XGBoost - Bài 9: Cấu hình Early_Stopping cho XGBoost model
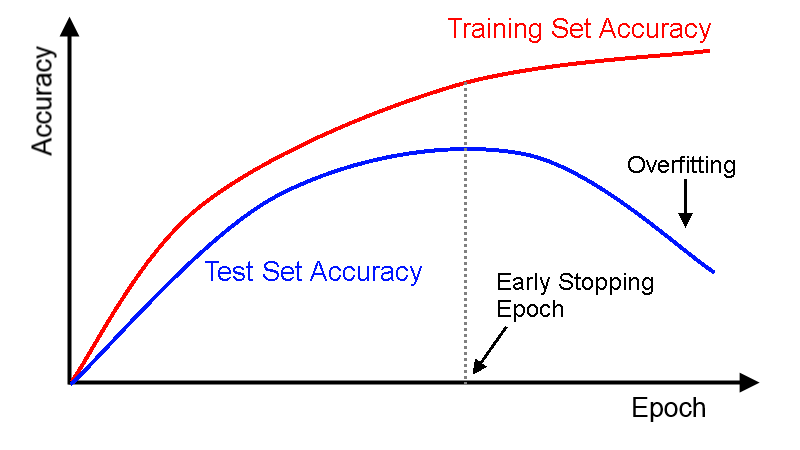
Overfitting vẫn luôn là một vấn đề làm đau đầu những kỹ sư AI. Trong bài viết này chúng ta sẽ cùng tìm hiểu cách thức monitor (giám sát) performance (hiệu năng) của XGBoost model trong suốt quá trình train. Từ đó cấu hình early stopping để quyết định khi nào thì nên dừng lại quá trình này để tránh hiện tượng overfitting.
Bài viết gồm 2 phần:
- Monitor hiệu năng của XGBoost model thông qua
learning curve(đường cong học tập). - Cấu hình
early stopping.
1. Giám sát hiệu năng của XGBoost model
Để monitor porformance của XGBoost model, ta cần cung cấp cả train set, test set và một metric (chỉ tiêu đánh giá) khi train model (gọi hàm model.fit()). Ví dụ, để tính toán error metric trên tập test set, sử dụng code snippet sau:
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, verbose=True)
XGBoost model hỗ trợ một số metric như sau:
- rmse: root mean squared error.
- mae: mean absolute error.
- logloss: binary logarithmic loss.
- mlogloss: multiclass log loss (cross entropy).
- error: classification error.
- auc: area under ROC curve. Danh sách đầy đủ các metrics, các bạn có thể xem tại đây.
Code dưới đây minh hoạ việc monitor performance trong quá trình train một XGBoost model trên tập dữ liệu Pima Indians onset of diabetes.
# monitor training performance
from numpy import loadtxt
from XGBoost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=7)
# fit model on training data
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, verbose=True)
# make predictions for test data
predictions = model.predict(X_test)
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
Ở đây, ta sử dụng 67% dữ liệu cho việc train, 33% còn lại cho viêc đánh giá model. Error metric được tính toán tại cuối mỗi vòng lặp (sau khi mỗi boosted tree được thêm vào model). Cuối cùng, độ chính xác của model được in ra.
Kết quả hiển thị trên màn hình như sau:
[0] validation_0-error:0.28347
[1] validation_0-error:0.25984
[2] validation_0-error:0.25591
[3] validation_0-error:0.24803
[4] validation_0-error:0.24409
[5] validation_0-error:0.24803
[6] validation_0-error:0.25591
[7] validation_0-error:0.24803
[8] validation_0-error:0.25591
[9] validation_0-error:0.24409
...
[89] validation_0-error:0.26378
[90] validation_0-error:0.27165
[91] validation_0-error:0.26772
[92] validation_0-error:0.27165
[93] validation_0-error:0.26378
[94] validation_0-error:0.27165
[95] validation_0-error:0.26378
[96] validation_0-error:0.25984
[97] validation_0-error:0.26378
[98] validation_0-error:0.25984
[99] validation_0-error:0.25984
Accuracy: 74.02%
Quan sát kết quả ta thấy performance của model không thay dổi quá nhiều trong suốt quá trình train. Thậm chí đến cuối quá trình, performance còn kém hơn so với nửa đầu.
Để có cái nhìn tường minh hơn, hãy thể hiện performance của model trên đồ thị.
