XGBoost - Bài 1: Toàn cảnh về Ensemble Learning - Phần 1
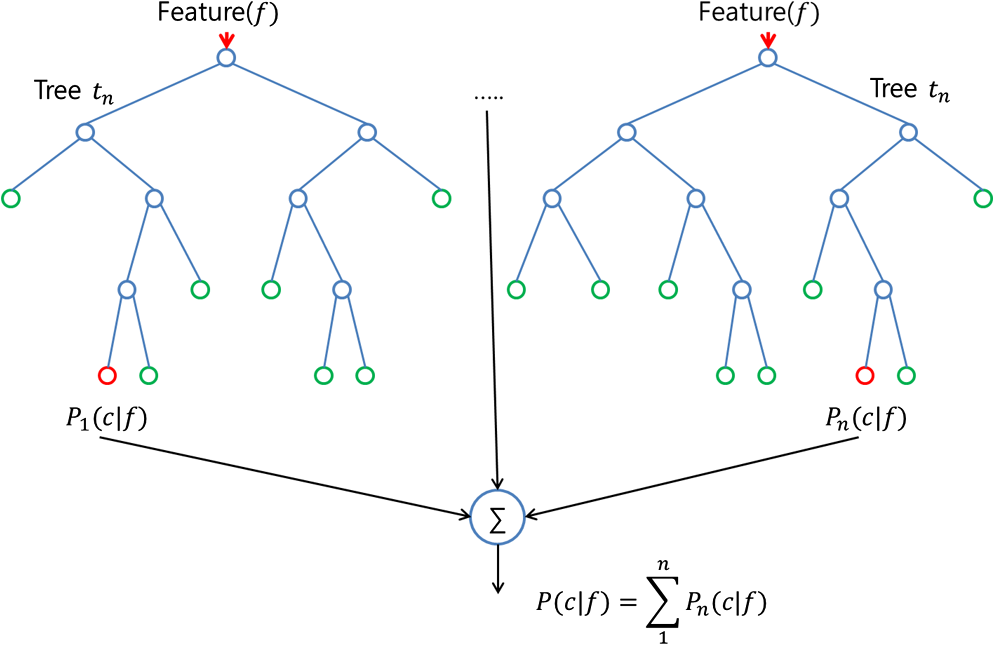
1. Giới thiệu về Ensemble Learning
Giả sử chúng ta có một bài toán phân loại sản phẩm sử dụng ML. Team của bạn chia thành 3 nhóm, mỗi nhóm sử dụng một thuật toán khác nhau và đánh giá độ chính xác trên tập validation set:
- Nhóm 1: Sử dụng thuật toán
Linear Regression. - Nhóm 2: Sử dụng thuật toán
k-Nearest Neighbour. - Nhóm 3: Sử dụng thuật toán
Decision Tree. Độ chính xác của mỗi nhóm lần lượt là 70%, 67% và 76%. Điều này hoàn toàn dễ hiểu bởi vì 3 models làm việc theo những các khác nhau. Ví dụ,Linear Regressioncố gắng tìm ra mối quan hệ tuyến tính giữa các điểm dữ liệu, trong khiDecision Treethì lại dựa vào mỗi quan hệ phi tuyến để liên kết dữ liệu.
Có cách nào kết hợp kết quả cả 3 models để tạo ra kết quả cuối cùng hay không?
Câu hỏi này là tiền đề cho một phương pháp, một họ các thuật toán hoạt động rất hiệu quả trong các bài toán ML. Đó là Ensemble Learning hay Ensemble Models.
Hình dưới đây thể hiện bức tranh tổng quát về Ensemble Learning.
