Tại sao nhân viên của bạn lại nghỉ việc?

Ngành IT là một trong số các ngành có tỉ lệ cạnh tranh về mặt nhân sự tương đối cao hiện nay. Trong bối cảnh nhu cầu tuyển dụng của các công ty rất lớn, nhưng số lượng ứng viên chưa đáp ứng đủ thì các công ty luôn phải tìm mọi cách thu hút và giữ chân nhân tài để phục vụ cho mục tiêu tăng trưởng và phát triển của mình. Là chủ doanh nghiệp hay trưởng bộ phận nhân sự, bạn luôn phải trả lời 2 câu hỏi:
- Tại sao nhân viên lại nghỉ việc?
- Có thể dự đoán trước được nhân viên nào sẽ nghỉ việc hay không?
Chúng ta sẽ cùng đi tìm trả lời cho 2 câu hỏi đó bằng việc phân tích dữ liệu thực tế một cách khoa học. Mình sẽ đi phân tích các nguyên nhân có thể dẫn đến quyết định đi hay ở của một nhân viên, sau đó sẽ xây dựng một ML model để dự đoán khả năng nghỉ việc của nhân viên đó.
Vì nội dung cần trình bày khá dài nên mình quyết định chia thành 2 phần:
- Phần 1 (Tuần này): Trả lời câu hỏi số 1.
- Phần 2 (Tuần tiếp theo): Trả lời câu hỏi số 2.
OK, let’s go! Chúng ta sẽ đi luôn vào bài viết của tuần này.
1. Chuẩn bị và khảo sát dữ liệu
1.1 Chuẩn bị dữ liệu
Bộ dữ liệu chúng ta sử dụng trong bài hôm nay có tên là *HR_ comma_sep.csv*, được cung cấp bởi nền tảng Kaggle. Download nó tại đây. Nó được tạo thành bởi cuộc khảo sát của khoảng 15.000 nhân viên đến từ các công ty khác nhau trên toàn thế giới. Các thông tin của nó được mô tả trong bảng dưới đây:
| STT | Tên Features | Ý Nghĩa |
|---|---|---|
| 1 | satisfaction_level | Mức độ thỏa mãn nói chung của nhân viên, có giá trị từ 0-1 |
| 2 | last_evaluation | Kết quả đánh giá gần đây nhất của quản lý dành cho nhân viê đó, có giá trị 0-1 |
| 3 | number_project | Số lượng dự án mà nhân viên đã và đang tham gia. |
| 4 | average_montly_hourse | Số giờ làm việc trung bình trong 1 tháng của nhân viên |
| 5 | time_spend_company | Số năm làm viêc tại công ty của nhân viên |
| 6 | Work_accident | Nhân viên có gặp sự cố, tai nạn gì trong quá trình làm viện tại công ty hay không? 1 - accident, 0 - no accident |
| 7 | left | 0 - nhân viên ở lại làm việc tại công ty, 1 - nhân viên nghỉ việc tại công ty. Đây là thông tin mà ta sẽ cần dự đoán |
| 8 | promotion_last_5years | 0 - nhân viên không được thăng tiến trong vòng 5 năm gần đây, 1 - ngược lại |
| 9 | Department | Phòng/bộ phận làm việc của nhân viên |
| 10 | salary | Mức lương mà nhân viên được nhận tại thời điểm khảo sát, chia theo 3 mức: thấp, trung bình, cao |
1.2 Khảo sát dữ liệu
a, Đọc và hiển thị dữ liệu
Trước tiên, ta sẽ đọc vào dữ liệu và hiển thị một vài mẫu để bước đầu hình dung về nó:
df_data = pd.read_csv('dataset/HR_comma_sep.csv')
df_data.head()

b, Xem xét các thông tin thống kê của dữ liệu
print('Summary train data')
print('*'*50)
print(f'Shape: {df_data.shape}')
print('*'*50)
print(f'Data description: \n {df_data.describe()}')
print('*'*50)
Kết quả:
Summary train data
**************************************************
Shape: (14999, 10)
**************************************************
Data description:
satisfaction_level last_evaluation number_project \
count 14999.000000 14999.000000 14999.000000
mean 0.612834 0.716102 3.803054
std 0.248631 0.171169 1.232592
min 0.090000 0.360000 2.000000
25% 0.440000 0.560000 3.000000
50% 0.640000 0.720000 4.000000
75% 0.820000 0.870000 5.000000
max 1.000000 1.000000 7.000000
average_montly_hours time_spend_company Work_accident left \
count 14999.000000 14999.000000 14999.000000 14999.000000
mean 201.050337 3.498233 0.144610 0.238083
std 49.943099 1.460136 0.351719 0.425924
min 96.000000 2.000000 0.000000 0.000000
25% 156.000000 3.000000 0.000000 0.000000
50% 200.000000 3.000000 0.000000 0.000000
75% 245.000000 4.000000 0.000000 0.000000
max 310.000000 10.000000 1.000000 1.000000
promotion_last_5years
count 14999.000000
mean 0.021268
std 0.144281
min 0.000000
25% 0.000000
50% 0.000000
75% 0.000000
max 1.000000
**************************************************
Chính xác là có 14.999 mẫu dữ liệu. Ta có thể lướt qua các giá trị thống kê như mean, std, min, max, quantile, … của các features dạng numerical để sơ bộ nắm bắt được chúng.
c, Kiểm tra xem có giá trị nào bất thường hay không?
print('--- Check feature by feature ---')
print('*'*50)
for fe in df_data.columns:
print('-'*20)
print(df_data[fe].value_counts())
Kết quả:
--- Check feature by feature ---
**************************************************
--------------------
0.10 358
0.11 335
0.74 257
0.77 252
0.84 247
...
0.25 34
0.28 31
0.27 30
0.26 30
0.12 30
Name: satisfaction_level, Length: 92, dtype: int64
--------------------
0.55 358
0.50 353
0.54 350
0.51 345
0.57 333
...
0.39 52
0.43 50
0.38 50
0.44 44
0.36 22
Name: last_evaluation, Length: 65, dtype: int64
--------------------
4 4365
3 4055
5 2761
2 2388
6 1174
7 256
Name: number_project, dtype: int64
--------------------
135 153
156 153
149 148
151 147
160 136
...
297 7
288 6
299 6
96 6
303 6
Name: average_montly_hours, Length: 215, dtype: int64
--------------------
3 6443
2 3244
4 2557
5 1473
6 718
10 214
7 188
8 162
Name: time_spend_company, dtype: int64
--------------------
0 12830
1 2169
Name: Work_accident, dtype: int64
--------------------
0 11428
1 3571
Name: left, dtype: int64
--------------------
0 14680
1 319
Name: promotion_last_5years, dtype: int64
--------------------
sales 4140
technical 2720
support 2229
IT 1227
product_mng 902
marketing 858
RandD 787
accounting 767
hr 739
management 630
Name: Department, dtype: int64
--------------------
low 7316
medium 6446
high 1237
Name: salary, dtype: int64
Bất thường ở đây tức là các giá trị tồn tại ở một dạng khác so với quy đinh. VD, đối với thông tin về mức lương, các giá trị quy định là low, medium, high. Nếu có một giá trị không nằm trong số các giá trị quy định kia thì đó là bất thường. Nếu có thì ta sẽ cần phải xử lý chúng.