Ta sẽ monitor performace của model trên cả train set và test set:
eval_set = [(X_train, y_train), (X_test, y_test)]
model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, verbose=True)
Performance của model trên mỗi tập evaluation set được lưu bởi model sau khi train kết thúc. Để truy cập giá trị performace này, sử dụng hàm model.evals_result():
results = model.evals_result()
print(results)
Kết quả in ra sẽ giống như sau:
{
'validation_0': {'error': [0.259843, 0.26378, 0.26378, ...]},
'validation_1': {'error': [0.22179, 0.202335, 0.196498, ...]}
}
validation_0 và validation_1 theo thứ tự tương ứng với hai tập validation set mà ta đã định nghĩa trong tham số eval_set khi gọi hàm fit().
Error metric được truy cập như sau:
results['validation_0']['error']
results['validation_1']['error']
Thêm nữa, bạn có thể lựa chọn nhiều metrics để đánh giá model bằng cách cung cấp một mảng các giá trị metric tới tham số eval_metric của hàm fit(). Giá trị của các metric thu được sau đó đươc thể hiện trên đồ thị, gọi là learning curve.
Code đầy đủ dưới đây minh họa việc thu thập giá tị của các metrics và thể hiện trên learning curve:
# plot learning curve
from numpy import loadtxt
from XGBoost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from matplotlib import pyplot
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=7)
# fit model on training data
model = XGBClassifier()
eval_set = [(X_train, y_train), (X_test, y_test)]
model.fit(X_train, y_train, eval_metric=["error", "logloss"], eval_set=eval_set,
verbose=True)
# make predictions for test data
predictions = model.predict(X_test)
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
# retrieve performance metrics
results = model.evals_result()
epochs = len(results['validation_0']['error'])
x_axis = range(0, epochs)
# plot log loss
fig, ax = pyplot.subplots()
ax.plot(x_axis, results['validation_0']['logloss'], label='Train')
ax.plot(x_axis, results['validation_1']['logloss'], label='Test')
