Tổng hợp các thuật toán Machine Learning
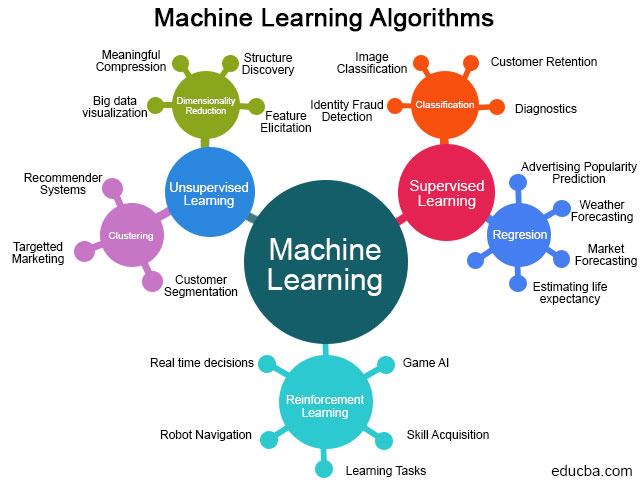
Bài viết này nhằm mục đích tổng hợp, tóm tắt lại các thuật toán của Machine Learning, giúp bạn đọc có cái nhìn toàn cảnh và hiểu rõ hơn về Deep Learning.
Các thuật toán ML, nhìn chung có thể phân loại theo một trong 2 cách:
- Theo cách thức “học” của thuật toán
- Theo cách thức làm việc của thuật toán
Cả 2 cách phân loại đều hợp lý, bạn có thể chọn tùy ý. Trong bài bài này, mình sẽ đi sâu hơn theo cách thứ 2. Cũng phải nói thêm rằng, cho dù phân loại theo cách nào thì cũng đều mang tính chất tương đối, vì một thuật toán có thể thuộc nhiều nhóm khác nhau, tùy thuộc vào dữ liệu đưa vào huấn luyện model.

1. Phân loại theo cách “học” (Learning Style)
1.1 Học có giám sát (Supervised Learning)
Trong cách học này, dữ liệu đưa vào huấn luyện model, gọi là input data, đi kèm với một nhãn đã biết trước (input data đã được dánh nhãn). Ví dụ như là spam/not-spam, giá cổ phiếu tại 1 thời điểm, …
Trong quá trình training, output của model được so sánh với nhãn. Nếu có sự sai khác, model sẽ cố gắng cập nhật các trọng số của nó để giảm sự sai khác đó đến một mức nào đó thỏa mãn yêu cầu bài toán.
Các vấn đề có thể giải quyết theo cách này: Phân lớn, hồi quy.
Một số thuật toán thuộc loại này: Logistic Regression, Backpropagation, …

1.2 Học không giám sát (Unsupervised Learning)
Input data không được đánh nhãn theo cách học này. Model được huấn luyện bằng cách giảm cấu trúc phức tạp của dữ liệu, tìm ra các đặc trưng, các mối liên hệ tương quan trong dữ liệu.
Các vấn đề có thể giải quyết theo cách này: phân cụm, giảm chiều dữ liệu.
Một số thuật toán thuộc loại này: Apriori, K-Means, …

