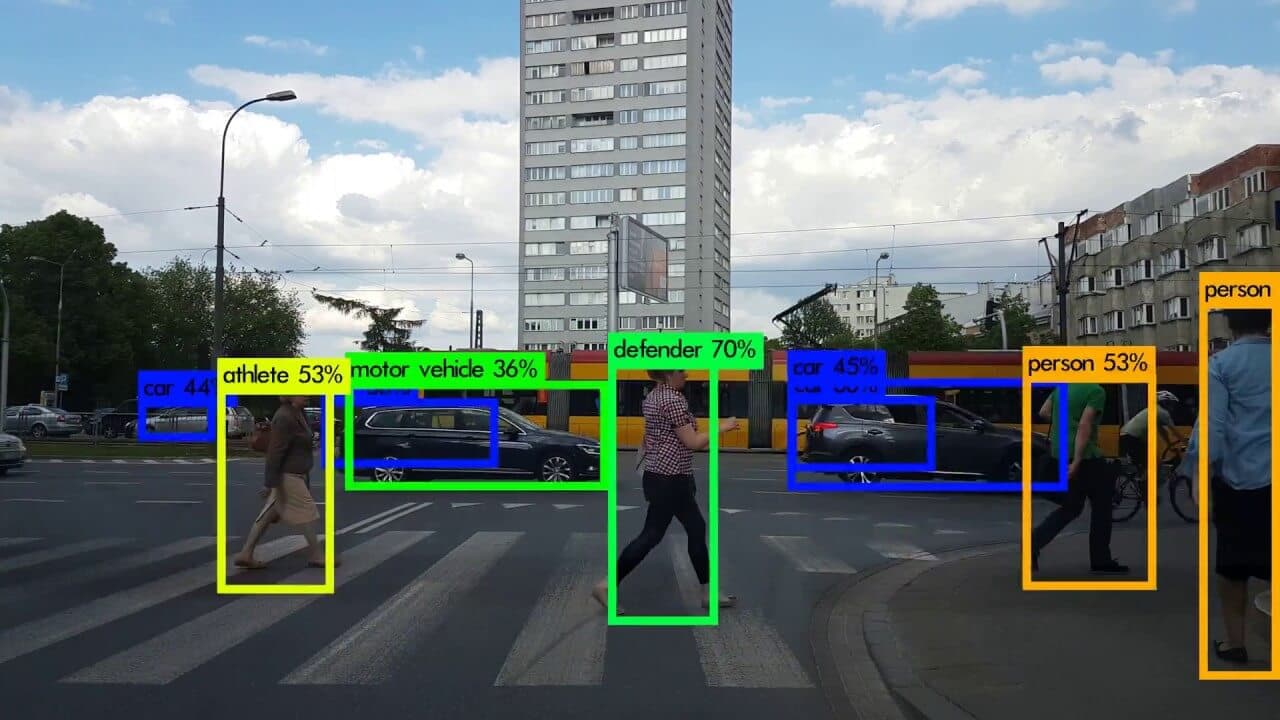
- Semantic Segmentation
Nếu như Image Classification là bài toán gán nhãn cho toàn bộ bức ảnh thì Semantic Segmentation có thể coi là bài toán gán nhãn cho từng pixcel trong ảnh đó. Tất cả các pixel thuộc cùng một class (hay các objects thuộc cùng một class) được coi như là một thực thể (thể hiện bằng màu sắc giống nhau).

Một số kiến trúc mạng như Full Connected Networks FCN, UNET, … giải quyết tốt bài toán này.
- Instance Segmentation
Cũng giống như Semantic Segmentation là gán nhãn cho từng pixel trong ảnh, tuy nhiên Instance Segmentation coi mỗi đối tượng (cùng hoặc khác class) là các thực thể riêng biệt (thể hiện bằng màu sắc khác nhau).

Kiến trúc Mask_RCNN nổi tiếng nhất cho viêc giải quyết bài toán này.
- Face Recognition
Đây là bài toán nhận diện khuôn mặt của người trong video/ảnh. Nó bao gồm 2 công đoạn: - Đầu tiên là phát hiện vùng chứa khuôn mặt (bài toán Object Detection), - Sau đó nhận diện xem khuôn mặt đó là của ai (bài toán classification)
Một số thuật toán nổi tiếng giải quyết cho công đoạn 2 là: FaceNet, VGGFace, MTCNN, … Còn đối với công đoạn 1 có thể sử dụng OpenCV.