ax.legend()
pyplot.ylabel('Log Loss')
pyplot.title('XGBoost Log Loss')
pyplot.show()
# plot classification error
fig, ax = pyplot.subplots()
ax.plot(x_axis, results['validation_0']['error'], label='Train')
ax.plot(x_axis, results['validation_1']['error'], label='Test')
ax.legend()
pyplot.ylabel('Classification Error')
pyplot.title('XGBoost Classification Error')
pyplot.show()
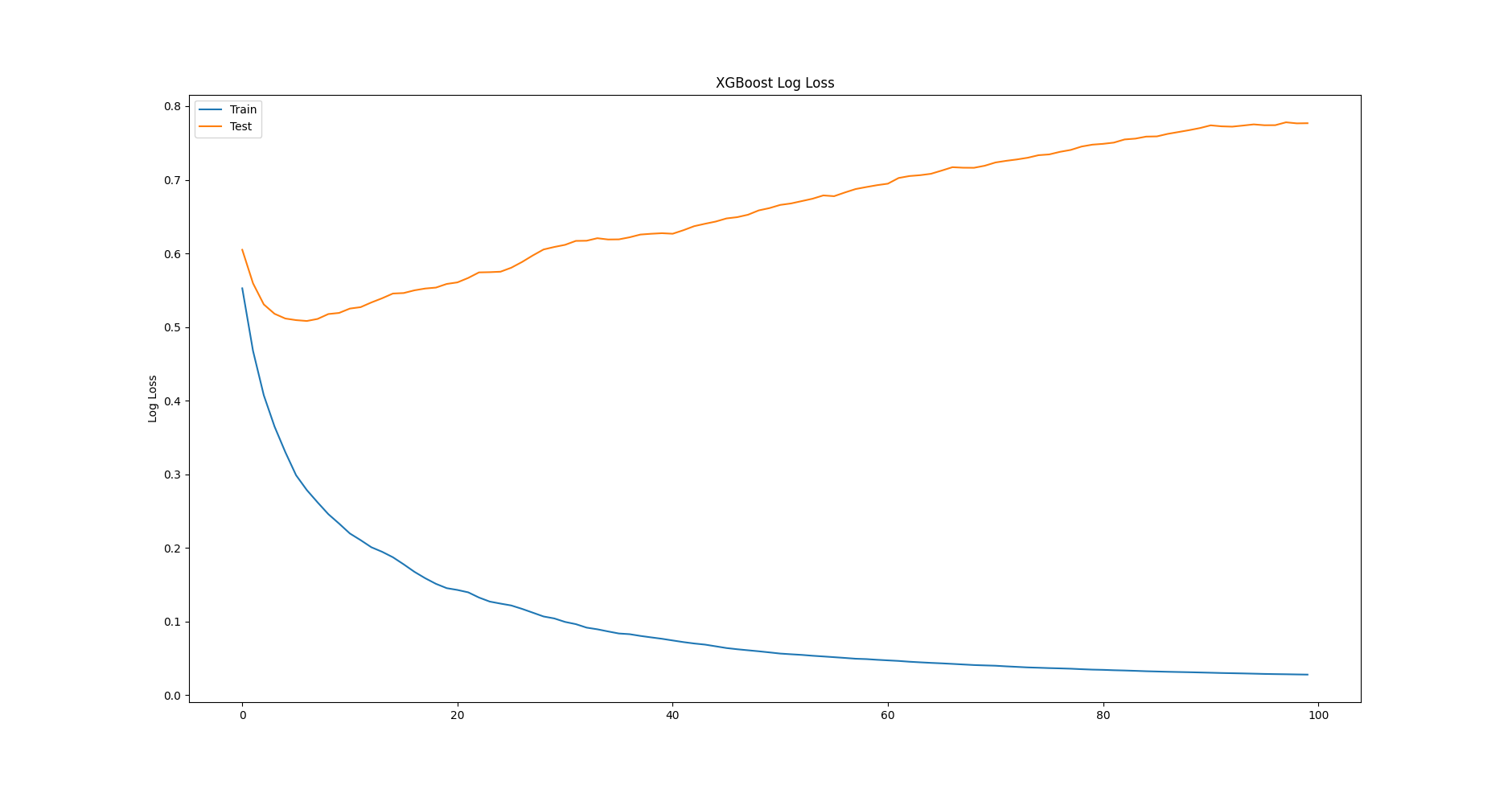
Chạy code trên, error và logloss metric trên cả 2 tập train set và test set được in ra. Ta có thể bỏ qua điều này bằng cách truyền giá trị False (giá trị mặc định) cho tham sô verbose khi gọi hàm fit(). Hai đồ thị được tạo ra. Đồ thị đầu tiên thể hiện logloss của XGBoost model đối với mỗi epoch (iteration) trong quá trình train.
Đồ thị thứ 2 hiển thị error metric của mỗi epoch.
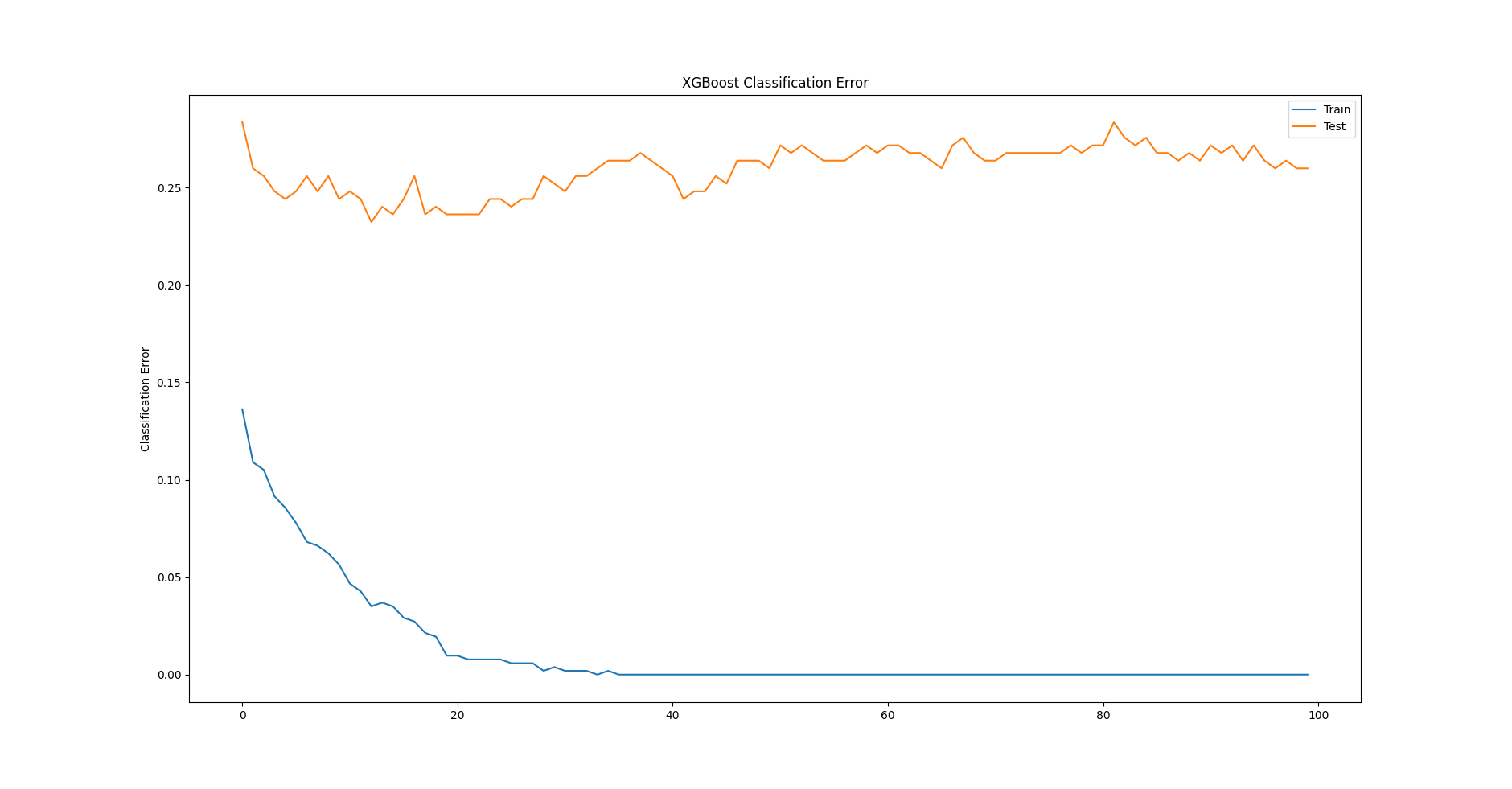
Quan sát cả 2 đồ thị trên ta có một nhận xét rằng, nếu dừng train sớm hơn tại epoch < 100 thì performace của model sẽ tốt hơn. Đây chính là tiền đề của kỹ thuật early stopping mà chúng ta sẽ tìm hiểu ngay sau đây.
2. Cấu hình early stopping cho XGBoost model
Early stopping là một kỹ thuật khá phổ biến áp dụng cho các ML model phức tạp để tránh hiện tượng overfitting. Nó làm việc bằng cách monitor performance của model trên tập test set trong suốt quá trình train và buộc quá trình này dừng lại một khi performance của model không được cải thiện sau một số epochs nhất định.
Trên đồ thị learning curve, điểm bắt đầu overfitting là điể mà tại đó performace của model trên tập test set bắt đầu giảm trong khi performance của model trên tập train set vẫn tiếp tục tăng.
Để cấu hình early stopping cho XGBoost model, cần cung cấp thêm giá trị cho tham số early_stopping_rounds khi gọi hàm fit(). Ý nghĩa của nó là chỉ ra số lượng epochs mà quá trình húân luyện trải qua mà performance không có sự cải thiện nào.
Ví dụ:
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
Nếu có nhiều evaluation sets hoặc nhiều metrics được cung cấp, early stopping sẽ sử dụng cái cuối cùng trong danh sách.
