Ai sẽ nghỉ việc ???

Tiếp tục bàn về câu chuyện nhân viên nghỉ việc, và đây là phần 2.
Trong phần 2 này, chúng ta sẽ cùng nhau xây dựng một ML model để dự đoán xem liệu một nhân viên nào đó có khả năng nghỉ việc hay không?
1. Phương pháp tiếp cận khi xây dựng một ML model
Có một vài phương pháp khác nhau giúp ta có thể xây dựng được một ML model tốt. Hai trong số những phương pháp đó, tương đối phổ biến và rất hay đuợc các Data Scientist trên thế giới sử dụng, đó là:
- Top-Down method:
Trong phương pháp này, một model sẽ được lựa chọn từ đầu, sau đó tinh chỉnh dần dần dựa theo các đặc tính của dữ liệu, các tham số của model, … cho đến khi nào đạt được model đủ đáp ứng điều kiện bài toán.
- P2P Comparison method:
Ngược lại với phương pháp trên, P2P Comparison không chọn cố định ngay một model nào từ đầu, mà sẽ so sánh, đánh giá để đưa ra kết luận. Kết quả của lần đánh giá đầu tiên được gọi là Base model. Model được lựa chọn sau đó sẽ được tinh chỉnh dần dần để ngày càng tốt hơn. Trong quá trình tinh chỉnh đó, nó luôn được so sánh với Base model để đảm bảo kết quả sau luôn tối ưu hơn kết quả trước.
Nói chung thì phương pháp thứ 2 tỏ ra ưu việt hơn phương pháp thứ nhất trong đa số trường hợp, mặc dù nó sẽ làm ta mất nhiều thời gian hơn. Bởi vì trong phương pháp 1, nếu model được chọn từ đầu mà sai thì sẽ dẫn đến kết quả sau cùng cũng sai. Việc lựa chọn này đa số dựa vào kinh nghiệm của các Data Scientist.
Trong bài này, mình sẽ áp dụng phương pháp thứ 2 đề thực hiện.
2. Đánh giá, lựa chọn Base model
2.1 Đọc và kiểm tra dữ liệu
Trước tiên ta sẽ đọc vào bộ dữ liệu:
df_data = pd.read_csv('dataset/HR_comma_sep.csv')
df_data.head()

Xem xét một số thông tin về dữ liệu:
df_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14999 entries, 0 to 14998
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 satisfaction_level 14999 non-null float64
1 last_evaluation 14999 non-null float64
2 number_project 14999 non-null int64
3 average_montly_hours 14999 non-null int64
4 time_spend_company 14999 non-null int64
5 Work_accident 14999 non-null int64
6 left 14999 non-null int64
7 promotion_last_5years 14999 non-null int64
8 Department 14999 non-null object
9 salary 14999 non-null object
dtypes: float64(2), int64(6), object(2)
memory usage: 1.1+ MB
Chúng ta đã biết từ bài trước rằng bộ dữ liệu bao gồm 14999 mẫu, và không có missing values. Ở đây, ta quan tâm thêm một thông tin nữa đó là có 2 features đang ở dạng categorical, đó là Department và salary. Để các ML model có thể học được thì chúng phải được chuyển sang dạng numerical. Chi tiết thực hiện ở phần sau.
2.2 Data Preparation
Phần này sẽ bao gồm 2 việc:
a, Phân chia dữ liệu
Trước tiên, cần tách dữ liệu thành 2 phần khác nhau: input (features) và output (target).
# separate input (features) and output (target)
y = df_data[['left']]
X = df_data.drop('left', axis=1)
Tiếp theo, lại chia tiếp mỗi phần thành 2 tập riêng biệt: Train và Test
# separate train set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.25)
print(X_train.shape)
print(X_test.shape)
Ở đây, mình chia theo tỷ lệ Train:Test = 75%:25%. Kết quả là ta có 11249 mẫu trong tập Train và 3750 mẫu trong tập Test.
b, Mã hóa các Categorical features
Như đã nói ở trên, các features ở dạng categorical cần phải được chuyển sang dạng numerical (mã hóa) thì các ML models mới có thể học được.
Có một vài phương pháp trong thư viện Scikit-learn giúp ta thực hiện việc này như OrdinalEncoder, OneHotEncoder, … Mình sẽ chọn OrdinalEncoder.