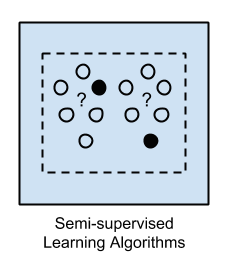
1.3 Học bán giám sát (Semi-supervised)
Input data bao gồm cả 2 loại: đã đánh nhãn và không đánh nhãn.
Model sẽ sử dụng kết hợp cả 2 cách học giám sát và không giám sát trong quá trình huấn luyện. Dựa vào kết quả dự đoán của model trên dữ liệu chưa đánh nhãn, nhà phát triển sẽ tốn ít công sức hơn trong việc đánh nhãn cho những dữ liệu đó. Độ chính xác của model sẽ được cải thiện dần dần khi có nhiều dữ liệu được đánh nhãn hơn.
Thực tế, tất cả các thuật toán đều có thể thuộc thể loại này vì không phải lúc nào cũng có đầy đủ dữ liệu được đánh nhãn ngay từ đầu.
2. Phân loại theo cách làm việc
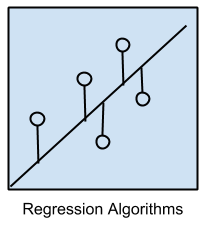
2.1 Regression Algorithms
Các thùât toán được xếp vào nhóm này khi nhãn của dữ liệu là các giá trị liên tục. Ví dụ: nhiệt độ, giá tiền, diện tích, …
Một số thuật toán:
- Ordinary Least Squares Regression (OLSR)
- Linear Regression
- Logistic Regression
- Stepwise Regression
- Multivariate Adaptive Regression Splines (MARS)
- Locally Estimated Scatterplot Smoothing (LOESS)
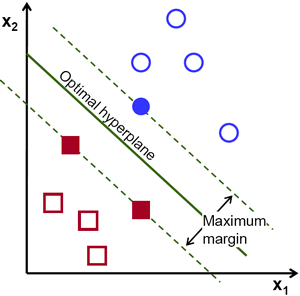
2.2 Classification Algorithms
Các thuật toán thụộc nhóm này khi nhãn của dữ liệu chỉ bao gồm một số lượng hữu hạn các giá trị. Ví dụ: Spam/not-spam, hình dạng (tròn, vuông, tam giác), …
Một số thuật toán:
- Linear Classifier
- Support Vector Machine (SVM)
- Kernel SVM
- Sparse Representation-based classification (SRC)
2.3 Instance-based Algorithms
Các thuật toán thuộc nhóm này không “học” gì từ dữ liệu. Khi nào cần dự đoán nhãn cho dữ liệu mới, chúng sẽ quét toàn bộ dữ liệu ban đầu và tính toán tương quan với dữ liệu mới để quyết định nhãn.
Một số thuật toán:
- k-Nearest Neighbor (kNN)
- Learning Vector Quantization (LVQ)
- Self-Organizing Map (SOM)
- Locally Weighted Learning (LWL)
2.4 Regularization Algorithms
Các thuật toán có thể được mở rộng theo cách “trừng phạt” model dựa trên độ phức tạp của chúng, làm cho model trở nên đơn giản hơn, kết quả là “học” tốt hơn.
Một số thuật toán:
- Ridge Regression
- Least Absolute Shrinkage and Selection Operator (LASSO)
- Elastic Net
- Least-Angle Regression (LARS)

2.5 Decision Tree
Đây là phương pháp xây dựng model dựa vào trực tiếp giá trị thực tế của input data. Tùy theo các điều kiện cụ thể áp dụng vào input data mà model sẽ đưa ra các quyết định khác nhau. Trong ML, các thuật toán thuộc nhóm này được sử dụng khá phổ biến.
Một số thuật toán: Classification and Regression Tree (CART)
- Iterative Dichotomiser 3 (ID3)
- C4.5 and C5.0 (different versions of a powerful approach)
- Chi-squared Automatic Interaction Detection (CHAID)
- Decision Stump
- M5
- Conditional Decision Trees

2.6 Bayesian Algorithms
Đây là họ các thụât toán áp dụng định luật Bayes trong xác suất thống kê.
Một số thuật toán:
- Naive Bayes
- Gaussian Naive Bayes
- Multinomial Naive Bayes
- Averaged One-Dependence Estimators (AODE)
- Bayesian Belief Network (BBN)
- Bayesian Network (BN)
2.7 Clustering Algorithms
Dựa trên số lượng cụm (nhóm, lớp) cho trước, các thuật toán clusering sẽ phân bổ các điểm dữ liệu về từng lớp, dựa trên sự tương quan giữa các điểm dữ liệu đó với nhau.
Một số thuật toán:
- k-Means
- k-Medians
- Expectation Maximisation (EM)
- Hierarchical Clustering