Đối với bộ dữ liệu này, ta thấy không có giá trị nào bất thường.
c, Kiểm tra kiểu dữ liệu và xem có tồn tại missing value hay không?
print(f'Data information: {df_data.info()}')
Kết quả:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14999 entries, 0 to 14998
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 satisfaction_level 14999 non-null float64
1 last_evaluation 14999 non-null float64
2 number_project 14999 non-null int64
3 average_montly_hours 14999 non-null int64
4 time_spend_company 14999 non-null int64
5 Work_accident 14999 non-null int64
6 left 14999 non-null int64
7 promotion_last_5years 14999 non-null int64
8 Department 14999 non-null object
9 salary 14999 non-null object
dtypes: float64(2), int64(6), object(2)
memory usage: 1.1+ MB
Data information: None
Các features thuộc một trong 3 kiểu dữ liệu: float64, int64, hoặc object và không có missing value nào tồn tại. Có thể nói đây là bộ dataset khá lý tưởng.
2. Phân tích dữ liệu - Explore Data Analysis
Trong phần này, chúng ta sẽ đi phân tích chi tiết dữ liệu, đánh giá mức độ ảnh hưởng của từng thuộc tính để tìm ra cả trả lời cho câu hỏi: Đâu là nguyên nhân dẫn đến quyết định nghỉ việc hay không nghỉ việc của nhân viên?
2.1 Xem xét mối tương quan giữa các features
Để tính toán mức độ tương quan giữa các features với nhau, mà cụ thể trong bài toán này, ta muốn biết các mức độ ảnh hưởng của các yếu tố đến quyết định nghỉ việc hay tiếp tục làm việc tại công ty, ta có thể sử dụng biểu đồ Heatmap như sau:
# create corrrelation matrix
df_corr = df_data.corr()
df_corr_round = df_corr.round(3)
# draw headmap
fig = ff.create_annotated_heatmap(
z=df_corr_round.to_numpy(),
x=df_corr.columns.tolist(),
y=df_corr.columns.tolist(),
zmax=1, zmin=-1,
showscale=True,
hoverongaps=True,
colorscale='Viridis',
annotation_text=df_corr_round.to_numpy()
)
fig.update_layout(
margin = dict(t=10,r=10,b=10,l=10),
showlegend = False,
width = 800, height = 600
)
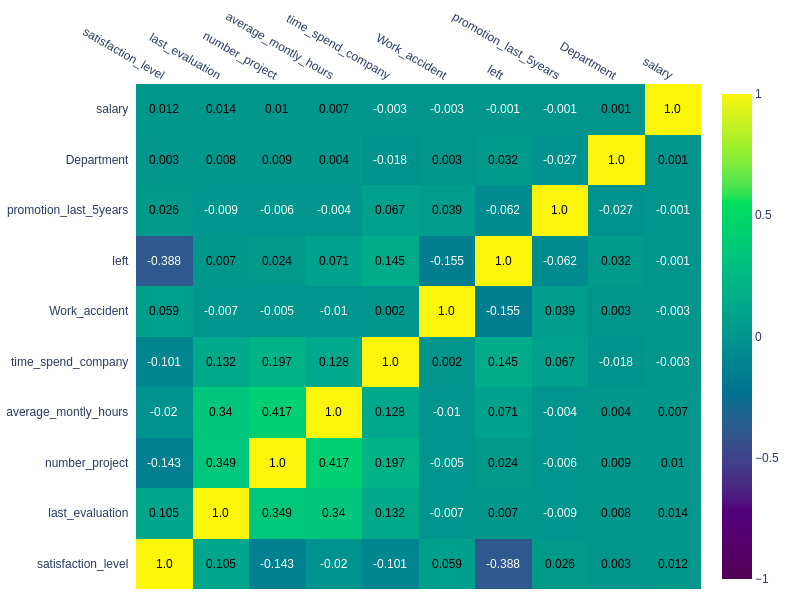
Dựa vào đây, ta thấy rằng mức độ thỏa mãn và quyết định nghỉ việc không thực sự có mối liên hệ nhiều (như ta nghĩ thông thường). Khi mô hình hóa dữ liệu, nếu cần thiết, ta có thể bỏ qua feature này.
Yếu tố ảnh hưởng nhiều nhất là số năm làm viêc tại công ty. Một cách chủ quan, ta có thể nhận định rằng những người làm càng lâu năm thì ít có khả năng nghỉ việc. Ta sẽ xem nhận xét này liệu có đúng hay không ở phần sau.
Các yếu tố còn lại, sắp xếp theo thứ tự giảm dần mức độ ảnh hưởng là: average_montly_hours, Department, number_project, last_evaluation, salary, promotion_last_5years, Work_accident.
2.2 Đánh giá sự ảnh hưởng của số năm làm việc tại công ty
fig = go.Figure(data=[
go.Bar(name='Stay', x=df_tsc.index, y=df_tsc[0], text=df_tsc[0], textposition='auto'),
go.Bar(name='Left', x=df_tsc.index, y=df_tsc[1], text=df_tsc[1], textposition='auto'),
])
# Change the bar mode
fig.update_layout(barmode='group',
title="Statistic number of working years of employees",
xaxis_title="Number of working years",
yaxis_title="Number of employees",
legend_title="Employee Type")
fig.show()
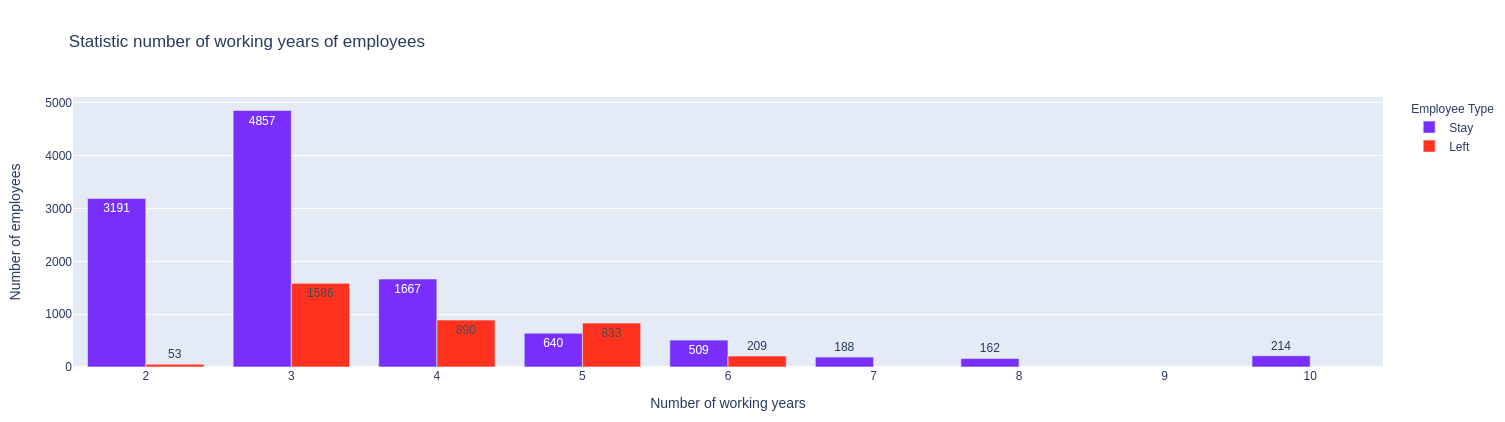
Nhận xét:
- Những người làm việc từ 2 năm trở xuống và 6 năm trở nên hầu như không nghỉ việc.