# encode categorical features
encoder = OrdinalEncoder()
encoder.fit(X_train[['salary', 'Department']])
X_train[['salary', 'Department']] = encoder.transform(X_train[['salary', 'Department']])
X_test[['salary', 'Department']] = encoder.transform(X_test[['salary', 'Department']])
Sau khi khởi tạo instance của OrdinalEncoder thì ta sẽ dùng nó để fit trên toàn bộ tập Train đối với 2 categorical features. Cuối cùng, sử dụng instance đó để thực hiện phép transform để sinh ra dữ liệu mới tương ứng.
2 công việc trên đây là yêu cầu tối thiểu, bắt buộc để có thể chuyển sang bước huấn luyện, đánh giá model.
2.3 Đánh giá các models
Để chọn được model phù hợp nhất trong số các models có thể, chúng ta sẽ gom tất cả chúng lại và lần lượt đánh giá chúng. Model nào cho kết quả cao nhất thì sẽ được chọn.
- Định nghĩa các models:
# create a dictionary of models
model_dict = {
'LogisticRegression': LogisticRegression(max_iter=1000),
'GaussianNB': GaussianNB(),
'KNeighborsClassifier': KNeighborsClassifier(n_neighbors=1),
'DecisionTreeClassifier': DecisionTreeClassifier(min_samples_split=25),
'SVM': svm.SVC(kernel='rbf',probability=False),
'RandomForestClassifier': RandomForestClassifier(n_estimators = 10, min_samples_split=2, max_depth=30),
}
Vì đang xác định Base model nên chúng ta sử dụng các giá trị mặc định của các hyper-parameters.
- Đánh giá các models:
model_scores = []
model_names = []
for name, model in model_dict.items():
model.fit(X_train, np.ravel(y_train))
prediction = model.predict(X_test)
acc_score = accuracy_score(y_test, prediction)
model_scores.append(acc_score)
model_names.append(name)
print('*'*10 + name + '*'*10 + ': {}'.format(acc_score))
Phương pháp đánh giá ở đây là huấn luyện các models trên tập Train, sau đó tính toán độ chính xác thông qua việc dự đoán trên tập Test. Kết quả thu được như sau:
**********LogisticRegression**********: 0.7586666666666667
**********GaussianNB**********: 0.7994666666666667
**********KNeighborsClassifier**********: 0.9538666666666666
**********DecisionTreeClassifier**********: 0.9744
**********SVM**********: 0.7834666666666666
**********RandomForestClassifier**********: 0.9864
Ta thấy, RandomForestClassifier đạt được độ chính xác cao nhất, 98.64%. Do đó, RandomForestClassifier với 98.64% độ chính xác là Base model của chúng ta.
3. Tối ưu hóa model
Tối ưu hóa hay tinh chỉnh model là việc vận dụng các kỹ thuật xử lý dữ liệu, các kỹ thuật lựa chọn tham số để làm sao thu được model tốt nhất có thể. Tùy từng bài toán mà ta áp dụng một trong 2 loại kỹ thuật trên, hoặc có thể áp dụng đồng thời cả 2 loại đó.
3.1 Xử lý dữ liệu
Dữ liệu input ảnh hưởng khá nhiều đến chất lượng của model. Một số kỹ thuật thường được sử dụng để xử lý dữ liệu như: Remove outlier, Impute Missing values, Scale values, Balance data, Feature Selection, … Mỗi kỹ thuật sẽ giải quyết một vấn đề của dữ liệu.
a, Remove outlier
Outlier còn gọi là dữ liệu ngoại lệ, hay dữ liệu bất thường. Để kiểm tra xem có tồn tại Outlier trong các numberical features hay không, ta sẽ vẽ đồ thị Distplot của chúng.