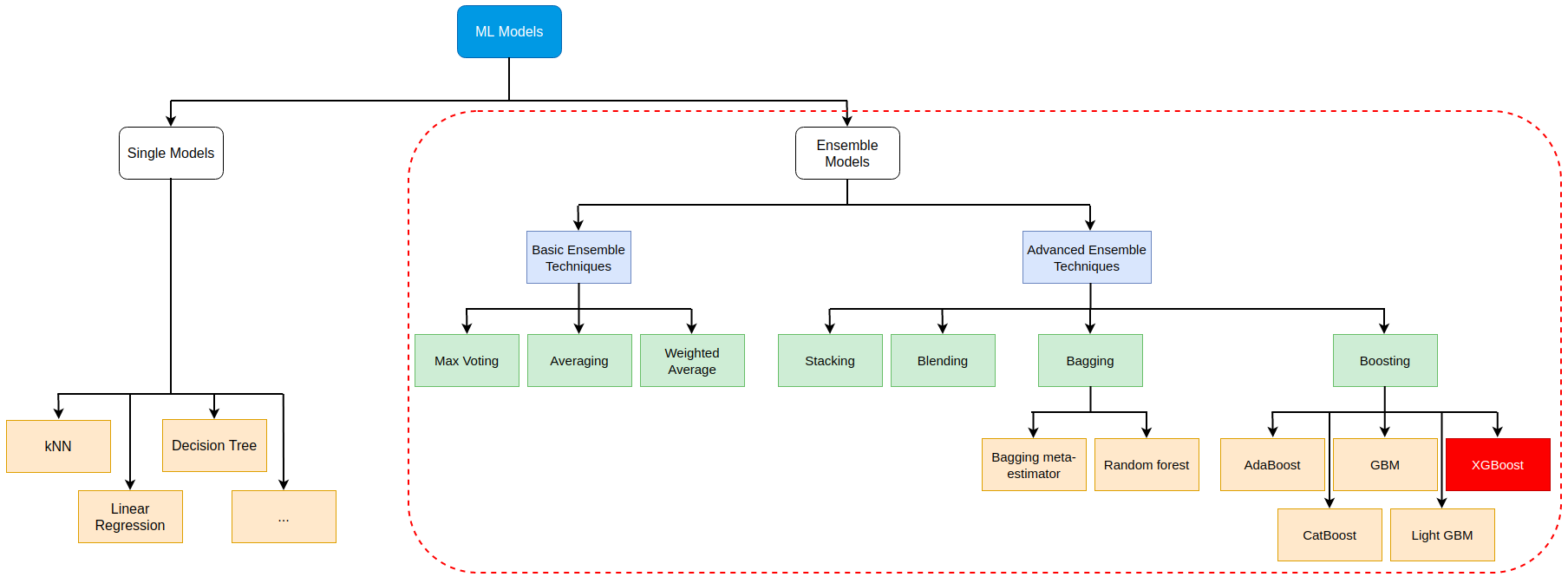
2. Basic Ensemble Techniques
Ở mức độ cơ bản, có 3 kỹ thuật là:
- Max Voting
- Averaging
- Weighted Averaging Mặc dù đơn giản nhưng những kỹ thuật này lại tỏ ra hiệu quả trong một số trường hợp nhất định. Hãy cùng tìm hiểu kỹ hơn về chúng.
2.1 Max Voting
Kỹ thuật này hay được sử dụng cho bài toán phân lớp, ở đó, nhiều models được sử dụng để dự đoán cho mỗi mẫu dữ liệu. Kết quả dự đoán của mỗi model được xem như là một vote. Cái nào có số vote cao nhất thì sẽ là kết quả dự đoán cuối cùng. Nói cách khác, đây là kiểu bầu chọn theo số đông, được áp dụng rất nhiều trong cuộc sống, chính trị, …
Lấy ví dụ, đợt vừa rồi, công ty của bạn tổ chức khám sức khỏe cho nhân viên tại bệnh viện X. Sau khi khám xong, phòng tổ chức nhân sự (TCNS) lấy ý kiến mọi người về chất lượng khám bệnh để xem năm sau có tiếp tục khám ở bênh viên X đó nữa không. Bảng dưới là ý kiến của 5 người được chọn ngẫu nhiên trong số toàn bộ nhân viên.
| Người 1 | Người 2 | Người 3 | Người 4 | Người 5 |
|---|---|---|---|---|
| Có | Không | Không | Có | Có |
Có 3 ý kiến muốn tiêp tục khám ở bệnh viện X vào năm sau, và 2 ý kiến muốn đổi bênh viện khác. Căn cứ theo max voting thì phòng TCNS sẽ tiếp tục chọn bệnh viên Xlà nơi khám bệnh cho nhân viên cho năm tiếp theo.