2.8 Association Rule Learning Algorithms
Các thuật toán này tập trung vào việc tìm ra các quy tắc kết hợp giữa các điểm dữ liệu để sinh ra dữ liệu mới, hoặc dữ liệu tồn tại trong tập ban đầu.
Một số thuật toán:
- Apriori algorithm
- Eclat algorithm

2.9 Artificial Neural Network Algorithms (ANN)
Được truyền cảm hứng từ cấu tạo não bộ của các loài động vật, các thuật toán này mô phỏng lại cách làm viêc của các bộ não đó. Chúng được cấu tạo gồm các layers và các nerurons liên kết với nhau.
Một số thuật toán:
- Perceptron
- Multilayer Perceptrons (MLP)
- Back-Propagation
- Stochastic Gradient Descent
- Hopfield Network
- Radial Basis Function Network (RBFN)
2.10 Deep Learning (DL) Algorithms
Các thuật toán DL là sự nâng cấp, mở rộng của thuật toán ANN. Chúng bao gồm các mạng ANN phức tạp hơn, giải quyết các bài toán với lượng dữ liệu lớn hơn.
Một số thuật toán:
- Convolutional Neural Network (CNN)
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory Networks (LSTMs)
- Stacked Auto-Encoders
- Deep Boltzmann Machine (DBM)
- Deep Belief Networks (DBN)
Chi tiết hơn về các thuật toán ở nhóm này, mình sẽ đề cập trong bài tiếp theo. Mời các bạn đón đọc.
2.11 Dimensionality Reduction Algorithms
Đôi khi dữ liệu quá phức tạp sẽ làm giảm khả năng học của các ML model. Các thuật toán này sẽ giúp giải quyết vấn đề này bằng cách giảm bớt số chiều của dữ liệu (giảm độ phức tạp của dữ liệu).
Một số thuật toán:
- Principal Component Analysis (PCA)
- Principal Component Regression (PCR)
- Partial Least Squares Regression (PLSR)
- Sammon Mapping
- Multidimensional Scaling (MDS)
- Projection Pursuit
- Linear Discriminant Analysis (LDA)
- Mixture Discriminant Analysis (MDA)
- Quadratic Discriminant Analysis (QDA)
- Flexible Discriminant Analysis (FDA)

2.12 Ensemble Algorithms
Ensemble là phương pháp sử dụng kết hợp nhiều thuật toán khác nhau để tạo thành một thuật toán mới. Mỗi cách kết hợp khác nhau sẽ cho ra các thuật toán khác nhau. Trong ML, các thuật toán thuộc nhóm này được sử dụng rất phổ biến, đạt hiệu quả rất cao.
Một số thuật toán:
- Boosting
- Bootstrapped Aggregation (Bagging)
- AdaBoost
- Weighted Average (Blending)
- Stacked Generalization (Stacking)
- Gradient Boosting Machines (GBM)
- Gradient Boosted Regression Trees (GBRT)
- Random Forest