- Những người làm việc được từ 3-5 năm xác suất nghỉ việc cao hơn.
2.3 Đánh giá sự ảnh hưởng của thời gian làm việc trung bình trong tháng
# create dataframe with average monthly working hours and left information
df_mh = df_data[['average_montly_hours', 'left']]
# draw violin chart
fig = px.violin(
df_mh,
y="average_montly_hours",
color='left',
points='all',
box=True,
title='Influence of monthly working hours to left/stay company decision: 0 - Stay, 1 - Left',
labels={'average_montly_hours': 'Average Monthly Working Hours', 'left':'Left/Stay'})
fig.show()
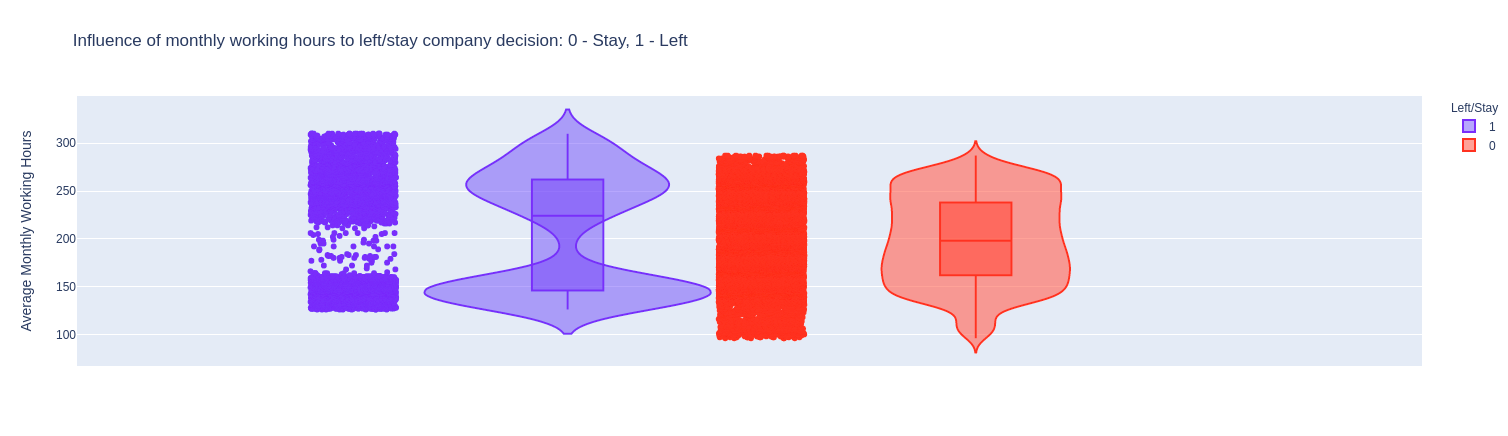
Nhận xét:
- Những người có số giờ làm việc trung bình trong tháng ở mức cao, > 220h(chắc là OT nhiều) có xu hướng nghi việc cao hơn.
- Những người có số giờ làm việc trung bình trong tháng ở mức thấp, < 160h cũng là những người hay nghỉ việc. Có lẽ vì công việc nhàm chán quá chăng?
- Những người có số giờ làm việc trung bình trong tháng ở mức vừa phải, 150-260h, ít có khả năng nghỉ viêc hơn.
2.3 So sánh tỉ lệ nghỉ việc giữa các phòng ban
# draw bar chart
fig = px.bar(df_dpm, y='Percent', text='Percent', color='Percent')
fig.show()
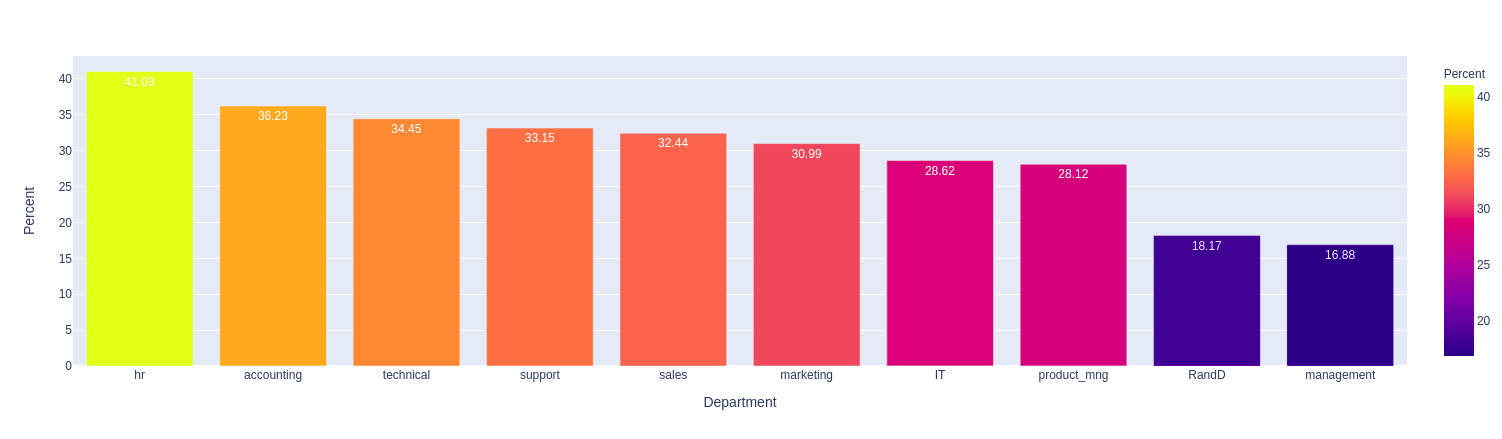
Nhận xét:
- HR là phòng ban có tỉ lệ nhân viên nghỉ việc cao nhất. Tỉ lệ thấp nhất là bộ phần Manager.
- Các phòng ban khác, thứ tự giảm dần như sau: Accounting, Technical, Support, Sales, Marketing, IT, Product Managerment, R&D.