Code minh họa:
x_train, y_train, x_test, y_test = get_data()
model_1 = DecisionTreeClassifier()
model_2 = KNeighborsClassifier()
model_3= LogisticRegression()
model_1.fit(x_train,y_train)
model_2.fit(x_train,y_train)
model_3.fit(x_train,y_train)
pred_1=model_1.predict(x_test)
pred_2=model_2.predict(x_test)
pred_3=model_3.predict(x_test)
final_pred = np.array([])
for i in range(0,len(x_test)):
final_pred = np.append(final_pred, mode([pred_1[i], pred_2[i], pred_3[i]]))
Thư viện scikit-learn có module VotingClassifier giúp chúng ta đơn giản hóa việc này:
from sklearn.ensemble import VotingClassifier
x_train, y_train, x_test, y_test = get_data()
model_1 = LogisticRegression(random_state=1)
model_2 = DecisionTreeClassifier(random_state=1)
model = VotingClassifier(estimators=[('lr', model_1), ('dt', model_2)], voting='hard')
model.fit(x_train,y_train)
model.score(x_test,y_test)
2.2 Averaging
Tương tự như kỹ thuật Voting, Averaging cũng sử dụng kết quả dự đoán của nhiều models. Tuy nhiên, ở bước quyết định kết quả cuối cùng, giá trị trung bình của tất cả kêt quả của các models được lựa chọn.

Tiếp tục với ví dụ ở trên, một đề nghị khác của phòng TCNS là yêu cầu nhân viên chấm điểm chất lượng khám bệnh của bênh viện X, theo thang điểm từ 1 đến 5.
Bảng kết quả trả lời của 5 người ngẫu nhiên:
| Người 1 | Người 2 | Người 3 | Người 4 | Người 5 |
|---|---|---|---|---|
| 2 | 4 | 3 | 5 | 4 |
Điểm đánh giá cuối cùng sẽ là: (2+4+3+5+4)/5 = 3.6
Code ví dụ:
x_train, y_train, x_test, y_test = get_data()
model_1 = tree.DecisionTreeClassifier()
model_2 = KNeighborsClassifier()
model_3 = LogisticRegression()
model_1.fit(x_train,y_train)
model_2.fit(x_train,y_train)
model_3.fit(x_train,y_train)
pred_1 = model1.predict_proba(x_test)
pred_2 = model2.predict_proba(x_test)
pred_3 = model3.predict_proba(x_test)
final_pred =(pred1+pred2+pred3)/3
2.3 Weighted Average
Đây là kỹ thuật mở rộng của averaging. Mỗi model được gắn kèm với một trọng số tỷ lệ với mức độ quan trọng của model đó. Kết quả cuối cùng là trung bình có trọng số của tất cả kết quả của các models.
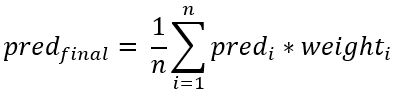
Vẫn với ví dụ ở mục 2.2, nhưng trong số 5 người được hỏi thì người thứ nhất có vợ là bác sĩ, người thứ 2 có mẹ là y tá, người thứ 3 có người yêu là sinh viên trường y. Vì vậy, ý kiến của 3 người này rõ ràng có giá trị hơn so với 2 người còn lại. Ta đánh trọng số cho mỗi người như bảng dưới (hàng thứ 2 là trọng số, hàng thứ 3 là điểm đánh giá):
| Người 1 | Người 2 | Người 3 | Người 4 | Người 5 |
|---|---|---|---|---|
| 1 | 0.8 | 0.5 | 0.3 | 0.3 |
| 2 | 4 | 3 | 5 | 4 |
Điểm đánh giá cuối cùng sẽ là: (21 + 40.8 + 30.5 + 50.3 + 4*0.3)/5 = 1.88
Code minh họa:
x_train, y_train, x_test, y_test = get_data()
model_1 = DecisionTreeClassifier()
model_2 = KNeighborsClassifier()
model_3 = LogisticRegression()
model_1.fit(x_train,y_train)
model_2.fit(x_train,y_train)
model_3.fit(x_train,y_train)
pred_1 = model1.predict_proba(x_test)
pred_2 = model2.predict_proba(x_test)
pred_3 = model3.predict_proba(x_test)
final_pred=(pred_1*0.3 + pred_2*0.3 + pred_3*0.4)
3. Advanced Ensemble techniques
Đã có basic thì chắc chắn phải có advanced, phải không mọi người. :D
Có 4 kỹ thuật của Ensemble Learning được xếp vào nhóm advanced:
- Stacking
- Blending
- Bagging
- Boosting
Chúng ta tiếp tục đi qua lần lượt từng kỹ thuật này:
3.1 Stacking
Hãy xem các bước thực hiện của kỹ thuật này:
- Bước 1: Train model A (base model) theo kiểu
cross-validationvới k=10. - Bước 2: Tiếp tuc train model A trên toàn bộ
train set. - Bước 3: Sử dụng model A để dự đoán trên
test set. - Bước 4: Lặp lại bước 1,2,3 cho các
base modelkhác. - Bước 5:
- Kết quả dự đoán trên
train setcủa cácbase modelsđược sử dụng như làinput features(ensemble train set) để trainstacking model. - Kết quả dự đoán trên
test setcủa cácbase modelsđược sử dụng như làtest set(ensemble test set) củastacking model.