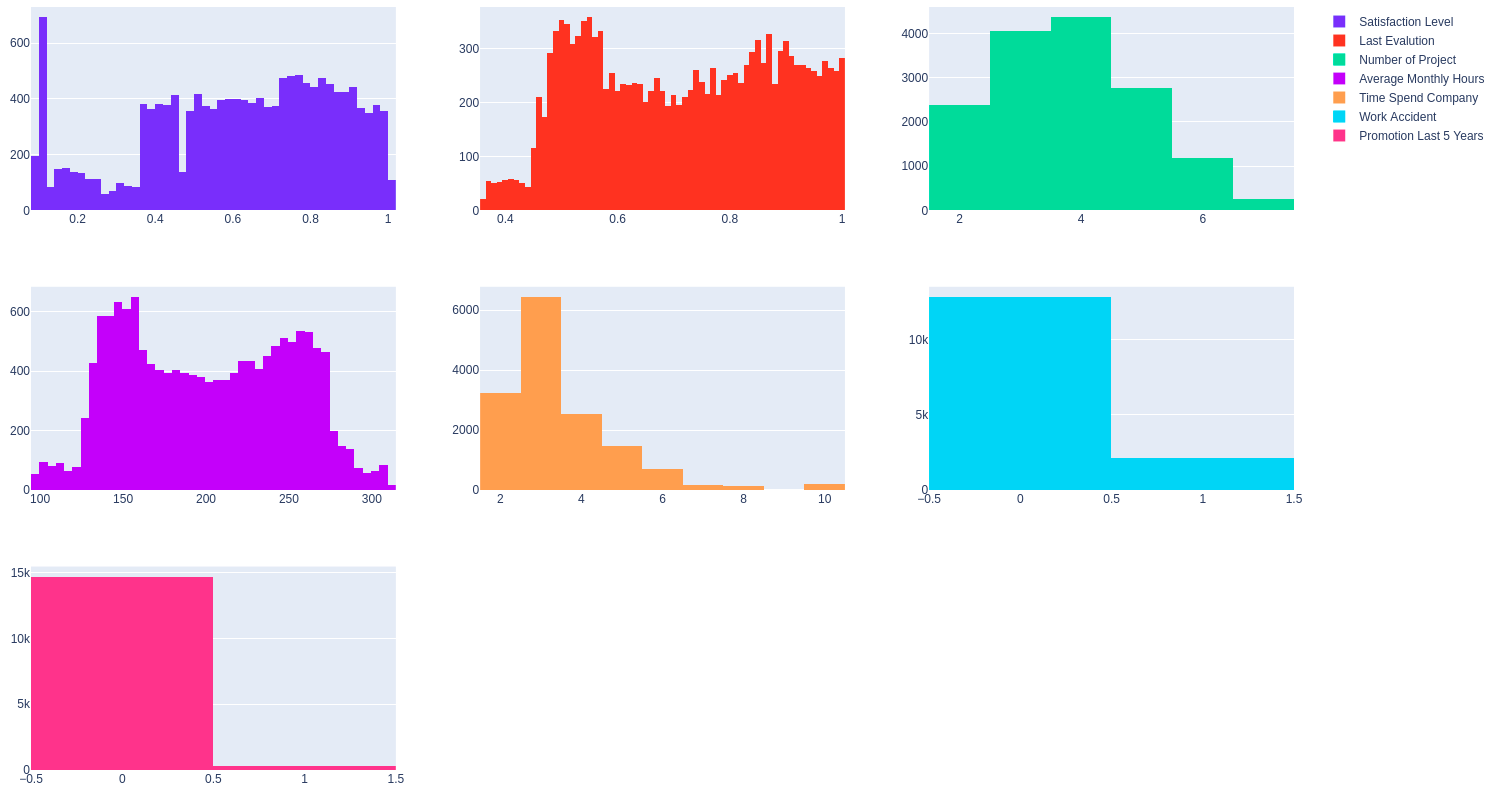
Quan sát đồ thị Displot ta thấy, các giá trị của các giá trị đều nằm trong các phạm vi hợp lệ nên không tồn tại Outlier ở đây.