2.4 Đánh giá sự ảnh hưởng của số lượng dự án trung bình 1 năm mà nhân viên đã làm
Trong dữ liệu gốc, không có thông tin về số lượng dự án trung bình mà nhân viên làm trong 1 năm. Thông tin này sẽ được tính bằng cách lấy tổng số dự án mà nhân viên đó đã làm, chia cho số năm nhân viên đó làm việc tại công ty. Sau đó lại phân thành 3 nhóm:
- Low: Từ 0-2 dự án một năm
- Medium: 2-4 dự án một năm
- High: > 4 dự án một năm
# draw bar chart
fig = go.Figure(data=[
go.Bar(name='Stay', x=df_project.index, y=df_project[0], text=df_project[0], textposition='auto'),
go.Bar(name='Left', x=df_project.index, y=df_project[1], text=df_project[1], textposition='auto'),
])
fig.update_layout(barmode='group',
title="Statistic average number of projects a year of employees",
xaxis_title="Number of projects",
yaxis_title="Number of employees",
legend_title="Employee Type")
fig.show()
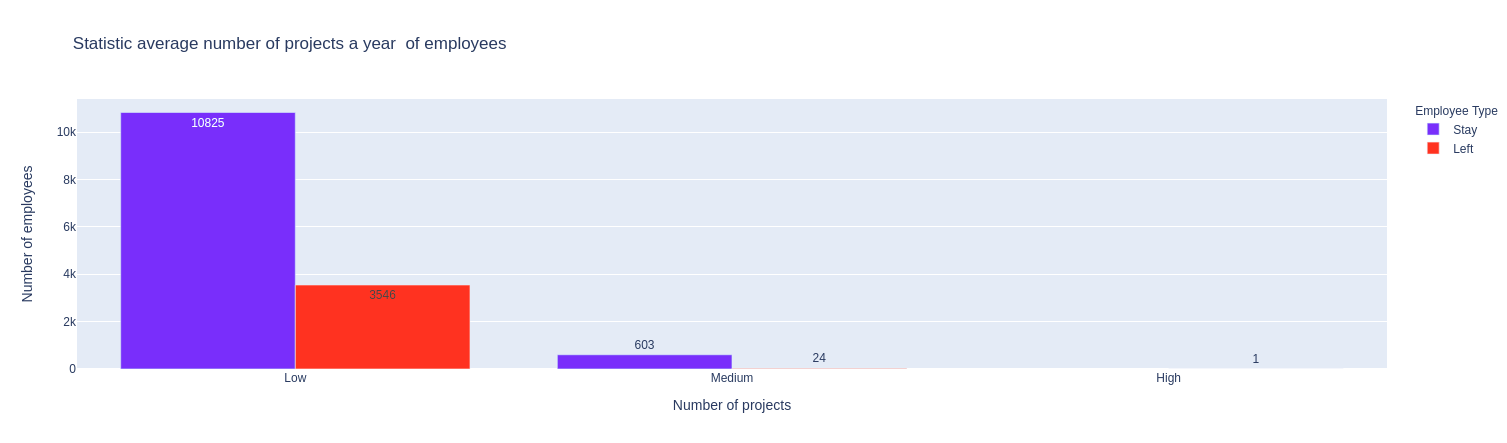
Nhận xét:
- Nhân viên mà đã tham gia trung bình 2 dự án 1 năm có xu hướng nghỉ việc nhiều hơn. Đây là nhóm nhân viên mới làm viêc ở công ty 1-2 năm.
- Nhân viên mà đã tham gia trung bình nhiều hơn 2 dự án 1 năm hầu như không nghỉ việc. Đây là nhóm nhân viên làm viêc lâu năm tại công ty.
2.5 Đánh giá sự ảnh hưởng của kết quả lần đánh giá ( checkpoint) nhân viên gần nhất
# create dataframe with last evaluation and left information
df_le = df_data[['last_evaluation', 'left']]
# draw violin chart
fig = px.violin(
df_le,
y="last_evaluation",
color='left',
points='all',
box=True,
labels={'last_evaluation': 'Last Evaluation', 'left': 'Left/Stay'},
title='Influence of last evaluation to left/stay company decision: 0 - Stay, 1 - Left')
fig.show()
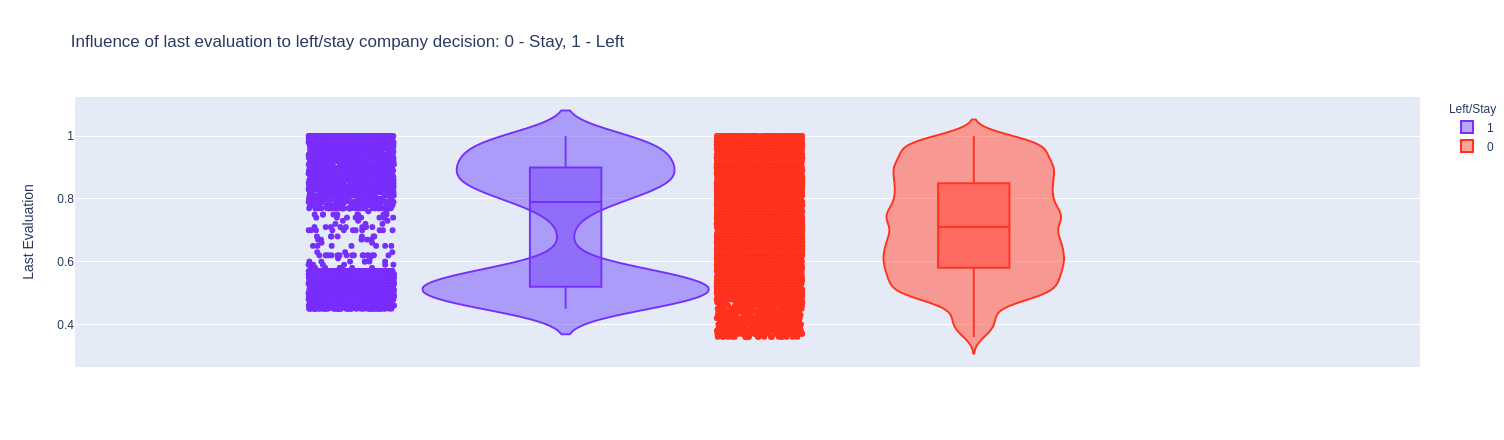
Nhận xét:
- Những người được đánh giá ở mức quá cao (> 0.8) và hoặc quá thấp (< 0.6) là những người dễ nghỉ việc. Có lẽ họ thấy rằng công việc hiện tại quá dễ dàng hoăc quá khó đôi với họ nên họ muốn thay đổi, tìm cơ hội mới.
- Những người được đánh giá ở mức trung bình thường sẽ không rời công ty.