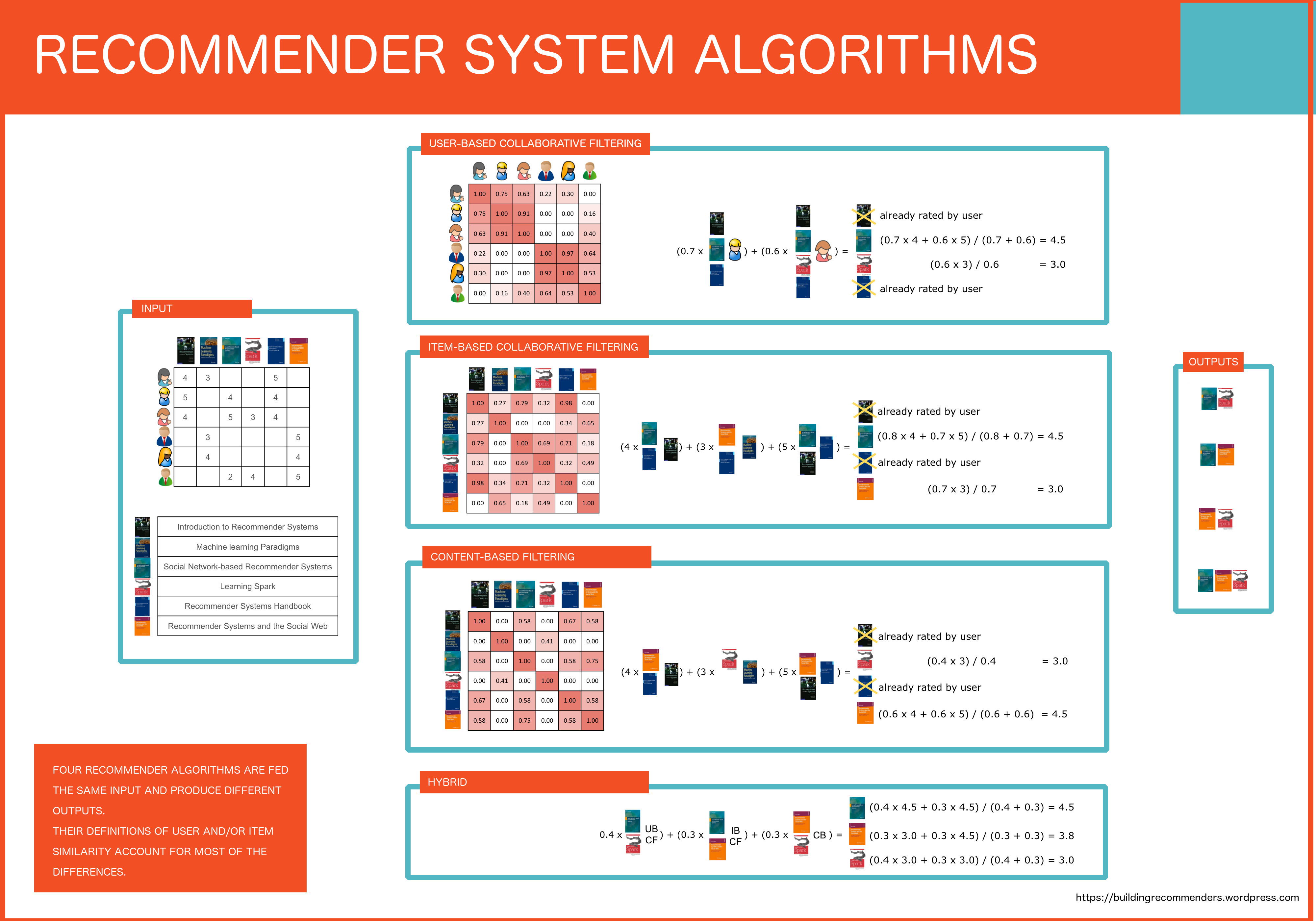
2.13 Recommendation System Algorithms
Đúng như tên gọi, đây là các thuật toán giải quyết bài toán khuyến nghị người dùng làm một việc gì đó bằng cách đưa cho họ những cái mà họ có thể quan tâm. Chúng thường được áp dụng trong các trang web thương mại điện tử, các ứng dụng xem phim trực tuyến, …
Một số thuật toán:
- Content based
- Collaborative filtering
2.14 Các thuật toán khác
Còn rất nhiều thuật toán chưa được liệt kê bên trên, đó là những thuật toán giải quyết các bài toán cụ thể. Có thể kể ra một số như sau:
- Feature selection algorithms
- Algorithm accuracy evaluation
- Performance measures
- Optimization algorithms
- …
Vậy là mình đã giới thiệu đến các bạn các thuật toán ML mà các bạn có thể gặp trong quá trình học ML. Hi vọng rằng các bạn đã có cái nhìn tổng quát về chúng, làm tiền đề để đi sâu hơn trong các bài toán ML về sau.
Trong các bài viết tiếp theo, mình sẽ tổng hợp lại các thuật toán Deep Learning, sau đó sẽ đi chi tiết vào một số thụât toán với các ứng dụng cụ thể. Mời các bạn đón đọc!
3. Tham khảo