Còn đối với các categorical features, ta sử dụng phương pháp thống kê để kiểm tra:
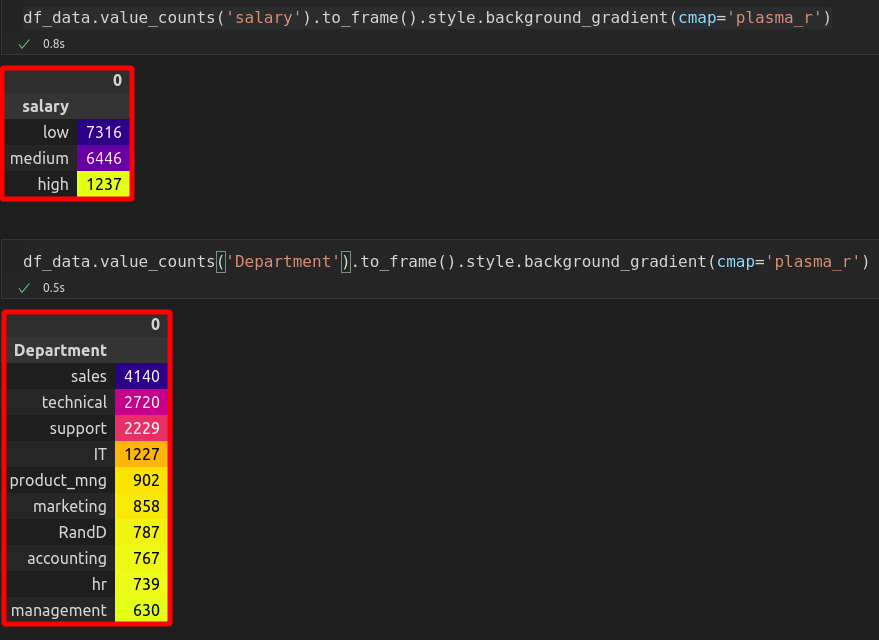
Cũng không có Outlier nào ở đây, tất cả các giá trị đều hợp lệ.
Tóm lại là chúng ta không cần áp dụng kỹ thuật Remove Outlier nào cho bộ dữ liệu này.
b, Impute Missing values
Ở phần đầu ta đã biết rằng không tồn tại Missing values, nên cũng không cần áp dụng kỹ thuật Impute Missing values.
c, Balance data
Kiểm tra xem có tồn tại hiện tượng Imbalance data hay không?
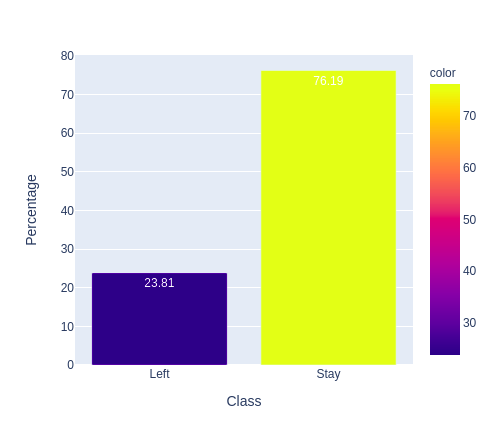
Rõ rằng là có tồn tại Imbalance data khi mà tỉ lệ giữa 2 lớp khá chệnh lệch, 23.81% - 76.19%. Để giải quyết vấn đề này, ta có nhiều cách: Oversample, Undersample, Classes Weight, … Mỗi cách lại có các thuật toán khác nhau như SMOTE, SMOTENC, …
Trong bài này, ta sẽ sử dụng phương pháp Class Weight. Cách thực hiện rất đơn giản, khi khai báo model, ta chỉ cần thêm tham số class_weight=‘balanced’.
d, Scale data
Nếu giá trị của các features có sự khác biệt lớn về phạm vi, khi huấn luyện, model sẽ có xu hướng thiên vị hơn cho các features có giá trị lớn. Điều này làm giảm độ tin cậy của model. Scale data là phương pháp loại bỏ hiện tượng này, ở đó, các giá trị được đưa về cùng một phạm vi, thường là từ 0 đến 1.
Có 2 kỹ thuật hay được sử dụng là Normalization và Standarlization. Mình sẽ áp dụng kỹ thuật Standarlization trong bài này.
Chi tiết hơn về các kỹ thuật xử lý và chuẩn bị dữ liệu, các bạn có thể xem thêm các bài viết về chủ đề Data Preparation của mình tại đây.
3.2 Huấn luyện models
Theo như phương pháp P2P Comparison thì ta sẽ chỉ đi tối ưu cho Base model, tức là RandomForestClassifier. Tuy nhiên, ở đây mình sẽ thử đánh giá lại toàn bộ các models sau khi đã áp dụng các kỹ thuật xử lý dữ liệu, xem liệu có gì thay đổi hay không?