- Optical Character Recogniton (OCR)
Đây là bài toán nhận diện ký tự trong hình ảnh. Tương tự như bài toán Face Detection, nó cũng bao gồm 2 công đoạn: - Phát hiện vùng chứa ký tự trong ảnh (bài toán object detection) - Nhận diện từng ký tự trong vùng chứa đó.
Một số thuật toán nổi bật là: - Công đoạn 1: Craft, Yolo, … - Công đoạn 2: CRNN, …
Một số thư viện hỗ trợ bài toán OCR: Tesseract, EasyOCR

- Humand Pose
Humand Pose hay Pose Estimation là bài toán xác định vị trí của các khớp nối của con người trong ảnh/video.
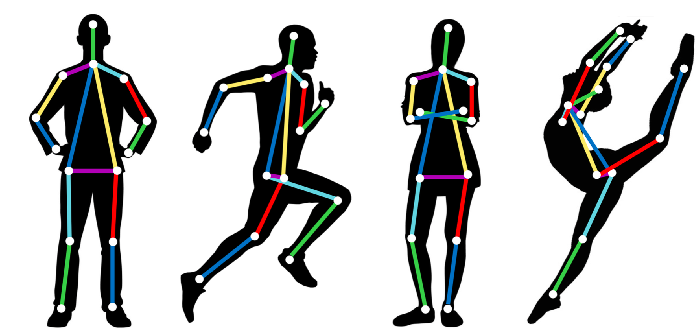
PostNet là thuật toán nối tiếng cho bài toán này.
3.2 DL trong NPL
- Các thuật toán Word Embedding
Word Embedding là quá trình biến đổi các từ thành các vector đại diện, làm đầu vào cho các DL model. Việc biến đổi này có tính đến hoàn cảnh và ngữ nghĩa của từ đó trong câu. Một số thuật toán phổ biến:
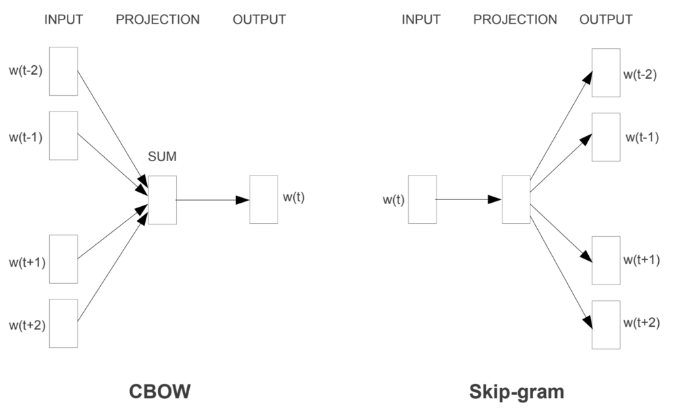
a. Word2Vec: Nó hoạt động theo theo 1 trong 2 cách, dự đoán từ dựa vào những tù xung quanh của nó (CBOW) hoăc dự đoán các từ xung quanh của 1 từ (Skip-Gram). Các từ được đưa vào Word2Vec theo dạng One-hot-encoding.
b. Glove: Là một mô hình khác mở rộng ý tưởng của Word2Vec bằng cách kết hợp nó với các kỹ thuật phân tích thừa số ma trận.
c. Contextual Word Embeddings: Sử dụng 2 layers bi-directional LSTM để embedding các từ, cho phép tận dụng sự phụ thuộc của nó với các từ trước đó.
d. Transformer: Đây là phương pháp tiên tiến nhất hiện nay, cho phép tập trung vào một vài vị trí cụ thể của từ trong câu thay vì toàn bộ như khi sử dụng LSTM.
- Sequence Modeling
Mô hình này giải quyết hầu hết các bài toán trong NLP như Machine Translation, Speech Recognition, Autocompletion và Sentiment Classification. Nó có khả năng xử lý cả một chuỗi đầu vào thay vì từng từ một.

Còn rất nhiều kiến trúc, thuật toán, model nữa mà trong bài này chưa thể kể hết được. Nhưng hi vọng qua đây, các bạn cũng có được cái nhìn tổng quát về các thuật toán, model, kiến trúc phổ biến trong các bài toán DL.
Trong các bài viết tiếp theo đi chi tiết vào một số thụât toán với các ứng dụng cụ thể. Mời các bạn đón đọc!
4. Tham khảo