Code đầy đủ cấu hình early stopping như bên dưới:
# early stopping
from numpy import loadtxt
from XGBoost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# fit model on training data
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# make predictions for test data
predictions = model.predict(X_test)
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
Kết quả chạy code:
[0] validation_0-logloss:0.60491
Will train until validation_0-logloss hasn't improved in 10 rounds.
[1] validation_0-logloss:0.55934
[2] validation_0-logloss:0.53068
[3] validation_0-logloss:0.51795
[4] validation_0-logloss:0.51153
[5] validation_0-logloss:0.50935
[6] validation_0-logloss:0.50818
[7] validation_0-logloss:0.51097
[8] validation_0-logloss:0.51760
[9] validation_0-logloss:0.51912
[10] validation_0-logloss:0.52503
[11] validation_0-logloss:0.52697
[12] validation_0-logloss:0.53335
[13] validation_0-logloss:0.53905
[14] validation_0-logloss:0.54546
[15] validation_0-logloss:0.54613
[16] validation_0-logloss:0.54982
Stopping. Best iteration:
[6] validation_0-logloss:0.50818
Accuracy: 74.41%
Quá trình train model dừng lại ở epoch 16 (gần với những gì mà chúng ta phán đoán dựa trên đồ thị learning curve) và model đạt được metric thấp nhất tại epoch 6. Việc chọn giá trị của tham số early_stopping_rounds thường dựa vào quan sát trên đồ thị learning curve. Nếu bạn không biết thì có thể chọn giá trị mặc định là 10.
3. Kết luận
Trong bài viết này, chúng ta đã tìm hiểu cách monitor performance của XGBoost model trong quá trình train và cấu hình early stopping để hạn chế hiện tượng overfitting của model.
Ở bài viết tiếp theo chúng ta sẽ tìm hiểu cách cấu hình XGBoost model để tận dụng hết tài nguyên của phần cứng khi train model và khi sử model để dự đoán. Hãy cùng đón đọc! :)
Toàn bộ source code của bài này các bạn có thể tham khảo trên github cá nhân của mình tại github.
Bài viết có tham khảo tại tham khảo.