# create a dictionary of models
model_dict = {
'LogisticRegression': LogisticRegression(max_iter=500, class_weight='balanced'),
'GaussianNB': GaussianNB(),
'KNeighborsClassifier': KNeighborsClassifier(),
'DecisionTreeClassifier': DecisionTreeClassifier(class_weight='balanced'),
'SVM': svm.SVC(class_weight='balanced'),
'RandomForestClassifier': RandomForestClassifier(class_weight='balanced'),
}
Ta vẫn khai báo danh sách các models như phần trước, có thay đổi một chút là thêm tham số class_weight=‘balanced’ như đã phân tích ở phần 3.1c. GaussianNB và KNeighborsClassifier là 2 models không hỗ trợ việc này.
Tổng hợp lại từ đầu thì ngoài Balance data, ta cần thực hiện 2 kỹ thuật xử lý dữ liệu sau: Encoder Categorical features và Scale data.
Thư viện Scikit-learn cung cấp cho chúng ta công cụ Pipeline giúp gom các phần xử lý này lại thành một pipeline. Về sau khi dự đoán trên mẫu dữ liệu mới, ta áp dụng đúng pipeline này cho mẫu đó thì sẽ đảm bảo dữ liệu test và dữ liệu train được xử lý giống hệt nhau.
# define ColumnTransformer to perform transform data
trans_list = [('cat', OneHotEncoder(), categorical_ix), ('num', StandardScaler(), numerical_ix)]
col_trans = ColumnTransformer(transformers=trans_list)
...
for name, model in model_dict.items():
pipeline = Pipeline(steps=[('preparation', col_trans), ('model', model)])
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=10, random_state=42)
scores = cross_val_score(pipeline, X, np.ravel(y), scoring='accuracy', cv=cv, n_jobs=-1)
...
Và để việc đánh giá các models được khách quan hơn, mình sẽ sử dụng phương pháp Cross-validation.
Kết quả thực hiện:
**********LogisticRegression**********
0.7598638247720703
0.00971910352647794
**********GaussianNB**********
0.6595039092728485
0.014364290029621824
**********KNeighborsClassifier**********
0.9455297175895042
0.005250667653662472
**********DecisionTreeClassifier**********
0.9819988258839224
0.003200161402127842
**********SVM**********
0.9559569134978875
0.004905774407557175
**********RandomForestClassifier**********
0.9913393907049142
0.0022560674653345505
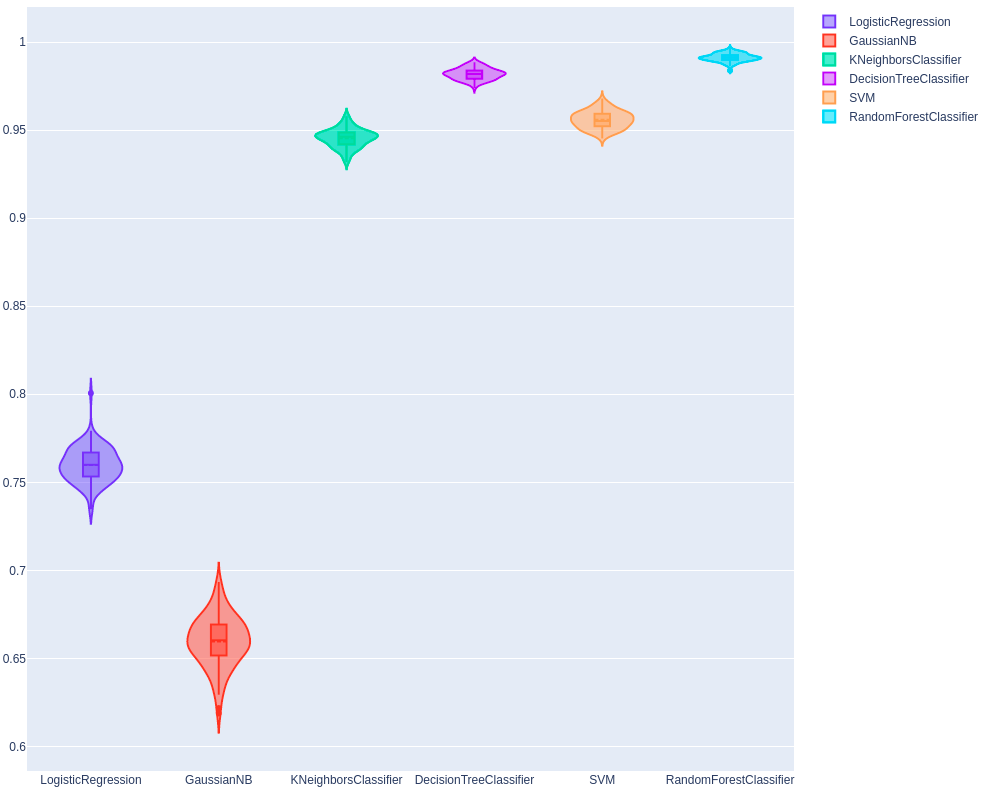
Ta thấy, hầu hết các models đều có sự cải thiện về độ chính xác so với phiên bản Base của chúng. Riêng đối với model RandomForestClassifier thì độ chính xác tăng từ 98.64% lên 99.14%.