- Kết quả dự đoán trên
- Bước 6: Train và đánh giá
stacking modelsử dụngensemble train setvàensemble test set.
Code minh họa ý tưởng:
# We first define a function to make predictions on n-folds of train and test dataset. This function returns the predictions for train and test for each model.
def Stacking(model,train,y,test,n_fold):
folds=StratifiedKFold(n_splits=n_fold,random_state=1)
test_pred = np.empty((test.shape[0],1),float)
train_pred = np.empty((0,1),float)
for train_indices,val_indices in folds.split(train,y.values):
x_train,x_val = train.iloc[train_indices],train.iloc[val_indices]
y_train,y_val = y.iloc[train_indices],y.iloc[val_indices]
model.fit(X=x_train,y=y_train)
train_pred = np.append(train_pred,model.predict(x_val))
test_pred = np.append(test_pred,model.predict(test))
return test_pred.reshape(-1,1),train_pred
# Now we’ll create two base models – decision tree and knn.
model_1 = DecisionTreeClassifier(random_state=1)
test_pred_1 ,train_pred_1 = Stacking(model=model_1, n_fold=10, train=x_train, test=x_test, y=y_train)
train_pred_1 = pd.DataFrame(train_pred_1)
test_pred_1 = pd.DataFrame(test_pred_1)
model_2 = KNeighborsClassifier()
test_pred_2, train_pred_2 = Stacking(model=model_2, n_fold=10, train=x_train,test=x_test, y=y_train)
train_pred_2 = pd.DataFrame(train_pred_2)
test_pred_2 = pd.DataFrame(test_pred_2)
# Create a final model, logistic regression, on the predictions of the decision tree and knn models.
df = pd.concat([train_pred_1, train_pred_2], axis=1)
df_test = pd.concat([test_pred_1, test_pred_2], axis=1)
model = LogisticRegression(random_state=1)
model.fit(df,y_train)
model.score(df_test, y_test)
Đoạn code trên chỉ minh họa stack model với 2 levels. Decision Tree và kNN là level 0, còn Logistic Regression là level 1. Bạn hoàn toàn có thể thử nghiệm với nhiều levels hơn.
3.2 Blending
Các bước thực hiện phương pháp này như sau:
- Buớc 1: Chia dataset thành
train set,validation setvàtest set. - Bước 2:
Base modelđược train trêntrain set. - Bước 3: Sử dụng
base modelđể dự đoán trênvalidation setvàtest set. - Bước 4: Lặp lại bước 2,3 cho các
base modelskhác. - Bước 5:
Validation setvà các kết quả dự đoán trênvalidation setcủa cácbase modelsđược sử dụng như làinput features(ensemble train set) củablending model.Test setvà các kết quả dự đoán trêntest setcủa cácbase modelsđược sử dụng như làtest set(ensemble test set) củablending model.
- Bước 6: Train và đánh giá
blending modelsử dụngensemble train setvàensemble test set.
Code minh họa ý tưởng:
# build two models, decision tree and knn, on the train set in order to make predictions on the validation set.
model_1 = DecisionTreeClassifier()
model_1.fit(x_train, y_train)
val_pred_1 = model1.predict(x_val)
test_pred_1 = model1.predict(x_test)
val_pred_1 = pd.DataFrame(val_pred_1)
test_pred_1 = pd.DataFrame(test_pred_1)
model_2 = KNeighborsClassifier()
model_2.fit(x_train, y_train)
val_pred_2 = model_2.predict(x_val)
test_pred_2 = model2.predict(x_test)
val_pred_2 = pd.DataFrame(val_pred_2)
test_pred_2 = pd.DataFrame(test_pred_2)
# Combining the meta-features and the validation set, a logistic regression model is built to make predictions on the test set.