2.6 Đánh giá sư ảnh hưởng của mức lương
# draw bar chart
salary_level = ['High', 'Low', 'Medium']
fig = go.Figure(data=[
go.Bar(name='Stay', x=salary_level, y=df_salary[0], text=df_salary[0], textposition='auto'),
go.Bar(name='Left', x=salary_level, y=df_salary[1], text=df_salary[1], textposition='auto'),
])
fig.update_layout(barmode='group',
title="Statistic salary of employees",
xaxis_title="Salary Level",
yaxis_title="Number of employees",
legend_title="Employee Type")
fig.show()
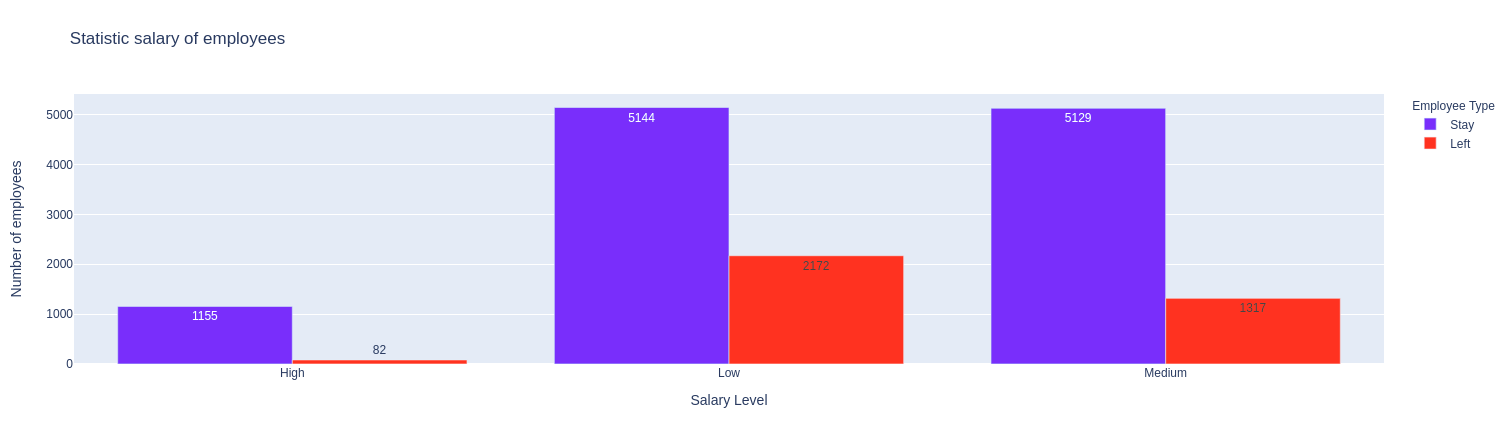
Nhận xét:
- Những người có mức lương cao thì ít nghỉ việc hơn.
- Những người có mức lương thấp hoặc trung bình rất dễ nghỉ việc.
Điều này chứng tỏ lương vẫn là yếu tố quan trọng để giữ chân nhân viên. :D
2.7 Đánh giá sự ảnh hưởng của việc thăng tiến trong vòng 5 năm
# draw bar chart
fig = go.Figure(data=[
go.Bar(name='Stay', x=df_pl5.index, y=df_pl5[0], text=df_pl5[0], textposition='auto'),
go.Bar(name='Left', x=df_pl5.index, y=df_pl5[1], text=df_pl5[1], textposition='auto'),
])
fig.update_layout(barmode='group',
title="Statistic promotion last 5 years of employees",
xaxis_title="Promotion last 5 years",
yaxis_title="Number of employees",
legend_title="Employee Type")
fig.show()
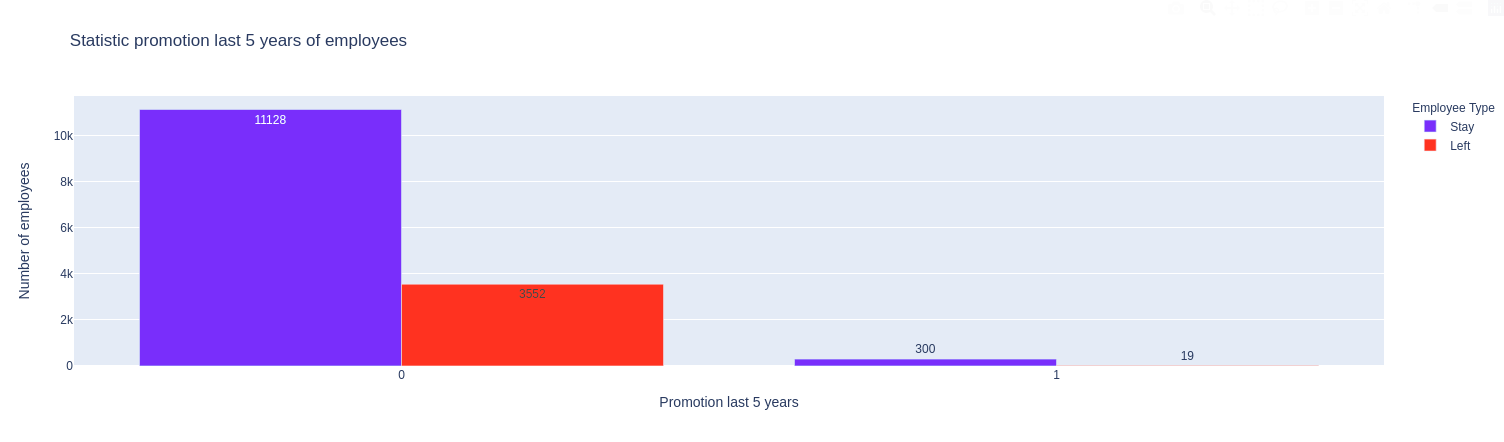
Nhận xét:
- Sau 5 năm làm việc, nếu không có sự thăng tiến nào thì rất nhiều nhân viên sẽ nghỉ việc.
- Ngược lại, nếu có sự phát triển về chức vụ sau 5 năm thì số người nghỉ việc sẽ ít hơn.
2.8 Đánh giá sự ảnh hưởng của sự cố trong công việc
fig = go.Figure(data=[
go.Bar(name='Stay', x=df_wa.index, y=df_wa[0], text=df_wa[0], textposition='auto'),
go.Bar(name='Left', x=df_wa.index, y=df_wa[1], text=df_wa[1], textposition='auto'),
])
# Change the bar mode
fig.update_layout(barmode='group',
title="Statistic working accident of employees",
xaxis_title="Woking Accident",
yaxis_title="Number of employees",
legend_title="Employee Type")
fig.show()
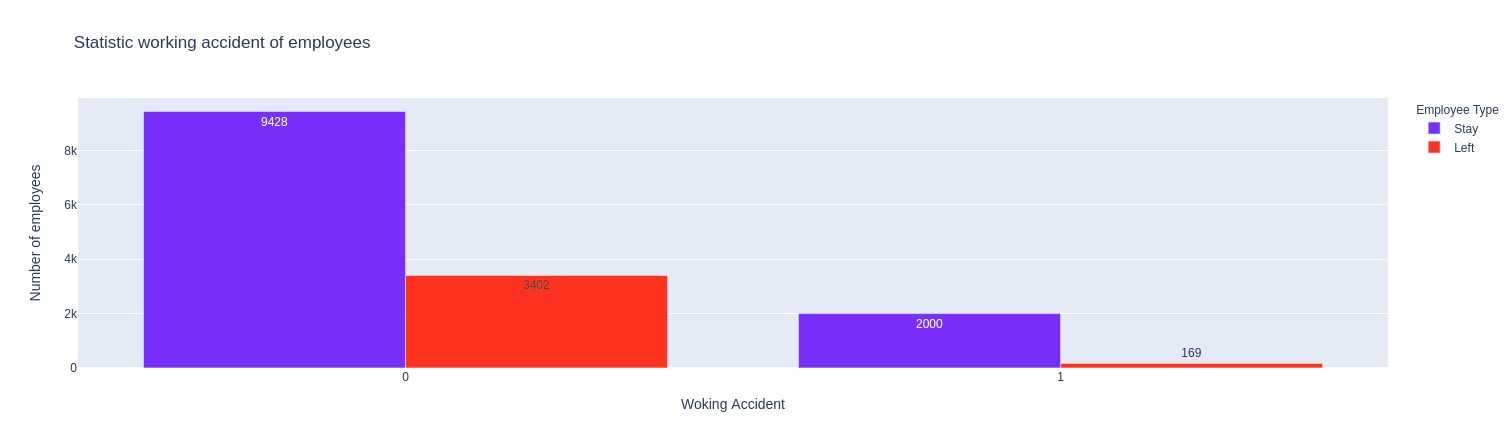
Nhận xét:
- Những người gặp sự cố nghỉ việc ít hơn những người không gặp sự cố.