3.3 Tune hyper-parameters cho RandomForestClassifier model
Mỗi model đều có một số siêu tham số có thể cấu hình được để thay đổi cách thức học của model đó. Và chúng ta thường không thể biết được chính xác giá trị nào của các tham số đó làm cho model đạt được kết quả cao nhất.
Có một vài phương pháp giúp chúng ta tự động hóa việc này: Grid Search, Random Search, … Các phương pháp đều có chung ý tưởng là từ một tập hợp các giá trị có thể có có từng tham số, các kết hợp giữa chúng được tạo ra và áp dụng vào việc huấn luyện model. Sự kết hợp nào mang lại kết quả tốt nhất sẽ được chọn.
Từ phần trên chúng ta đã biết rằng RandomForestClassifier là model đang có độ chính xác cao nhất. Ta sẽ thực hiện Tuning các Hyper-parameters của model này xem liệu có thể thu được kết quả tốt hơn hay không?
rf_model = RandomForestClassifier(random_state=42, class_weight='balanced')
pipeline = Pipeline(steps=[('preparation', col_trans), ('rf', rf_model)])
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=10, random_state=42)
Phần khai báo model và chuẩn bị dữ liệu trong pipeline vẫn giữ nguyên như trên.
Phần quan trọng ở đây là bước lựa chọn tham số và các giá trị có thể có của chúng để đưa vào search.
param_grid = {'rf__n_estimators': np.arange(50, 150, 10),
'rf__max_features': ['auto', 'sqrt', 'log2'],
'rf__max_depth': np.arange(10, 100, 10),
'rf__min_samples_split': [2, 5, 10],
'rf__min_samples_leaf': [1, 2, 4],
'rf__criterion' :['gini', 'entropy'],
'rf__bootstrap': [True, False]}
Bạn có thể lựa chọn tùy ý, càng nhiều giá trị thì thời gian huấn luyện sẽ càng lâu. Tuy nhiên, cũng không nên chọn các giá trị quá gần nhau, vì mức độ ảnh hưởng của chúng đến model không có sự khác biệt rõ rệt. Tốt nhất là mỗi giá trị nên cách nhau 5 đến 10. VD: rf__n_estimators': np.arange(50, 150, 10),.
Bước cuối cùng là khai báo GridSeach và sử dụng nó để huấn luyện model:
grid_pipeline = GridSearchCV(pipeline, param_grid, scoring= 'accuracy', n_jobs=-1, cv=cv)
results = grid_pipeline.fit(X, np.ravel(y))
print( ' Best Mean Accuracy: %.3f ' % results.best_score_)
print( ' Best Config: %s ' % results.best_params_)
Sau khoảng 25h train liên tục trên máy tính core i7, 64GB Ram, RTX 2080 (8GB) thì mình thu được kết quả:
Best Mean Accuracy: 0.992
Best Config: {'rf__bootstrap': False, 'rf__criterion': 'entropy', 'rf__max_depth': 30, 'rf__max_features': 'auto', 'rf__min_samples_leaf': 1, 'rf__min_samples_split': 2, 'rf__n_estimators': 70}
Độ chính xác cao nhất đạt được là 99.20%, cao hơn một chút so với con số 99.13% ở trên. Các giá trị của các tham số tương ứng cũng được liệt kê. Về sau, nếu muốn huấn luyện lại model, ta có thể sử dụng luôn bộ giá trị này.