df_val = pd.concat([x_val, val_pred_1,val_pred_2], axis=1)
df_test = pd.concat([x_test, test_pred1,test_pred_2], axis=1)
model = LogisticRegression()
model.fit(df_val, y_val)
model.score(df_test, y_test)
3.3 Bagging
Bagging (Bootstrap Aggregating) khác với hai kỹ thuật trên ở chỗ, nó sử dụng chung 1 thuật toán cho tất cả các base models. Tập dataset sẽ được chia thành các phần khác nhau (bags) và mỗi base model sẽ được train trên mỗi bag đó.
Các bước thực hiện của bagging như sau:
- Bước 1: Chia tập dữ liệu ban đầu thành nhiều phần khác nhau (
bags). - Bước 2: Tạo các
base models(weak learner) và train chúng trên các bags. Cácbase modelđược train song song và độc lập với nhau. - Bước 3: Kết quả dự đoán cuối cùng được quyết định bằng cách kết hợp kết quả từ các
base models.
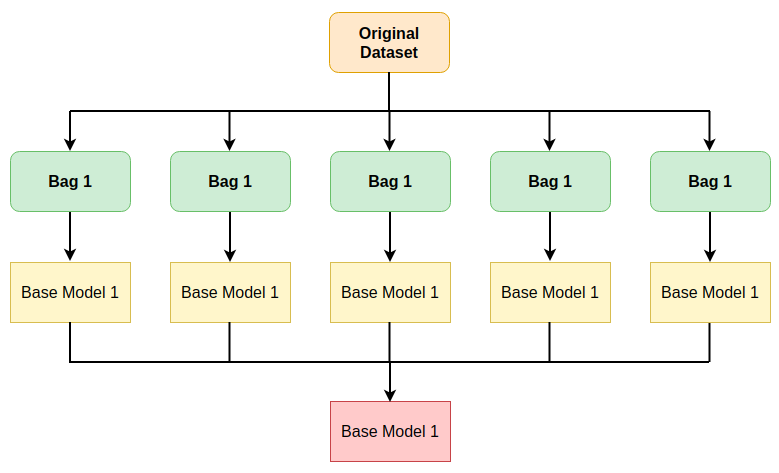
3.4 Boosting
Nếu như các base models được train độc lập với nhau trong phương pháp bagging, thì ở phương pháp boosting, chúng lại được train một cách tuần tự. Base model sau được train dựa theo kết quả của base model trước đó để cố gắng sửa những lỗi sai tồn tại ở model này.
Các bước tiến hành như sau:
- Bước 1: Tạo một tập dữ liệu con (tập A) từ tập dữ liệu ban đầu (tập D).
- Bước 2: Gán cho mỗi điểm dữ liệu trong tập A một trọng số w có giá trị giống nhau.
- Bước 3: Tạo một
base modelX và train trên tập A. - Bước 4: Sử dụng model X để dự đoán trên toàn bộ tập D.
- Bước 5: Tính toán sai số dự đoán dựa vào kết quả dự đoán và kết quả thực tế.
- Bước 6: Gán giá trị w cao hơn cho những điểm dữ liệu bị dự đoán sai.
- Bước 7: Lặp lại bước 1,2,3,4,5,6 đối với
base modelmới, Y. - Bước 8: Model cuối cùng (
boosting model) sẽ là trung bình có trọng số của tất cả cácbase models.
Mỗi base model được gọi là một weak learner. Chúng sẽ không hoạt động tốt trên toàn bộ tập D, nhưng khi kết hợp nhiều weak learners ta được một strong learner. Strong learner này chắc chắn sẽ hiệu quả trên tập D. Ta nói, các weak learners đã boost performance cho strong learner.
Bagging và Boosting là 2 kỹ thuật quan trọng, hiệu quả. Có một số thuật toán đã được phát triển dựa trên nền tảng của chúng. Đặc biệt là thuật toán XGBoost. Trong bài tiếp theo, chúng ta sẽ đi chi tiết hơn về các thuật toán này.
Mời các bạn đón đọc!
Toàn bộ source code của bài này các bạn có thể tham khảo trên github cá nhân của mình tại github.
Bài viết có tham khảo tại đây.