Điều này khiến ta có vẻ hơi ngạc nhiên một chút, nhưng nếu phân tích kỹ càng hơn thì có thể sự cố trong công việc không phải lúc nào cũng ảnh hưởng tiêu cực. Nó có thể khiến cho công việc bớt nhàm chán, đơn điệu hơn. Vì thế mà dẫn đến kết quả nêu trên.
2.9 Đánh giá sự ảnh hưởng của mức độ thỏa mãn
# create dataframe with satisfaction level and left information
df_sl = df_data[['satisfaction_level', 'left']]
# draw violin chart
fig = px.violin(
df_sl,
y='satisfaction_level',
color='left',
points='all',
box=True,
labels={'satisfaction_level': 'Satisfaction Level', 'left':'Left/Stay'},
title='Influence of sastisfaction level to left/stay company decision: 0 - Stay, 1 - Left')
fig.show()
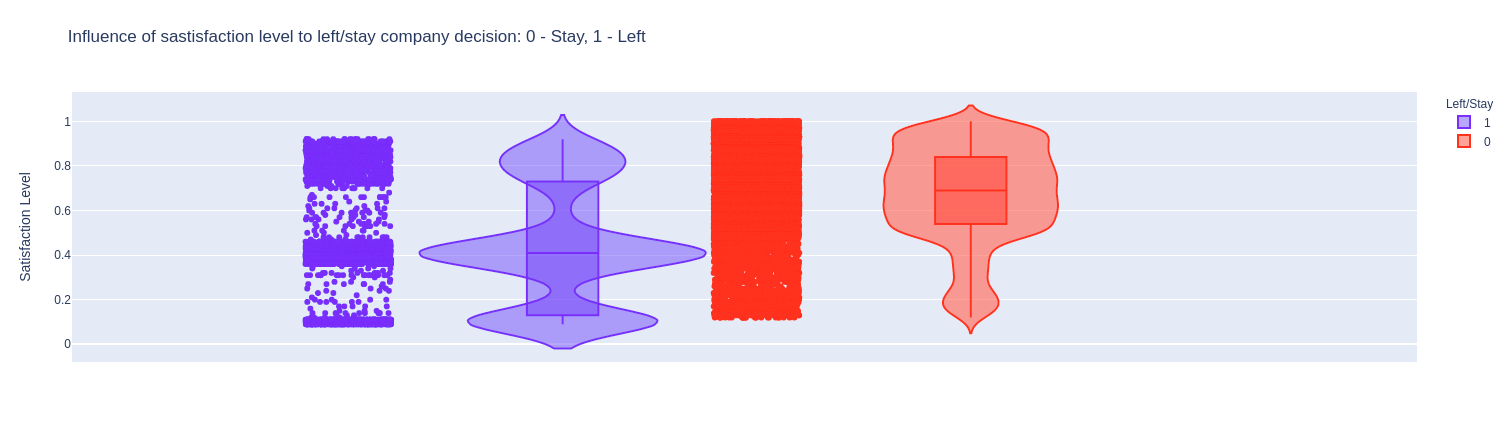
Nhận xét:
- Những người nghỉ việc là những người có mức độ thỏa mãn nằm trong các khoảng: < 0.2, 0.3-0.5, và 0.6-0.8.
- Với mức độ thoả mãn < 0.2 thì đa số nhân viên nghỉ việc.
Tại sao nhân viên có mức độ thoả mãn cao lại nghỉ việc? Thông thường thì đó sẽ phải là nhóm người gắn bó lâu nhất chứ nhỉ? Ta tiếp tục phân tích sâu hơn.
2.10 Phân nhóm nhân viên theo mức độ thỏa mãn và kết quả checkpoint
a, Đối với các nhân viên nghỉ việc
# draw scatter chart with satisfaction level and last evaluation information of people who leave company
fig = px.scatter(
df_data,
x=df_data['satisfaction_level'][df_data['left'] == 1],
y=df_data['last_evaluation'][df_data['left'] == 1],
width=1000,
height=800,
title='Employees who left',
labels={'x':'Satisfaction level', 'y':'Last Evaluation'}
)
fig.show()
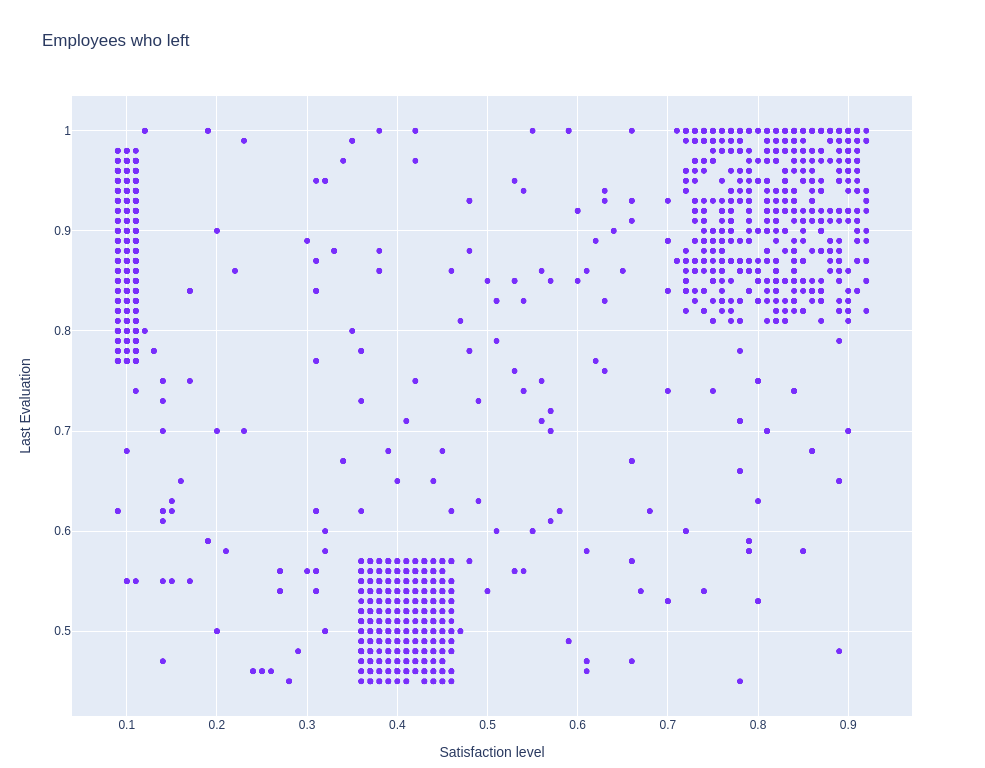
Nhận xét: Quan sát ta thấy, dựa theo mức độ thỏa mãn và kết quả checkpoint thì các nhân viên có thể phân chia các nhân viên nghỉ việc vào một trong 3 nhóm:
- Nhóm 1: Những người được đánh giá cao nhưng lại có mức độ thỏa mãn thấp. Đây có lẽ là những người giỏi trong công ty, họ làm được việc nhưng không cảm thấy hài lòng với công việc hiện tại nên nghỉ việc. Công ty nên tập trung vào nhóm đối tượng này.