4. Sử dụng model để dự đoán
4.1 Dự đoán trên tập Test
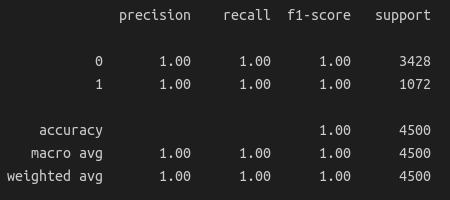
Sau khi có được model tốt nhất, ta thử sử dụng nó để dự đoán các mẫu có trong tập Test, và hiển thị kết quả dưới dạng classification report và confusion matrix:
# actually, test set is used to train model. So, this is not really valuable.
y_pred = grid_pipeline.predict(X_test)
# create confusion matrix
cm = confusion_matrix(y_test, y_pred)
# display classification report
print(classification_report(y_test, y_pred))
# display confusion matrix
fig, ax = plot_confusion_matrix(conf_mat=cm,
show_absolute=True,
show_normed=True,
colorbar=True)
plt.show()
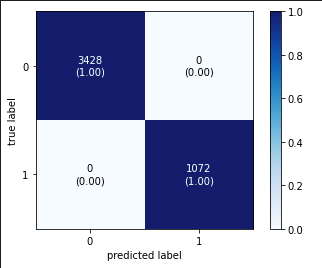
Ta thấy trên tập Test, độ chính xác đạt được là tuyệt đối, 100%. Điều này là bởi vì thực ra trong quá trình huấn luyện model, các mẫu trong tập Test cũng đã được đưa vào học thông qua cơ chế Cross-validation.
4.2 Dự đoán trên mẫu dữ liệu mới
Nếu có một mẫu dữ liệu mới thì sao, ta cần làm gì để đưa vào model dự đoán?
Đầu tiên, cần đưa mẫu dữ liệu về dạng giống như lúc huấn luyện:
# create new sample
new_sample = [[0.41, 0.43, 3, 153, 3, 1, 1, 'sales', 'medium']]
df_new_sample = pd.DataFrame(new_sample)
df_new_sample.columns = ['satisfaction_level', 'last_evaluation', 'number_project', 'average_montly_hours', 'time_spend_company', 'Work_accident', 'promotion_last_5years', 'Department', 'salary']
Đến bước dự đoán, ta có thể có 2 cách:
- Dự đoán trực tiếp ra nhãn của mẫu:
# get only predicted class
class_pred = grid_pipeline.predict(df_new_sample)[0]
print('Class = {}'.format(class_pred))
Kết quả:
Class = 0
- Dự đoán xác suất của mỗi class:
# get predicted class and it's probably coresponding
pd.DataFrame(grid_pipeline.predict_proba(df_new_sample)*100, columns=grid_pipeline.classes_)
Kết quả:
0 1
0 98.571429 1.428571
Xác suất của class 0 là 98.57%, còn của class 1 là 1.42%.
5. Save và Load model
Model đã huấn luyện nên được lưu lại để có thể sử dụng lại về sau.
5.1 Save model
Để lưu model, ta có thể sử dụng một trong 2 thư viện là pickle hoặc joblib:
# way 1
pickle.dump(grid_pipeline, open('model.pkl', 'wb'))
# pickle.dump(grid_pipeline.best_estimator_, open('model.pkl', 'wb'))
# way 2, same result as way 1
joblib.dump(grid_pipeline, 'model.pkl')
# joblib.dump(grid_pipeline.best_estimator_, 'model.pkl')
Để load model:
# way 1
model = pickle.load(open('model.pkl', 'rb'))
# way 2, same result as way 1
model = joblib.load('model.pkl')
Kiểm tra lại model vừa load bằng cách sử dụng nó để tạo một dự đoán:
# use loaded model to make prediction
class_id = model.predict(df_new_sample)[0]
print(class_id)
Kết quả: 0
Như vậy là quá trình save và load model được thực hiện chính xác.
6. Kết luận
Trong phần thứ 2 của bài toán phân tích dữ liệu nhân viên, chúng ta đã cùng nhau xây dựng được một ML model tối ưu để có thể dự đoán liệu một nhân viên có khả năng nghỉ việc hay là không? Lần lượt từng bước tiếp cận, từ xây dựng Base model, xử lý dữ liệu, đến việc tối ưu model đều đã được trình bày chi tiết. Hi vọng là các bạn có thể nắm bắt được ý tưởng của mình.
Toàn bộ code của bài này, các bạn có thể tham khảo tại đây.