- Nhóm 2: Những người bị đánh giá thấp, và bản thân họ cũng cảm thấy không vui khi làm việc tại công ty. Đối với những nhân viên thuộc nhóm này thì họ có nghỉ việc chắc cũng không phải là vấn đề quá lớn.
- Nhóm 3: Những người được đánh giá cao, và lại cũng đang cảm thấy rất thỏa mãn. Nhưng họ cũng nghỉ việc? Tại sao? Nhóm này đang chiếm số lượng nhân viên khá lớn. Phải chăng là do họ tìm được một cơ hội mới tốt hơn hẳn so với công ty hiện tại?
Ta thử áp dụng thuật toán phân cụm Kmeans với số cụm là 3 lên các nhân viên này xem sao:
# create dataframe with satisfaction level and last evaluation information
df_kmeans = df_data[df_data.left == 1].drop(['number_project',
'average_montly_hours', 'time_spend_company', 'Work_accident',
'left', 'promotion_last_5years', 'Department', 'salary'], axis=1)
# cluster people who leave company base on satisfaction level and last evaluation information
kmeans = KMeans(n_clusters=3, random_state=10).fit(df_kmeans)
# print(kmeans.cluster_centers_)
# print(kmeans.labels_)
# add cluster ID into original dataset
df_left = df_data[df_data.left == 1]
df_left['label'] = kmeans.labels_
df_left['label'] = df_left['label'].map({0:'Group 2', 1:'Group 3', 2:'Group 1'})
Kết quả:
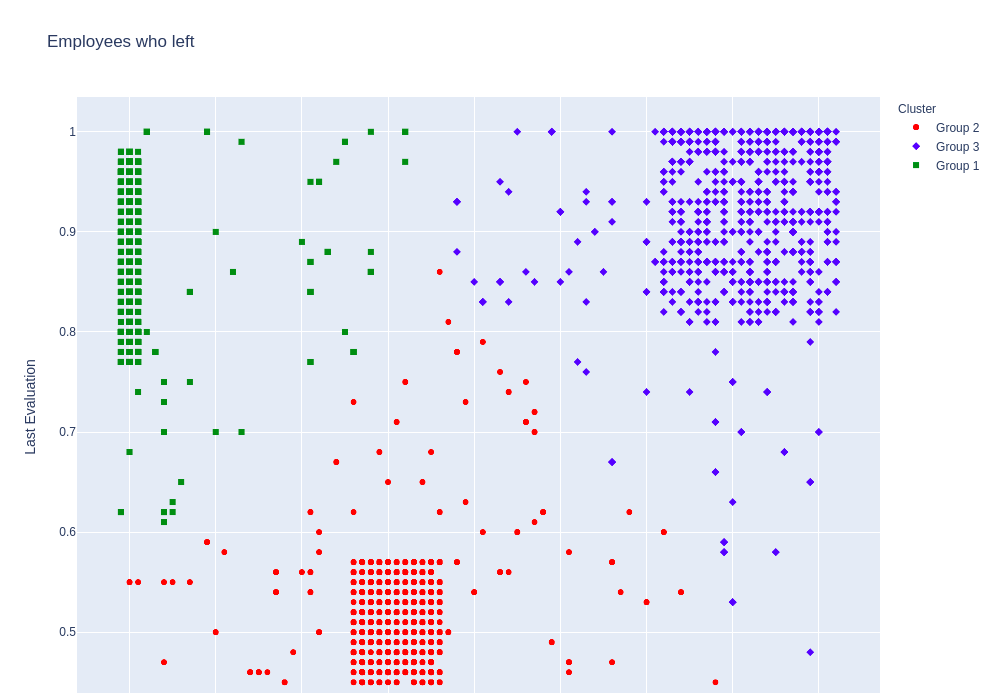
Lúc này 3 nhóm 1,2,3 đã trở nên rõ ràng hơn.
Tiếp tục xem xét số giờ làm việc trung bình trong tháng của các nhóm này:
# draw displot chart
group1_month_hour = df_left[df_left.label == 'Group 1'].average_montly_hours
group2_match_month_hour = df_left[df_left.label == 'Group 2'].average_montly_hours
group3_month_hour = df_left[df_left.label == 'Group 3'].average_montly_hours
hist_data = [group1_month_hour, group2_match_month_hour, group3_month_hour]
group_labels = ['Group 1', 'Group 2', 'Group 3']
fig = ff.create_distplot(hist_data, group_labels, bin_size=2.0, show_curve=True, show_hist=True)
fig.update_layout(title_text='Leavers: Hours per month distribution')
fig.show()
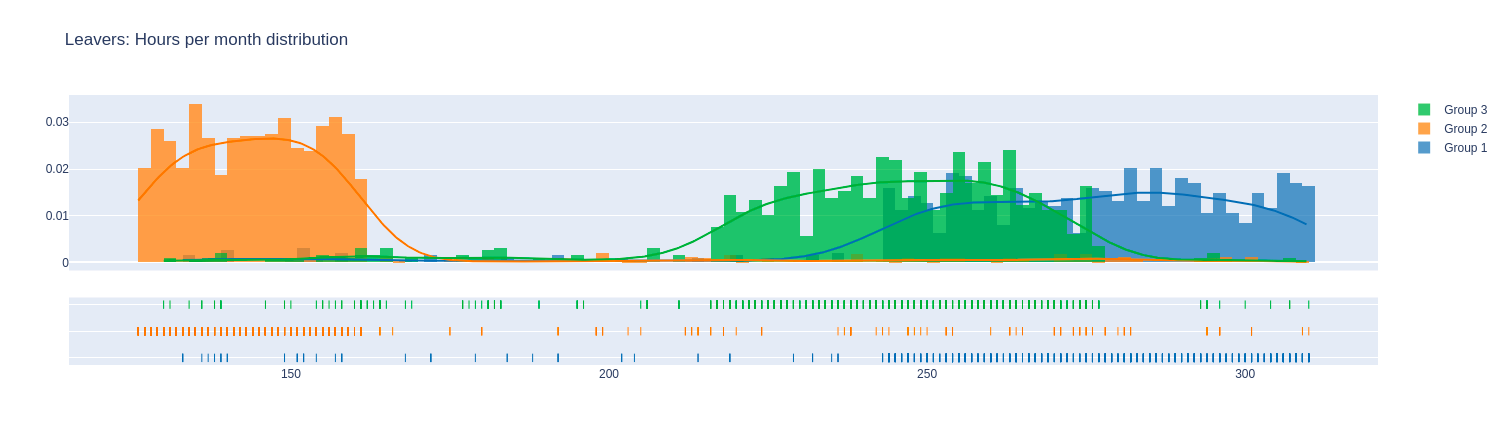
Nhận xét:
- Nhóm 1 là nhóm có số giờ làm việc trung bình trong tháng cao nhất. Tiếp đến là nhóm 3, và thấp nhất là nhóm 2.
Có lẽ nguyên nhân khiến cho nhóm 1 không được thỏa mãn cho lắm là vì họ phải OT quá nhiều. Nhóm 2 làm việc lười nhất, nên hiệu quả không cao là điều dễ hiểu. Còn nhóm 3, họ không phải OT nhiều nên mức độ thoả mãn cao, và củng cố thêm giả thuyết là họ tìm được cơ hội mới tốt hơn ở cty hiện tại nên họ nghỉ việc.
Đối với công ty, nên tập trung vào nhóm 2 nhiều hơn, quan tâm đến họ hơn, làm cho họ thỏa mãn hơn thì chắc chắn hiệu quả công việc của họ sẽ cao hơn. Còn lý do họ tìm được cơ hội mới tốt hơn, được công ty khác offer lương cao hơn, … thì cũng rất khó để có thể giữ chân họ. :D
b, Đối với các nhân viên không nghỉ việc
# draw scatter chart with satisfaction level and last evaluation information of people who stay company
fig = px.scatter(
df_data,
x=df_data['satisfaction_level'][df_data['left'] == 0],
y=df_data['last_evaluation'][df_data['left'] == 0],
width=1000,
height=800,
title='Employees who stay',
labels={'x':'Satisfaction level', 'y':'Last Evaluation'}
)
fig.show()
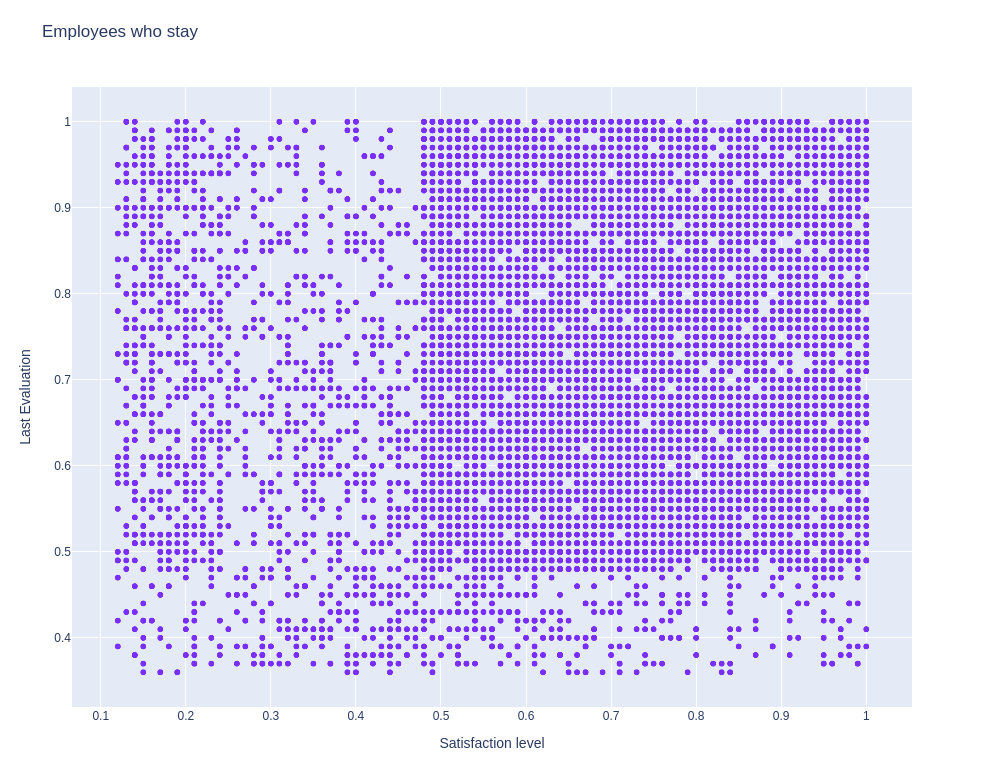
Các nhân viên này không có sự phân nhóm rõ rệt như trên nhưng nói chung vẫn tập trung khá nhiều vào vùng mà mức độ thỏa mãn, và điểm đánh giá cao. Chứng tỏ rằng, ko phải tất cả những nhân viên nhóm 3 bên trên đều nghỉ việc.
3. Kết luận
Như vậy là chúng ta đã cùng nhau phân tích khá chi tiết bộ dữ liệu khảo sát nhân viên. Các phân tích đều xoay quanh vấn đề tìm ra câu trả lời cho câu hỏi, tại sao nhân viên lại nghỉ việc?
Tóm tắt lại một số kết luận như sau:
- Những người mới vào công ty hoặc những người làm từ 6 năm trở lên rất ít nghỉ việc. Nếu công ty có thể giữ chân được nhân viên làm việc được 6 năm thì gần như chắc chắn họ sẽ còn gắn bó lâu dài hơn.
- Nhân viên phải OT quá nhiều, hoặc công việc quá nhàn nhã thì họ cũng dễ nghỉ việc.
- HR là bộ phận có tỉ lệ nghỉ viêc cao nhất, còn thấp nhất là các cán bộ quản lý.
- Những nhân viên bị đánh giá thấp sẽ có khả năng nghỉ việc cao hơn.
- Mức lương càng cao thì càng ít nghỉ việc.
- Sau 5 năm, nếu nhân viên không có sự thăng tiến thì họ cũng nghỉ việc.
- Công việc quá nhàm chán cũng làm cho tỉ lệ nghỉ việc tăng cao.
- Cần tập trung vào nhóm nhân viên được đánh giá cao, nhưng họ lại đang không thỏa mãn với công việc.
Mình hi vọng là đọc đến đây, bạn đã phân nào có được câu trả lời cho mình.
Trong phần 2, mình sẽ hướng dẫn các bạn xây dựng mô hình ML dự đoán khả năng nghỉ việc của nhân viên, độ chính xác lên đến hơn 99%. Mời các bạn đón đọc vào tuần tiếp theo!
Toàn bộ code của bài này, các bạn có thể tham khảo tại đây.